 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference for Quantum HyperNetworks
Jun 06, 2025



Binary Neural Networks (BiNNs), which employ single-bit precision weights, have emerged as a promising solution to reduce memory usage and power consumption while maintaining competitive performance in large-scale systems. However, training BiNNs remains a significant challenge due to the limitations of conventional training algorithms. Quantum HyperNetworks offer a novel paradigm for enhancing the optimization of BiNN by leveraging quantum computing. Specifically, a Variational Quantum Algorithm is employed to generate binary weights through quantum circuit measurements, while key quantum phenomena such as superposition and entanglement facilitate the exploration of a broader solution space. In this work, we establish a connection between this approach and Bayesian inference by deriving the Evidence Lower Bound (ELBO), when direct access to the output distribution is available (i.e., in simulations), and introducing a surrogate ELBO based on the Maximum Mean Discrepancy (MMD) metric for scenarios involving implicit distributions, as commonly encountered in practice. Our experimental results demonstrate that the proposed methods outperform standard Maximum Likelihood Estimation (MLE), improving trainability and generalization.
A Cramér Distance perspective on Non-crossing Quantile Regression in Distributional Reinforcement Learning
Oct 01, 2021

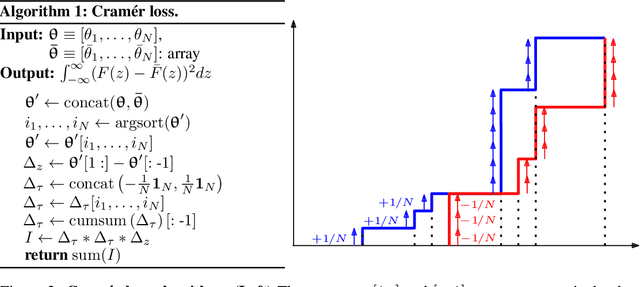

Distributional reinforcement learning (DRL) extends the value-based approach by using a deep convolutional network to approximate the full distribution over future returns instead of the mean only, providing a richer signal that leads to improved performances. Quantile-based methods like QR-DQN project arbitrary distributions onto a parametric subset of staircase distributions by minimizing the 1-Wasserstein distance, however, due to biases in the gradients, the quantile regression loss is used instead for training, guaranteeing the same minimizer and enjoying unbiased gradients. Recently, monotonicity constraints on the quantiles have been shown to improve the performance of QR-DQN for uncertainty-based exploration strategies. The contribution of this work is in the setting of fixed quantile levels and is twofold. First, we prove that the Cram\'er distance yields a projection that coincides with the 1-Wasserstein one and that, under monotonicity constraints, the squared Cram\'er and the quantile regression losses yield collinear gradients, shedding light on the connection between these important elements of DRL. Second, we propose a novel non-crossing neural architecture that allows a good training performance using a novel algorithm to compute the Cram\'er distance, yielding significant improvements over QR-DQN in a number of games of the standard Atari 2600 benchmark.