 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Adversarial Robustness for Categorical Data via Universal Robust Embeddings
Jun 06, 2023



Research on adversarial robustness is primarily focused on image and text data. Yet, many scenarios in which lack of robustness can result in serious risks, such as fraud detection, medical diagnosis, or recommender systems often do not rely on images or text but instead on tabular data. Adversarial robustness in tabular data poses two serious challenges. First, tabular datasets often contain categorical features, and therefore cannot be tackled directly with existing optimization procedures. Second, in the tabular domain, algorithms that are not based on deep networks are widely used and offer great performance, but algorithms to enhance robustness are tailored to neural networks (e.g. adversarial training). In this paper, we tackle both challenges. We present a method that allows us to train adversarially robust deep networks for tabular data and to transfer this robustness to other classifiers via universal robust embeddings tailored to categorical data. These embeddings, created using a bilevel alternating minimization framework, can be transferred to boosted trees or random forests making them robust without the need for adversarial training while preserving their high accuracy on tabular data. We show that our methods outperform existing techniques within a practical threat model suitable for tabular data.
Sharpness-Aware Minimization Leads to Low-Rank Features
May 25, 2023



Sharpness-aware minimization (SAM) is a recently proposed method that minimizes the sharpness of the training loss of a neural network. While its generalization improvement is well-known and is the primary motivation, we uncover an additional intriguing effect of SAM: reduction of the feature rank which happens at different layers of a neural network. We show that this low-rank effect occurs very broadly: for different architectures such as fully-connected networks, convolutional networks, vision transformers and for different objectives such as regression, classification, language-image contrastive training. To better understand this phenomenon, we provide a mechanistic understanding of how low-rank features arise in a simple two-layer network. We observe that a significant number of activations gets entirely pruned by SAM which directly contributes to the rank reduction. We confirm this effect theoretically and check that it can also occur in deep networks, although the overall rank reduction mechanism can be more complex, especially for deep networks with pre-activation skip connections and self-attention layers. We make our code available at https://github.com/tml-epfl/sam-low-rank-features.
Saddle-to-Saddle Dynamics in Diagonal Linear Networks
Apr 02, 2023In this paper we fully describe the trajectory of gradient flow over diagonal linear networks in the limit of vanishing initialisation. We show that the limiting flow successively jumps from a saddle of the training loss to another until reaching the minimum $\ell_1$-norm solution. This saddle-to-saddle dynamics translates to an incremental learning process as each saddle corresponds to the minimiser of the loss constrained to an active set outside of which the coordinates must be zero. We explicitly characterise the visited saddles as well as the jumping times through a recursive algorithm reminiscent of the Homotopy algorithm used for computing the Lasso path. Our proof leverages a convenient arc-length time-reparametrisation which enables to keep track of the heteroclinic transitions between the jumps. Our analysis requires negligible assumptions on the data, applies to both under and overparametrised settings and covers complex cases where there is no monotonicity of the number of active coordinates. We provide numerical experiments to support our findings.
Penalising the biases in norm regularisation enforces sparsity
Mar 02, 2023



Controlling the parameters' norm often yields good generalisation when training neural networks. Beyond simple intuitions, the relation between parameters' norm and obtained estimators theoretically remains misunderstood. For one hidden ReLU layer networks with unidimensional data, this work shows the minimal parameters' norm required to represent a function is given by the total variation of its second derivative, weighted by a $\sqrt{1+x^2}$ factor. As a comparison, this $\sqrt{1+x^2}$ weighting disappears when the norm of the bias terms are ignored. This additional weighting is of crucial importance, since it is shown in this work to enforce uniqueness and sparsity (in number of kinks) of the minimal norm interpolator. On the other hand, omitting the bias' norm allows for non-sparse solutions. Penalising the bias terms in the regularisation, either explicitly or implicitly, thus leads to sparse estimators. This sparsity might take part in the good generalisation of neural networks that is empirically observed.
Model agnostic methods meta-learn despite misspecifications
Mar 02, 2023



Due to its empirical success on few shot classification and reinforcement learning, meta-learning recently received a lot of interest. Meta-learning leverages data from previous tasks to quickly learn a new task, despite limited data. In particular, model agnostic methods look for initialisation points from which gradient descent quickly adapts to any new task. Although it has been empirically suggested that such methods learn a good shared representation during training, there is no strong theoretical evidence of such behavior. More importantly, it is unclear whether these methods truly are model agnostic, i.e., whether they still learn a shared structure despite architecture misspecifications. To fill this gap, this work shows in the limit of an infinite number of tasks that first order ANIL with a linear two-layer network architecture successfully learns a linear shared representation. Moreover, this result holds despite misspecifications: having a large width with respect to the hidden dimension of the shared representation does not harm the algorithm performance. The learnt parameters then allow to get a small test loss after a single gradient step on any new task. Overall this illustrates how well model agnostic methods can adapt to any (unknown) model structure.
Linearization Algorithms for Fully Composite Optimization
Feb 24, 2023In this paper, we study first-order algorithms for solving fully composite optimization problems over bounded sets. We treat the differentiable and non-differentiable parts of the objective separately, linearizing only the smooth components. This provides us with new generalizations of the classical and accelerated Frank-Wolfe methods, that are applicable to non-differentiable problems whenever we can access the structure of the objective. We prove global complexity bounds for our algorithms that are optimal in several settings.
(S)GD over Diagonal Linear Networks: Implicit Regularisation, Large Stepsizes and Edge of Stability
Feb 17, 2023In this paper, we investigate the impact of stochasticity and large stepsizes on the implicit regularisation of gradient descent (GD) and stochastic gradient descent (SGD) over diagonal linear networks. We prove the convergence of GD and SGD with macroscopic stepsizes in an overparametrised regression setting and characterise their solutions through an implicit regularisation problem. Our crisp characterisation leads to qualitative insights about the impact of stochasticity and stepsizes on the recovered solution. Specifically, we show that large stepsizes consistently benefit SGD for sparse regression problems, while they can hinder the recovery of sparse solutions for GD. These effects are magnified for stepsizes in a tight window just below the divergence threshold, in the ``edge of stability'' regime. Our findings are supported by experimental results.
A modern look at the relationship between sharpness and generalization
Feb 14, 2023Sharpness of minima is a promising quantity that can correlate with generalization in deep networks and, when optimized during training, can improve generalization. However, standard sharpness is not invariant under reparametrizations of neural networks, and, to fix this, reparametrization-invariant sharpness definitions have been proposed, most prominently adaptive sharpness (Kwon et al., 2021). But does it really capture generalization in modern practical settings? We comprehensively explore this question in a detailed study of various definitions of adaptive sharpness in settings ranging from training from scratch on ImageNet and CIFAR-10 to fine-tuning CLIP on ImageNet and BERT on MNLI. We focus mostly on transformers for which little is known in terms of sharpness despite their widespread usage. Overall, we observe that sharpness does not correlate well with generalization but rather with some training parameters like the learning rate that can be positively or negatively correlated with generalization depending on the setup. Interestingly, in multiple cases, we observe a consistent negative correlation of sharpness with out-of-distribution error implying that sharper minima can generalize better. Finally, we illustrate on a simple model that the right sharpness measure is highly data-dependent, and that we do not understand well this aspect for realistic data distributions. The code of our experiments is available at https://github.com/tml-epfl/sharpness-vs-generalization.
SGD with large step sizes learns sparse features
Oct 11, 2022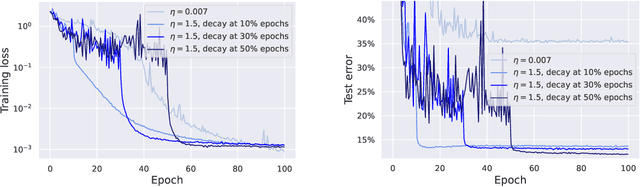

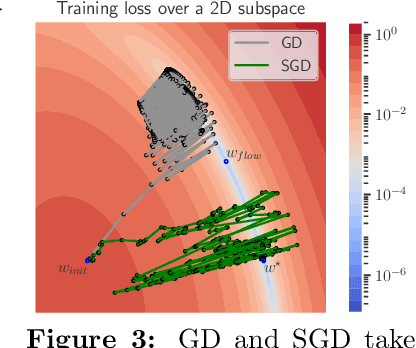

We showcase important features of the dynamics of the Stochastic Gradient Descent (SGD) in the training of neural networks. We present empirical observations that commonly used large step sizes (i) lead the iterates to jump from one side of a valley to the other causing loss stabilization, and (ii) this stabilization induces a hidden stochastic dynamics orthogonal to the bouncing directions that biases it implicitly toward simple predictors. Furthermore, we show empirically that the longer large step sizes keep SGD high in the loss landscape valleys, the better the implicit regularization can operate and find sparse representations. Notably, no explicit regularization is used so that the regularization effect comes solely from the SGD training dynamics influenced by the step size schedule. Therefore, these observations unveil how, through the step size schedules, both gradient and noise drive together the SGD dynamics through the loss landscape of neural networks. We justify these findings theoretically through the study of simple neural network models as well as qualitative arguments inspired from stochastic processes. Finally, this analysis allows to shed a new light on some common practice and observed phenomena when training neural networks. The code of our experiments is available at https://github.com/tml-epfl/sgd-sparse-features.
Label noise (stochastic) gradient descent implicitly solves the Lasso for quadratic parametrisation
Jun 20, 2022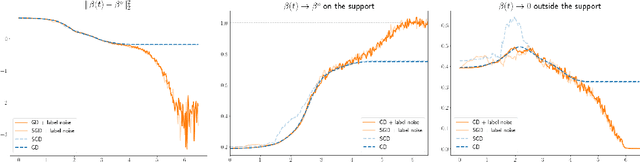
Understanding the implicit bias of training algorithms is of crucial importance in order to explain the success of overparametrised neural networks. In this paper, we study the role of the label noise in the training dynamics of a quadratically parametrised model through its continuous time version. We explicitly characterise the solution chosen by the stochastic flow and prove that it implicitly solves a Lasso program. To fully complete our analysis, we provide nonasymptotic convergence guarantees for the dynamics as well as conditions for support recovery. We also give experimental results which support our theoretical claims. Our findings highlight the fact that structured noise can induce better generalisation and help explain the greater performances of stochastic dynamics as observed in practice.