 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe Jure: Iterative LLM Self-Refinement for Structured Extraction of Regulatory Rules
Apr 02, 2026Regulatory documents encode legally binding obligations that LLM-based systems must respect. Yet converting dense, hierarchically structured legal text into machine-readable rules remains a costly, expert-intensive process. We present De Jure, a fully automated, domain-agnostic pipeline for extracting structured regulatory rules from raw documents, requiring no human annotation, domain-specific prompting, or annotated gold data. De Jure operates through four sequential stages: normalization of source documents into structured Markdown; LLM-driven semantic decomposition into structured rule units; multi-criteria LLM-as-a-judge evaluation across 19 dimensions spanning metadata, definitions, and rule semantics; and iterative repair of low-scoring extractions within a bounded regeneration budget, where upstream components are repaired before rule units are evaluated. We evaluate De Jure across four models on three regulatory corpora spanning finance, healthcare, and AI governance. On the finance domain, De Jure yields consistent and monotonic improvement in extraction quality, reaching peak performance within three judge-guided iterations. De Jure generalizes effectively to healthcare and AI governance, maintaining high performance across both open- and closed-source models. In a downstream compliance question-answering evaluation via RAG, responses grounded in De Jure extracted rules are preferred over prior work in 73.8% of cases at single-rule retrieval depth, rising to 84.0% under broader retrieval, confirming that extraction fidelity translates directly into downstream utility. These results demonstrate that explicit, interpretable evaluation criteria can substitute for human annotation in complex regulatory domains, offering a scalable and auditable path toward regulation-grounded LLM alignment.
Dynamic Regret of Online Mirror Descent for Relatively Smooth Convex Cost Functions
Feb 25, 2022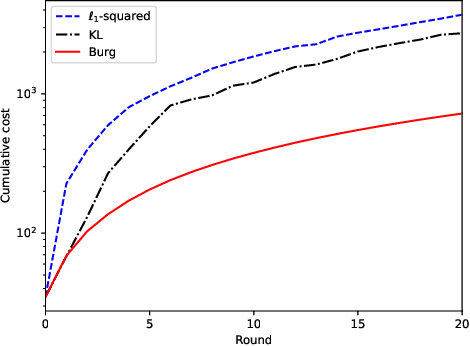
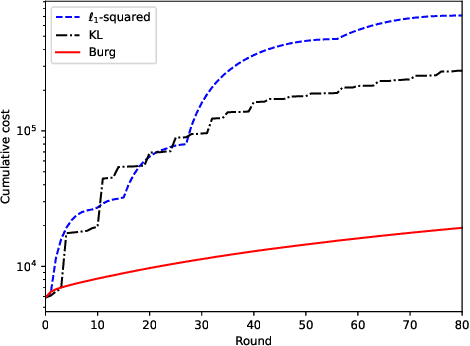
The performance of online convex optimization algorithms in a dynamic environment is often expressed in terms of the dynamic regret, which measures the decision maker's performance against a sequence of time-varying comparators. In the analysis of the dynamic regret, prior works often assume Lipschitz continuity or uniform smoothness of the cost functions. However, there are many important cost functions in practice that do not satisfy these conditions. In such cases, prior analyses are not applicable and fail to guarantee the optimization performance. In this letter, we show that it is possible to bound the dynamic regret, even when neither Lipschitz continuity nor uniform smoothness is present. We adopt the notion of relative smoothness with respect to some user-defined regularization function, which is a much milder requirement on the cost functions. We first show that under relative smoothness, the dynamic regret has an upper bound based on the path length and functional variation. We then show that with an additional condition of relatively strong convexity, the dynamic regret can be bounded by the path length and gradient variation. These regret bounds provide performance guarantees to a wide variety of online optimization problems that arise in different application domains. Finally, we present numerical experiments that demonstrate the advantage of adopting a regularization function under which the cost functions are relatively smooth.