 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Chain of Thought Fails in Clinical Text Understanding
Sep 26, 2025Large language models (LLMs) are increasingly being applied to clinical care, a domain where both accuracy and transparent reasoning are critical for safe and trustworthy deployment. Chain-of-thought (CoT) prompting, which elicits step-by-step reasoning, has demonstrated improvements in performance and interpretability across a wide range of tasks. However, its effectiveness in clinical contexts remains largely unexplored, particularly in the context of electronic health records (EHRs), the primary source of clinical documentation, which are often lengthy, fragmented, and noisy. In this work, we present the first large-scale systematic study of CoT for clinical text understanding. We assess 95 advanced LLMs on 87 real-world clinical text tasks, covering 9 languages and 8 task types. Contrary to prior findings in other domains, we observe that 86.3\% of models suffer consistent performance degradation in the CoT setting. More capable models remain relatively robust, while weaker ones suffer substantial declines. To better characterize these effects, we perform fine-grained analyses of reasoning length, medical concept alignment, and error profiles, leveraging both LLM-as-a-judge evaluation and clinical expert evaluation. Our results uncover systematic patterns in when and why CoT fails in clinical contexts, which highlight a critical paradox: CoT enhances interpretability but may undermine reliability in clinical text tasks. This work provides an empirical basis for clinical reasoning strategies of LLMs, highlighting the need for transparent and trustworthy approaches.
Towards Automated Anamnesis Summarization: BERT-based Models for Symptom Extraction
Nov 03, 2020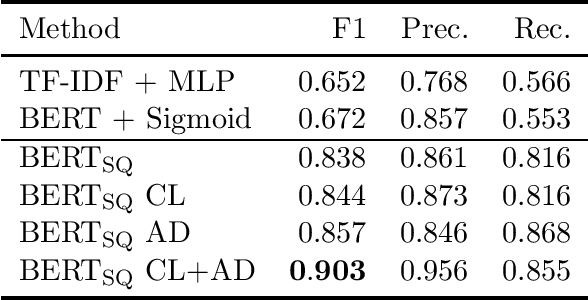
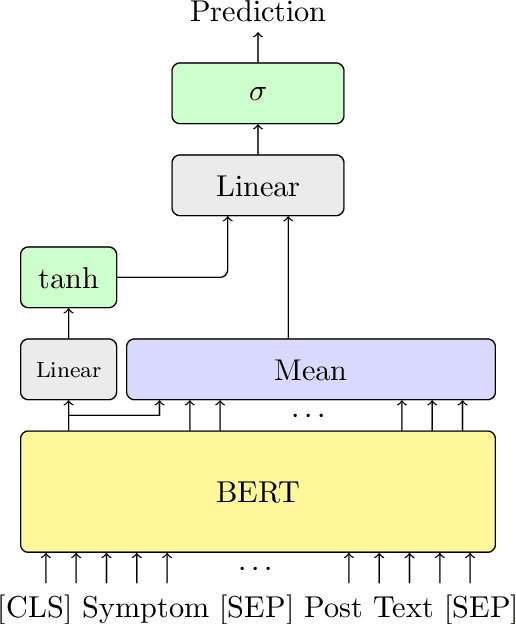
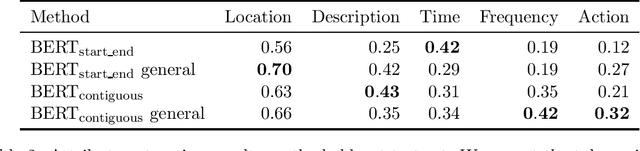
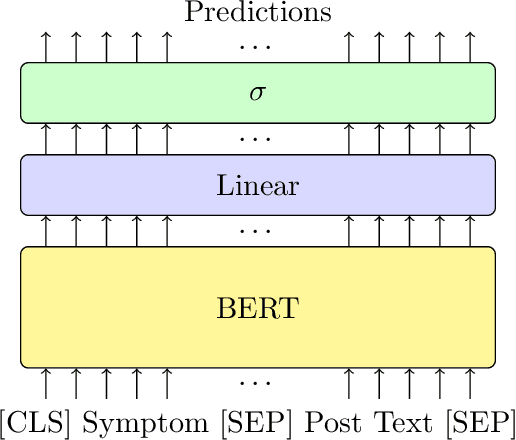
Professionals in modern healthcare systems are increasingly burdened by documentation workloads. Documentation of the initial patient anamnesis is particularly relevant, forming the basis of successful further diagnostic measures. However, manually prepared notes are inherently unstructured and often incomplete. In this paper, we investigate the potential of modern NLP techniques to support doctors in this matter. We present a dataset of German patient monologues, and formulate a well-defined information extraction task under the constraints of real-world utility and practicality. In addition, we propose BERT-based models in order to solve said task. We can demonstrate promising performance of the models in both symptom identification and symptom attribute extraction, significantly outperforming simpler baselines.