 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMA: Projected Microbatch Accumulation for Reference-Free Proximal Policy Updates
Jan 22, 2026This note introduces Projected Microbatch Accumulation (PROMA), a proximal policy method that modifies gradient accumulation across microbatches rather than relying on likelihood ratios relative to a reference policy. During accumulation, PROMA projects the partially accumulated gradient to be orthogonal to the sequence-wise gradients of the current microbatch. This projection is applied layer-wise during the backward pass, enabling efficient implementation. Empirically, PROMA achieves proximal updates without entropy collapse while providing tighter local KL control than GRPO.
Projected Microbatch Accumulation yields reference-free proximal policy updates for reinforcement learning
Jan 15, 2026This note introduces Projected Microbatch Accumulation (PROMA), a proximal policy update method for large language model fine-tuning. PROMA accumulates policy gradients across microbatches by projecting out sequence-wise gradient components before microbatch aggregation. The projection is applied layer-wise during the backward pass, enabling efficient implementation without additional forward or backward passes. Empirically, PROMA enforces tighter control of local KL divergence than GRPO, resulting in more stable policy learning. Unlike PPO and GRPO, PROMA achieves proximal updates without inducing entropy collapse and does not rely on a reference policy or likelihood-ratio clipping.
ISOPO: Proximal policy gradients without pi-old
Dec 30, 2025This note introduces Isometric Policy Optimization (ISOPO), an efficient method to approximate the natural policy gradient in a single gradient step. In comparison, existing proximal policy methods such as GRPO or CISPO use multiple gradient steps with variants of importance ratio clipping to approximate a natural gradient step relative to a reference policy. In its simplest form, ISOPO normalizes the log-probability gradient of each sequence in the Fisher metric before contracting with the advantages. Another variant of ISOPO transforms the microbatch advantages based on the neural tangent kernel in each layer. ISOPO applies this transformation layer-wise in a single backward pass and can be implemented with negligible computational overhead compared to vanilla REINFORCE.
A Kaczmarz-inspired approach to accelerate the optimization of neural network wavefunctions
Jan 18, 2024



Neural network wavefunctions optimized using the variational Monte Carlo method have been shown to produce highly accurate results for the electronic structure of atoms and small molecules, but the high cost of optimizing such wavefunctions prevents their application to larger systems. We propose the Subsampled Projected-Increment Natural Gradient Descent (SPRING) optimizer to reduce this bottleneck. SPRING combines ideas from the recently introduced minimum-step stochastic reconfiguration optimizer (MinSR) and the classical randomized Kaczmarz method for solving linear least-squares problems. We demonstrate that SPRING outperforms both MinSR and the popular Kronecker-Factored Approximate Curvature method (KFAC) across a number of small atoms and molecules, given that the learning rates of all methods are optimally tuned. For example, on the oxygen atom, SPRING attains chemical accuracy after forty thousand training iterations, whereas both MinSR and KFAC fail to do so even after one hundred thousand iterations.
Inventing painting styles through natural inspiration
May 19, 2023We propose two procedures to create painting styles using models trained only on natural images, providing objective proof that the model is not plagiarizing human art styles. In the first procedure we use the inductive bias from the artistic medium to achieve creative expression. Abstraction is achieved by using a reconstruction loss. The second procedure uses an additional natural image as inspiration to create a new style. These two procedures make it possible to invent new painting styles with no artistic training data. We believe that our approach can help pave the way for the ethical employment of generative AI in art, without infringing upon the originality of human creators.
Convergence of stochastic gradient descent on parameterized sphere with applications to variational Monte Carlo simulation
Mar 24, 2023



We analyze stochastic gradient descent (SGD) type algorithms on a high-dimensional sphere which is parameterized by a neural network up to a normalization constant. We provide a new algorithm for the setting of supervised learning and show its convergence both theoretically and numerically. We also provide the first proof of convergence for the unsupervised setting, which corresponds to the widely used variational Monte Carlo (VMC) method in quantum physics.
Anti-symmetric Barron functions and their approximation with sums of determinants
Mar 22, 2023A fundamental problem in quantum physics is to encode functions that are completely anti-symmetric under permutations of identical particles. The Barron space consists of high-dimensional functions that can be parameterized by infinite neural networks with one hidden layer. By explicitly encoding the anti-symmetric structure, we prove that the anti-symmetric functions which belong to the Barron space can be efficiently approximated with sums of determinants. This yields a factorial improvement in complexity compared to the standard representation in the Barron space and provides a theoretical explanation for the effectiveness of determinant-based architectures in ab-initio quantum chemistry.
Taming the sign problem of explicitly antisymmetrized neural networks via rough activation functions
May 24, 2022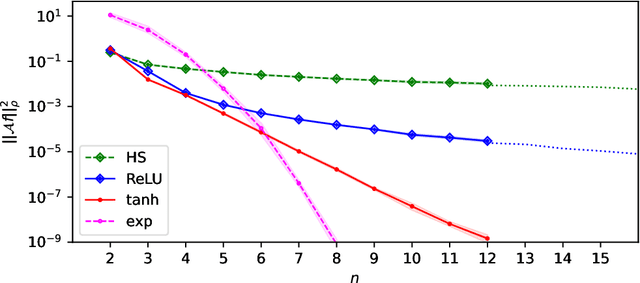
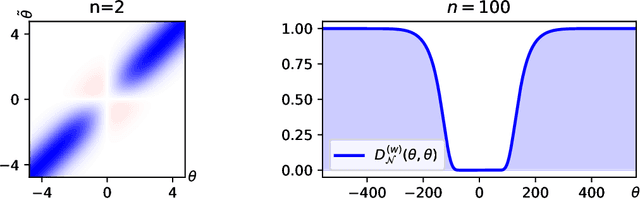

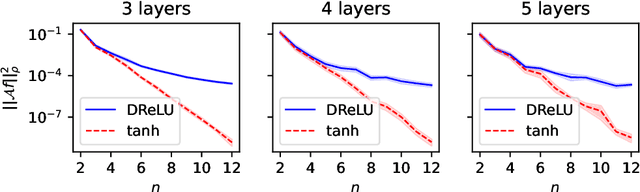
Explicit antisymmetrization of a two-layer neural network is a potential candidate for a universal function approximator for generic antisymmetric functions, which are ubiquitous in quantum physics. However, this strategy suffers from a sign problem, namely, due to near exact cancellation of positive and negative contributions, the magnitude of the antisymmetrized function may be significantly smaller than that before antisymmetrization. We prove that the severity of the sign problem is directly related to the smoothness of the activation function. For smooth activation functions (e.g., $\tanh$), the sign problem of the explicitly antisymmetrized two-layer neural network deteriorates super-polynomially with respect to the system size. On the other hand, for rough activation functions (e.g., ReLU), the deterioration rate of the sign problem can be tamed to be at most polynomial with respect to the system size. Finally, the cost of a direct implementation of antisymmetrized two-layer neural network scales factorially with respect to the system size. We describe an efficient algorithm for approximate evaluation of such a network, of which the cost scales polynomially with respect to the system size and inverse precision.
Sparse Gaussian ICA
Apr 03, 2018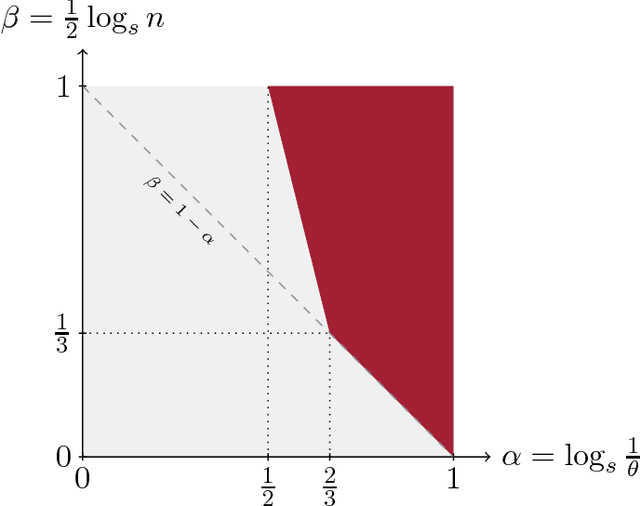
Independent component analysis (ICA) is a cornerstone of modern data analysis. Its goal is to recover a latent random vector S with independent components from samples of X=AS where A is an unknown mixing matrix. Critically, all existing methods for ICA rely on and exploit strongly the assumption that S is not Gaussian as otherwise A becomes unidentifiable. In this paper, we show that in fact one can handle the case of Gaussian components by imposing structure on the matrix A. Specifically, we assume that A is sparse and generic in the sense that it is generated from a sparse Bernoulli-Gaussian ensemble. Under this condition, we give an efficient algorithm to recover the columns of A given only the covariance matrix of X as input even when S has several Gaussian components.