 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge sample spectral analysis of graph-based multi-manifold clustering
Jul 28, 2021

In this work we study statistical properties of graph-based algorithms for multi-manifold clustering (MMC). In MMC the goal is to retrieve the multi-manifold structure underlying a given Euclidean data set when this one is assumed to be obtained by sampling a distribution on a union of manifolds $\mathcal{M} = \mathcal{M}_1 \cup\dots \cup \mathcal{M}_N$ that may intersect with each other and that may have different dimensions. We investigate sufficient conditions that similarity graphs on data sets must satisfy in order for their corresponding graph Laplacians to capture the right geometric information to solve the MMC problem. Precisely, we provide high probability error bounds for the spectral approximation of a tensorized Laplacian on $\mathcal{M}$ with a suitable graph Laplacian built from the observations; the recovered tensorized Laplacian contains all geometric information of all the individual underlying manifolds. We provide an example of a family of similarity graphs, which we call annular proximity graphs with angle constraints, satisfying these sufficient conditions. We contrast our family of graphs with other constructions in the literature based on the alignment of tangent planes. Extensive numerical experiments expand the insights that our theory provides on the MMC problem.
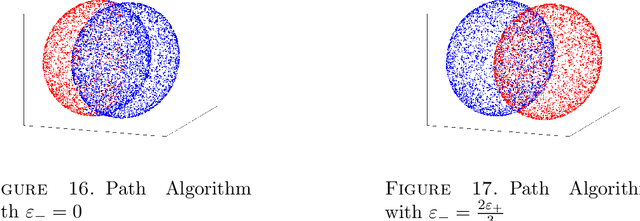
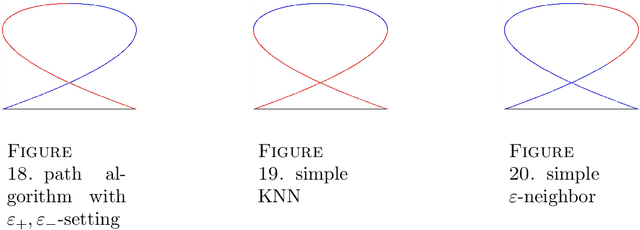
Adversarial Classification: Necessary conditions and geometric flows
Nov 21, 2020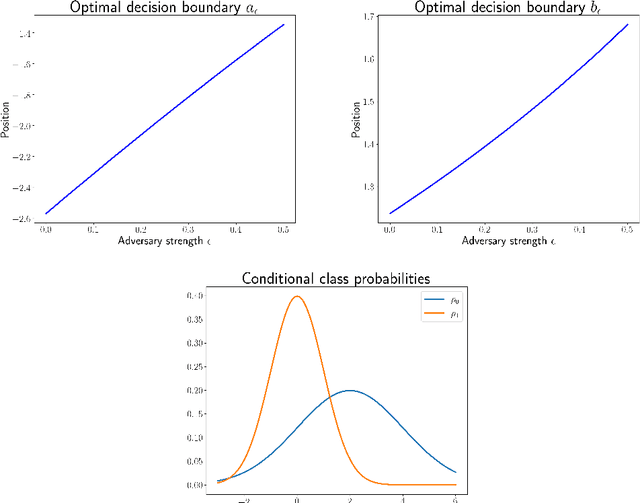
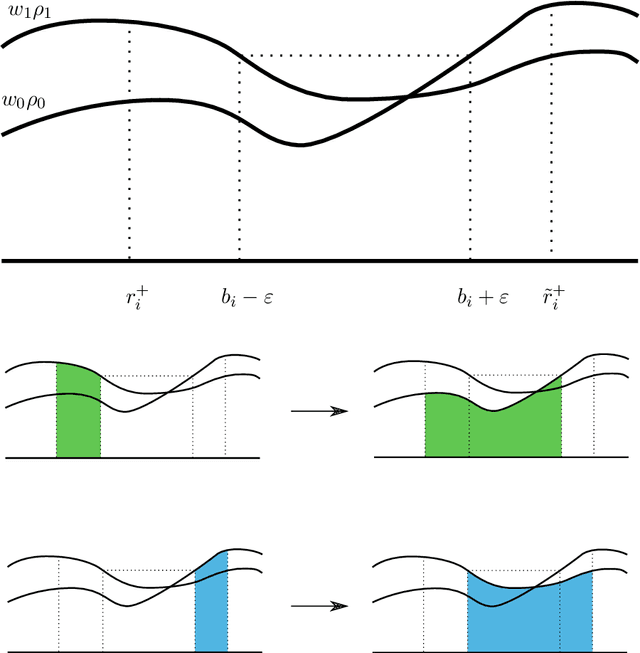
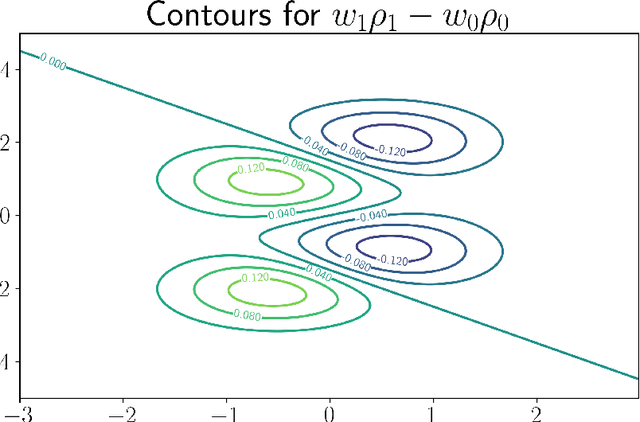
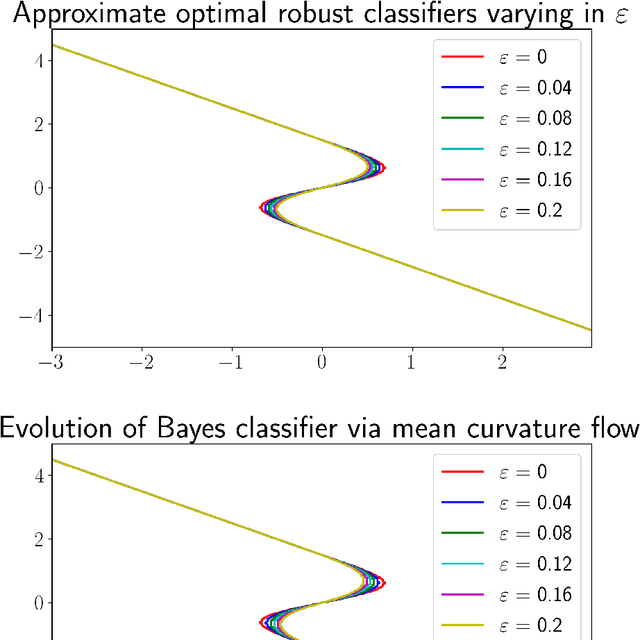
We study a version of adversarial classification where an adversary is empowered to corrupt data inputs up to some distance $\varepsilon$, using tools from variational analysis. In particular, we describe necessary conditions associated with the optimal classifier subject to such an adversary. Using the necessary conditions, we derive a geometric evolution equation which can be used to track the change in classification boundaries as $\varepsilon$ varies. This evolution equation may be described as an uncoupled system of differential equations in one dimension, or as a mean curvature type equation in higher dimension. In one dimension we rigorously prove that one can use the initial value problem starting from $\varepsilon=0$, which is simply the Bayes classifier, in order to solve for the global minimizer of the adversarial problem. Numerical examples illustrating these ideas are also presented.
Lipschitz regularity of graph Laplacians on random data clouds
Jul 13, 2020
In this paper we study Lipschitz regularity of elliptic PDEs on geometric graphs, constructed from random data points. The data points are sampled from a distribution supported on a smooth manifold. The family of equations that we study arises in data analysis in the context of graph-based learning and contains, as important examples, the equations satisfied by graph Laplacian eigenvectors. In particular, we prove high probability interior and global Lipschitz estimates for solutions of graph Poisson equations. Our results can be used to show that graph Laplacian eigenvectors are, with high probability, essentially Lipschitz regular with constants depending explicitly on their corresponding eigenvalues. Our analysis relies on a probabilistic coupling argument of suitable random walks at the continuum level, and an interpolation method for extending functions on random point clouds to the continuum manifold. As a byproduct of our general regularity results, we obtain high probability $L^\infty$ and approximate $\mathcal{C}^{0,1}$ convergence rates for the convergence of graph Laplacian eigenvectors towards eigenfunctions of the corresponding weighted Laplace-Beltrami operators. The convergence rates we obtain scale like the $L^2$-convergence rates established by two of the authors in previous work.
Traditional and accelerated gradient descent for neural architecture search
Jul 02, 2020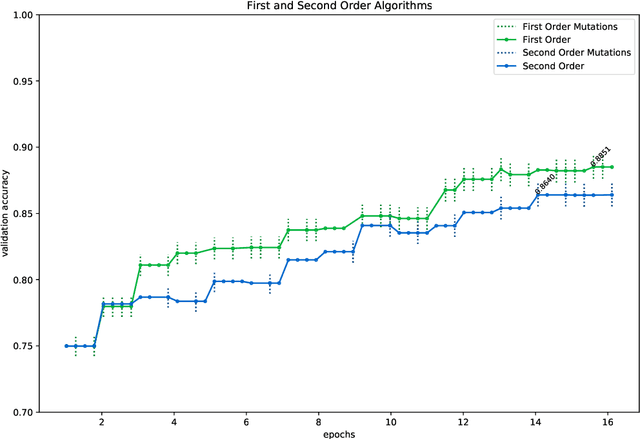
In this paper, we introduce two algorithms for neural architecture search (NASGD and NASAGD) following the theoretical work by two of the authors [4], which aimed at introducing the conceptual basis for new notions of traditional and accelerated gradient descent algorithms for the optimization of a function on a semi-discrete space using ideas from optimal transport theory. Our methods, which use the network morphism framework introduced in [3] as a baseline, can analyze forty times as many architectures as the hill climbing methods [3,11] while using the same computational resources and time and achieving comparable levels of accuracy. For example, using NASGD on CIFAR-10, our method designs and trains networks with an error rate of 4.06 in only 12 hours on a single GPU.
Semi-discrete optimization through semi-discrete optimal transport: a framework for neural architecture search
Jun 26, 2020In this paper we introduce a theoretical framework for semi-discrete optimization using ideas from optimal transport. Our primary motivation is in the field of deep learning, and specifically in the task of neural architecture search. With this aim in mind, we discuss the geometric and theoretical motivation for new techniques for neural architecture search (in the companion work \cite{practical}; we show that algorithms inspired by our framework are competitive with contemporaneous methods). We introduce a Riemannian like metric on the space of probability measures over a semi-discrete space $\mathbb{R}^d \times \mathcal{G}$ where $\mathcal{G}$ is a finite weighted graph. With such Riemmanian structure in hand, we derive formal expressions for the gradient flow of a relative entropy functional, as well as second order dynamics for the optimization of said energy. Then, with the aim of providing a rigorous motivation for the gradient flow equations derived formally we also consider an iterative procedure known as minimizing movement scheme (i.e., Implicit Euler scheme, or JKO scheme) and apply it to the relative entropy with respect to a suitable cost function. For some specific choices of metric and cost, we rigorously show that the minimizing movement scheme of the relative entropy functional converges to the gradient flow process provided by the formal Riemannian structure. This flow coincides with a system of reaction-diffusion equations on $\mathbb{R}^d$.
From graph cuts to isoperimetric inequalities: Convergence rates of Cheeger cuts on data clouds
Apr 20, 2020
In this work we study statistical properties of graph-based clustering algorithms that rely on the optimization of balanced graph cuts, the main example being the optimization of Cheeger cuts. We consider proximity graphs built from data sampled from an underlying distribution supported on a generic smooth compact manifold $M$. In this setting, we obtain high probability convergence rates for both the Cheeger constant and the associated Cheeger cuts towards their continuum counterparts. The key technical tools are careful estimates of interpolation operators which lift empirical Cheeger cuts to the continuum, as well as continuum stability estimates for isoperimetric problems. To our knowledge the quantitative estimates obtained here are the first of their kind.
Improved spectral convergence rates for graph Laplacians on epsilon-graphs and k-NN graphs
Oct 29, 2019In this paper we improve the spectral convergence rates for graph-based approximations of Laplace-Beltrami operators constructed from random data. We utilize regularity of the continuum eigenfunctions and strong pointwise consistency results to prove that spectral convergence rates are the same as the pointwise consistency rates for graph Laplacians. In particular, for an optimal choice of the graph connectivity $\varepsilon$, our results show that the eigenvalues and eigenvectors of the graph Laplacian converge to those of the Laplace-Beltrami operator at a rate of $O(n^{-1/(m+4)})$, up to log factors, where $m$ is the manifold dimension and $n$ is the number of vertices in the graph. Our approach is general and allows us to analyze a large variety of graph constructions that include $\varepsilon$-graphs and $k$-NN graphs.
Local Regularization of Noisy Point Clouds: Improved Global Geometric Estimates and Data Analysis
Apr 06, 2019

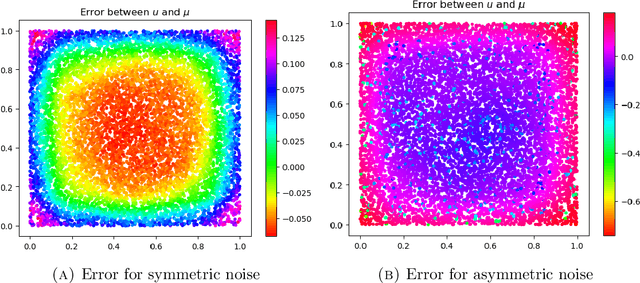
Several data analysis techniques employ similarity relationships between data points to uncover the intrinsic dimension and geometric structure of the underlying data-generating mechanism. In this paper we work under the model assumption that the data is made of random perturbations of feature vectors lying on a low-dimensional manifold. We study two questions: how to define the similarity relationship over noisy data points, and what is the resulting impact of the choice of similarity in the extraction of global geometric information from the underlying manifold. We provide concrete mathematical evidence that using a local regularization of the noisy data to define the similarity improves the approximation of the hidden Euclidean distance between unperturbed points. Furthermore, graph-based objects constructed with the locally regularized similarity function satisfy better error bounds in their recovery of global geometric ones. Our theory is supported by numerical experiments that demonstrate that the gain in geometric understanding facilitated by local regularization translates into a gain in classification accuracy in simulated and real data.
Geometric structure of graph Laplacian embeddings
Jan 30, 2019

We analyze the spectral clustering procedure for identifying coarse structure in a data set $x_1, \dots, x_n$, and in particular study the geometry of graph Laplacian embeddings which form the basis for spectral clustering algorithms. More precisely, we assume that the data is sampled from a mixture model supported on a manifold $\mathcal{M}$ embedded in $\mathbb{R}^d$, and pick a connectivity length-scale $\varepsilon>0$ to construct a kernelized graph Laplacian. We introduce a notion of a well-separated mixture model which only depends on the model itself, and prove that when the model is well separated, with high probability the embedded data set concentrates on cones that are centered around orthogonal vectors. Our results are meaningful in the regime where $\varepsilon = \varepsilon(n)$ is allowed to decay to zero at a slow enough rate as the number of data points grows. This rate depends on the intrinsic dimension of the manifold on which the data is supported.
A maximum principle argument for the uniform convergence of graph Laplacian regressors
Jan 29, 2019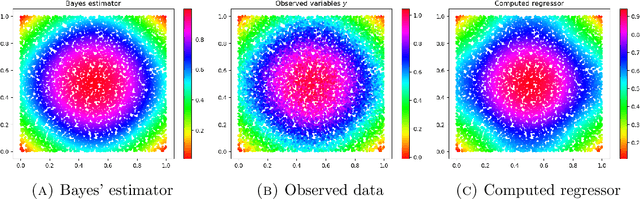
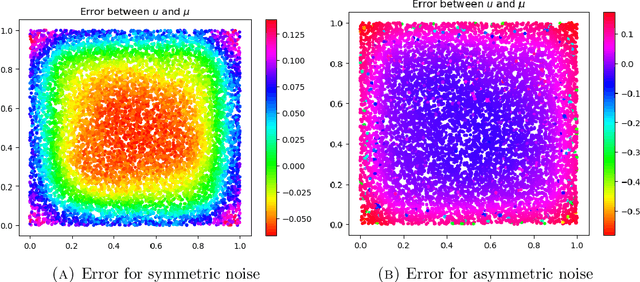
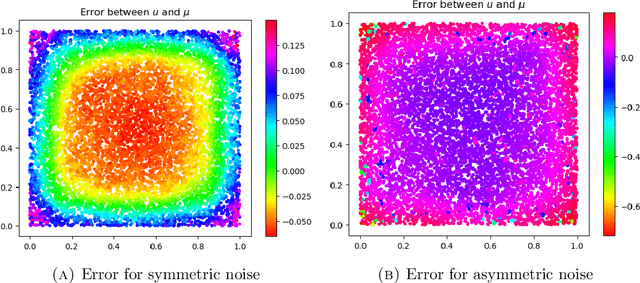
We study asymptotic consistency guarantees for a non-parametric regression problem with Laplacian regularization. In particular, we consider $(x_1, y_1), \dots, (x_n, y_n)$ samples from some distribution on the cross product $\mathcal{M} \times \mathbb{R}$, where $\mathcal{M}$ is a $m$-dimensional manifold embedded in $\mathbb{R}^d$. A geometric graph on the cloud $\{x_1, \dots, x_n \}$ is constructed by connecting points that are within some specified distance $\varepsilon_n$. A suitable semi-linear equation involving the resulting graph Laplacian is used to obtain a regressor for the observed values of $y$. We establish probabilistic error rates for the uniform difference between the regressor constructed from the observed data and the Bayes regressor (or trend) associated to the ground-truth distribution. We give the explicit dependence of the rates in terms of the parameter $\varepsilon_n$, the strength of regularization $\beta_n$, and the number of data points $n$. Our argument relies on a simple, yet powerful, maximum principle for the graph Laplacian. We also address a simple extension of the framework to a semi-supervised setting.