 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear System Identification via Tensor Completion
Jun 13, 2019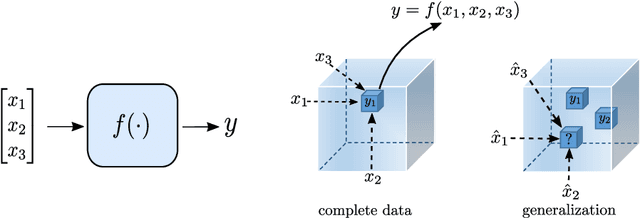
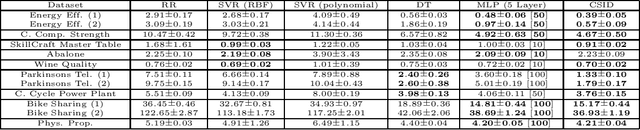
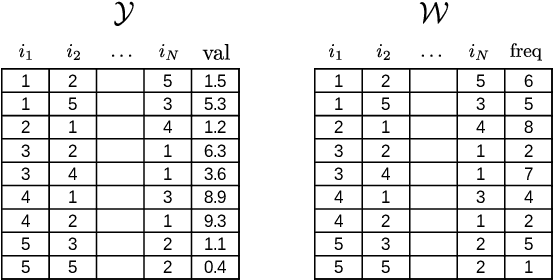
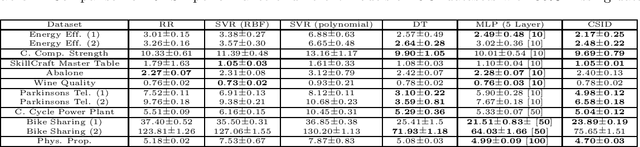
Function approximation from input and output data pairs constitutes a fundamental problem in supervised learning. Deep neural networks are currently the most popular method for learning to mimic the input-output relationship of a generic nonlinear system, as they have proven to be very effective in approximating complex highly nonlinear functions. In this work, we propose low-rank tensor completion as an appealing alternative for modeling and learning complex nonlinear systems. We model the interactions between the $N$ input variables and the scalar output of a system by a single N-way tensor, and setup a weighted low-rank tensor completion problem with smoothness regularization which we tackle using a block coordinate descent algorithm. We extend our method to the multi-output setting and the case of partially observed data, which cannot be readily handled by neural networks. Finally, we demonstrate the effectiveness of the approach using several regression tasks including some standard benchmarks and a challenging student grade prediction task.
Machine Learning in the Air
Apr 28, 2019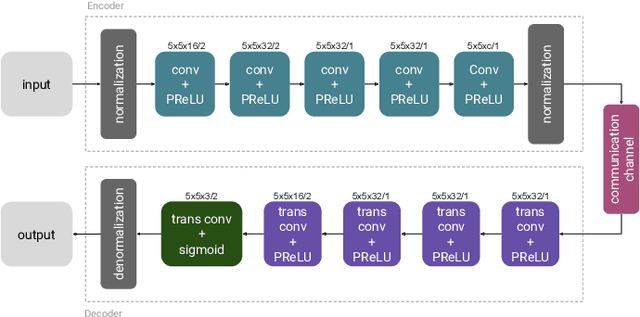
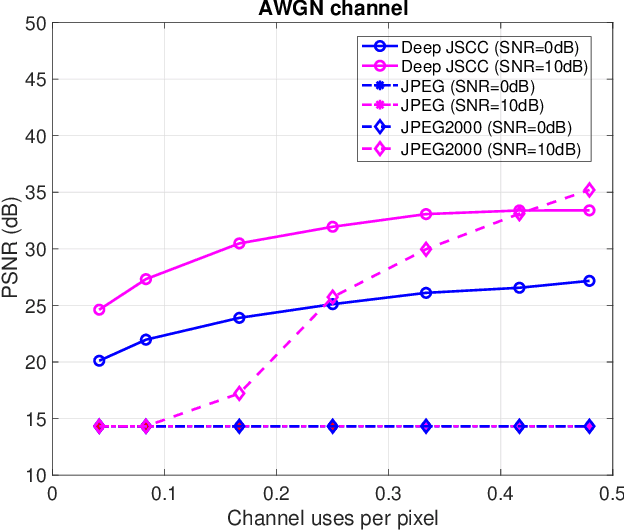
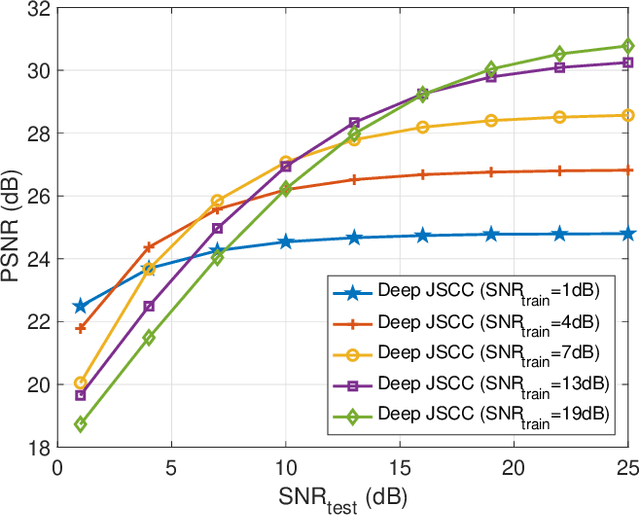
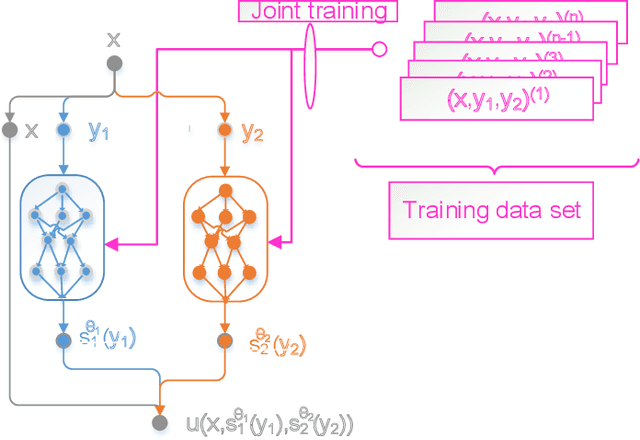
Thanks to the recent advances in processing speed and data acquisition and storage, machine learning (ML) is penetrating every facet of our lives, and transforming research in many areas in a fundamental manner. Wireless communications is another success story -- ubiquitous in our lives, from handheld devices to wearables, smart homes, and automobiles. While recent years have seen a flurry of research activity in exploiting ML tools for various wireless communication problems, the impact of these techniques in practical communication systems and standards is yet to be seen. In this paper, we review some of the major promises and challenges of ML in wireless communication systems, focusing mainly on the physical layer. We present some of the most striking recent accomplishments that ML techniques have achieved with respect to classical approaches, and point to promising research directions where ML is likely to make the biggest impact in the near future. We also highlight the complementary problem of designing physical layer techniques to enable distributed ML at the wireless network edge, which further emphasizes the need to understand and connect ML with fundamental concepts in wireless communications.
Learning Mixtures of Smooth Product Distributions: Identifiability and Algorithm
Apr 02, 2019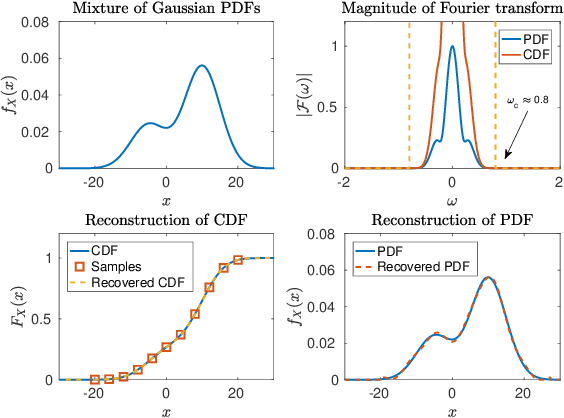
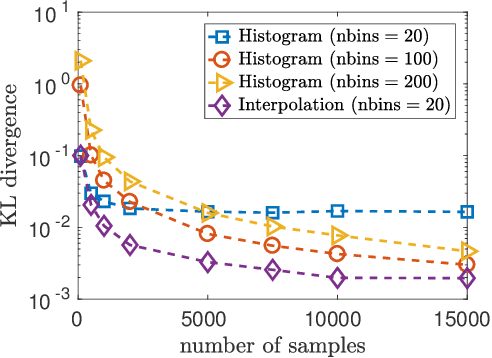
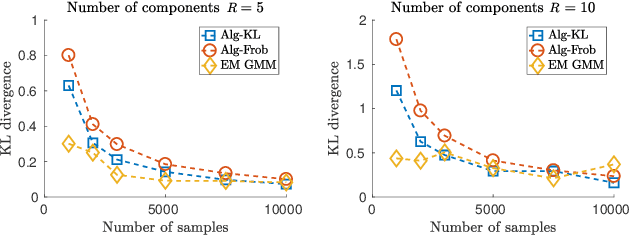
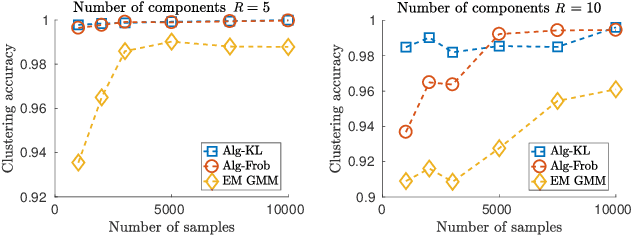
We study the problem of learning a mixture model of non-parametric product distributions. The problem of learning a mixture model is that of finding the component distributions along with the mixing weights using observed samples generated from the mixture. The problem is well-studied in the parametric setting, i.e., when the component distributions are members of a parametric family -- such as Gaussian distributions. In this work, we focus on multivariate mixtures of non-parametric product distributions and propose a two-stage approach which recovers the component distributions of the mixture under a smoothness condition. Our approach builds upon the identifiability properties of the canonical polyadic (low-rank) decomposition of tensors, in tandem with Fourier and Shannon-Nyquist sampling staples from signal processing. We demonstrate the effectiveness of the approach on synthetic and real datasets.
Energy Storage Management via Deep Q-Networks
Mar 26, 2019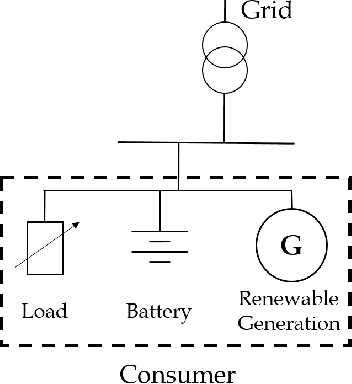
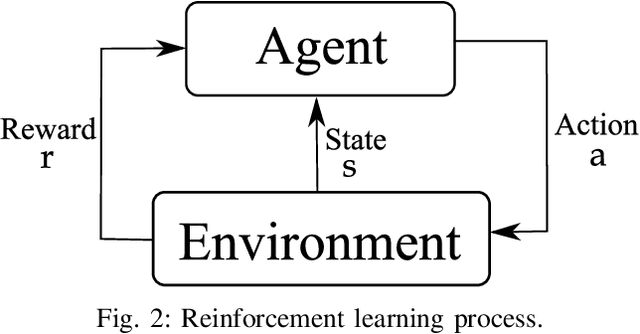
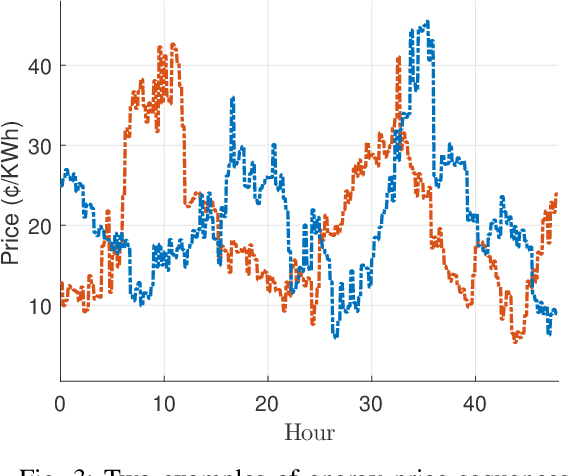
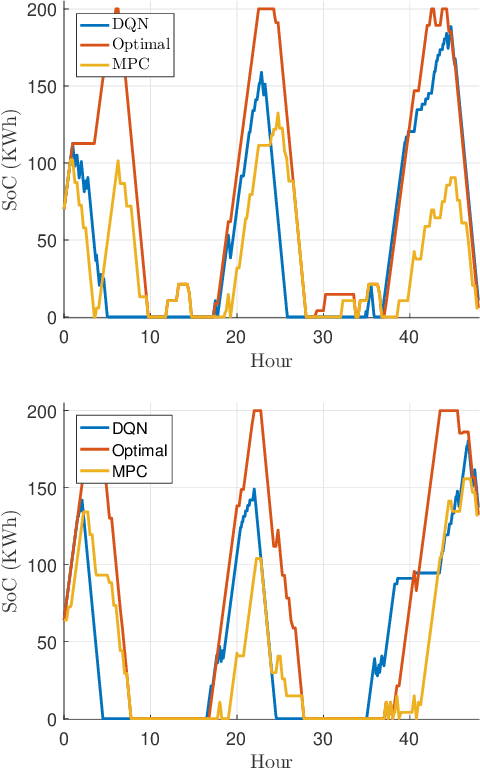
Energy storage devices represent environmentally friendly candidates to cope with volatile renewable energy generation. Motivated by the increase in privately owned storage systems, this paper studies the problem of real-time control of a storage unit co-located with a renewable energy generator and an inelastic load. Unlike many approaches in the literature, no distributional assumptions are being made on the renewable energy generation or the real-time prices. Building on the deep Q-networks algorithm, a reinforcement learning approach utilizing a neural network is devised where the storage unit operational constraints are respected. The neural network approximates the action-value function which dictates what action (charging, discharging, etc.) to take. Simulations indicate that near-optimal performance can be attained with the proposed learning-based control policy for the storage units.
Learning Nonlinear Mixtures: Identifiability and Algorithm
Jan 06, 2019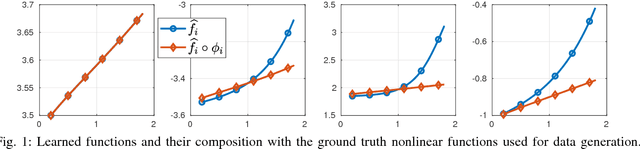
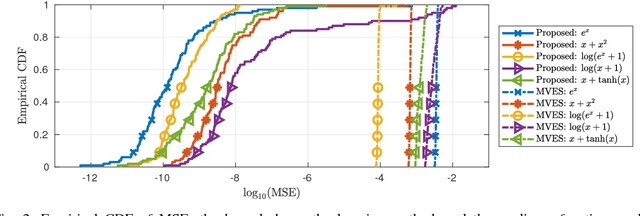
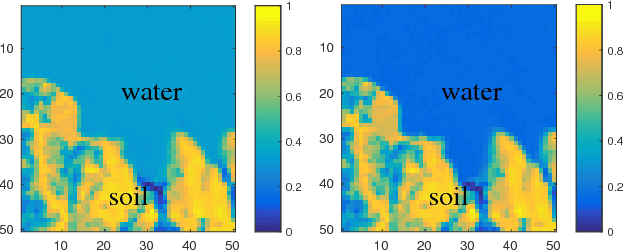
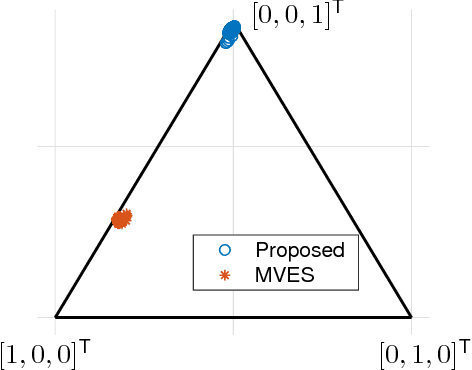
Linear mixture models have proven very useful in a plethora of applications, e.g., topic modeling, clustering, and source separation. As a critical aspect of the linear mixture models, identifiability of the model parameters is well-studied, under frameworks such as independent component analysis and constrained matrix factorization. Nevertheless, when the linear mixtures are distorted by an unknown nonlinear functions -- which is well-motivated and more realistic in many cases -- the identifiability issues are much less studied. This work proposes an identification criterion for a nonlinear mixture model that is well grounded in many real-world applications, and offers identifiability guarantees. A practical implementation based on a judiciously designed neural network is proposed to realize the criterion, and an effective learning algorithm is proposed. Numerical results on synthetic and real-data corroborate effectiveness of the proposed method.
From Gene Expression to Drug Response: A Collaborative Filtering Approach
Oct 31, 2018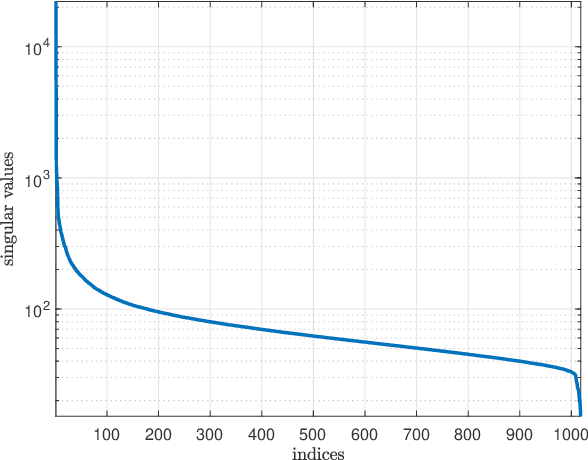
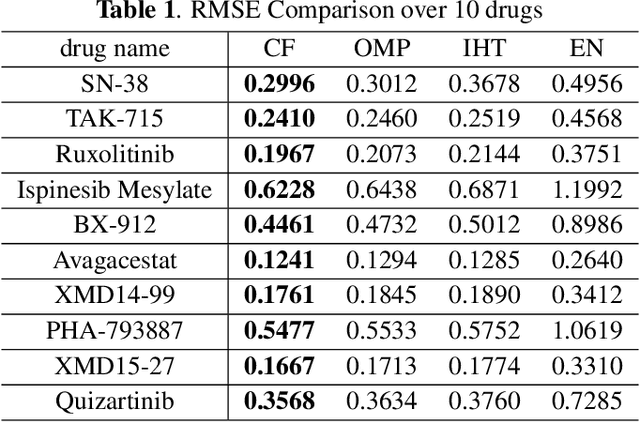
Predicting the response of cancer cells to drugs is an important problem in pharmacogenomics. Recent efforts in generation of large scale datasets profiling gene expression and drug sensitivity in cell lines have provided a unique opportunity to study this problem. However, one major challenge is the small number of samples (cell lines) compared to the number of features (genes) even in these large datasets. We propose a collaborative filtering (CF) like algorithm for modeling gene-drug relationship to identify patients most likely to benefit from a treatment. Due to the correlation of gene expressions in different cell lines, the gene expression matrix is approximately low-rank, which suggests that drug responses could be estimated from a reduced dimension latent space of the gene expression. Towards this end, we propose a joint low-rank matrix factorization and latent linear regression approach. Experiments with data from the Genomics of Drug Sensitivity in Cancer database are included to show that the proposed method can predict drug-gene associations better than the state-of-the-art methods.
Nonnegative Matrix Factorization for Signal and Data Analytics: Identifiability, Algorithms, and Applications
Oct 18, 2018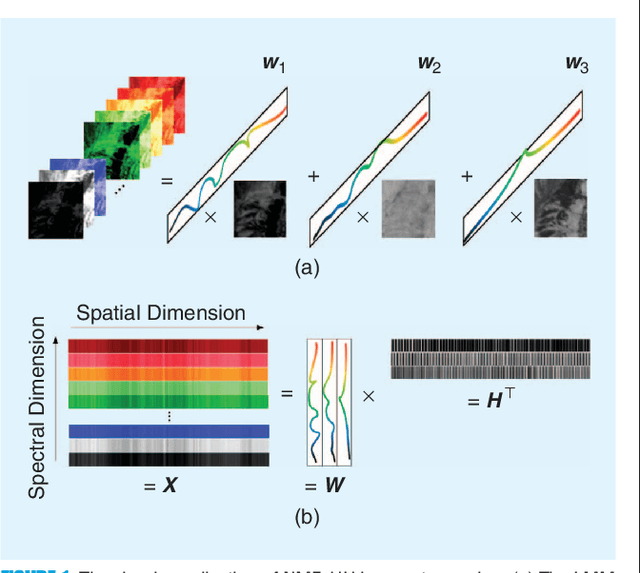
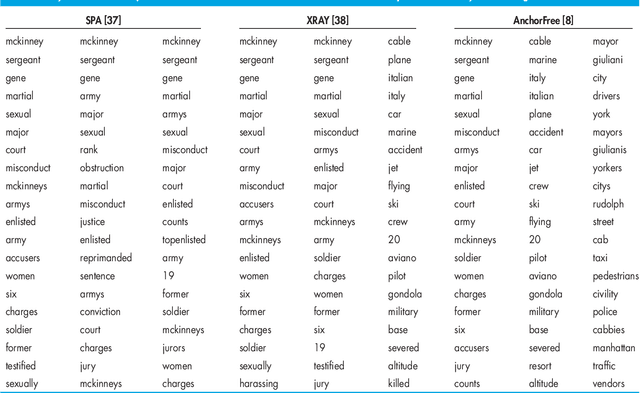
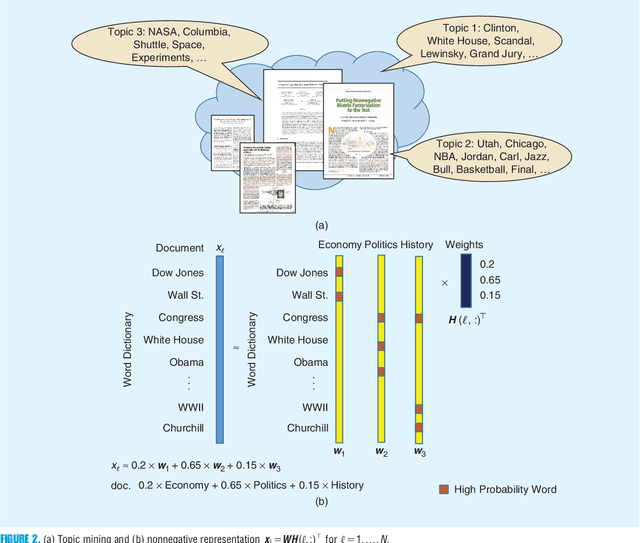
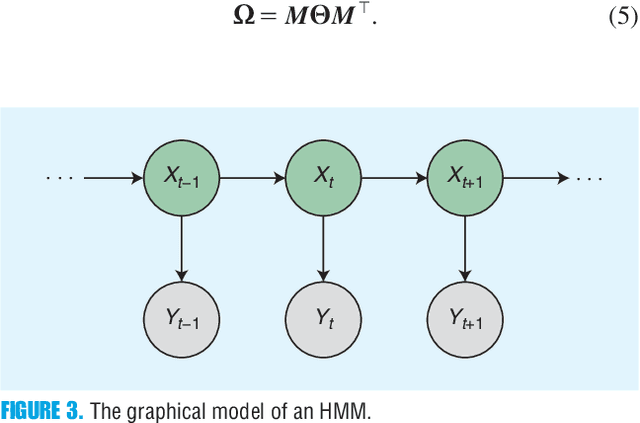
Nonnegative matrix factorization (NMF) has become a workhorse for signal and data analytics, triggered by its model parsimony and interpretability. Perhaps a bit surprisingly, the understanding to its model identifiability---the major reason behind the interpretability in many applications such as topic mining and hyperspectral imaging---had been rather limited until recent years. Beginning from the 2010s, the identifiability research of NMF has progressed considerably: Many interesting and important results have been discovered by the signal processing (SP) and machine learning (ML) communities. NMF identifiability has a great impact on many aspects in practice, such as ill-posed formulation avoidance and performance-guaranteed algorithm design. On the other hand, there is no tutorial paper that introduces NMF from an identifiability viewpoint. In this paper, we aim at filling this gap by offering a comprehensive and deep tutorial on model identifiability of NMF as well as the connections to algorithms and applications. This tutorial will help researchers and graduate students grasp the essence and insights of NMF, thereby avoiding typical `pitfalls' that are often times due to unidentifiable NMF formulations. This paper will also help practitioners pick/design suitable factorization tools for their own problems.
Coupled Graphs and Tensor Factorization for Recommender Systems and Community Detection
Sep 22, 2018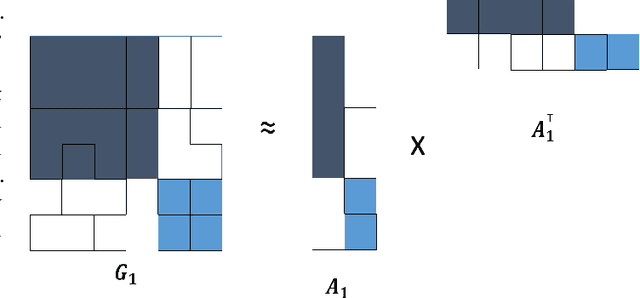
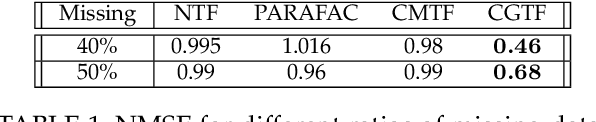
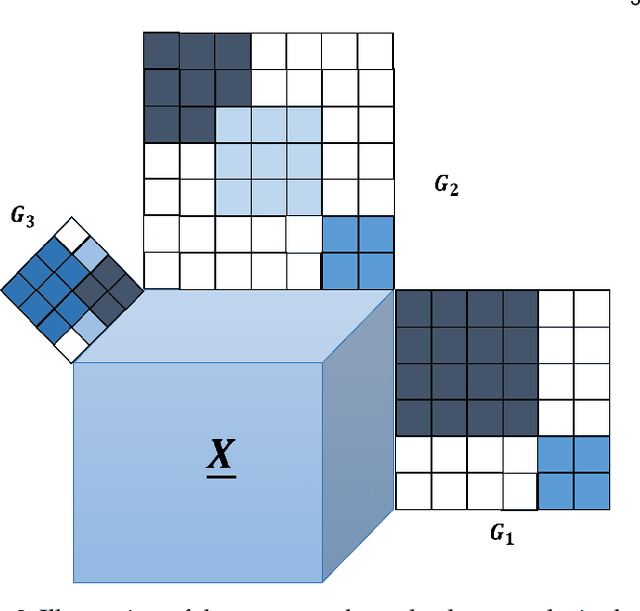
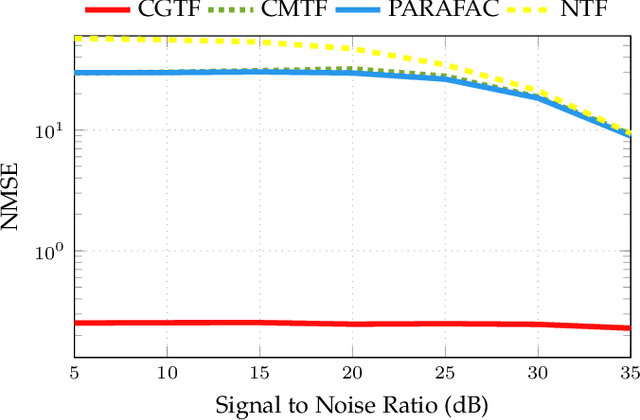
Joint analysis of data from multiple information repositories facilitates uncovering the underlying structure in heterogeneous datasets. Single and coupled matrix-tensor factorization (CMTF) has been widely used in this context for imputation-based recommendation from ratings, social network, and other user-item data. When this side information is in the form of item-item correlation matrices or graphs, existing CMTF algorithms may fall short. Alleviating current limitations, we introduce a novel model coined coupled graph-tensor factorization (CGTF) that judiciously accounts for graph-related side information. The CGTF model has the potential to overcome practical challenges, such as missing slabs from the tensor and/or missing rows/columns from the correlation matrices. A novel alternating direction method of multipliers (ADMM) is also developed that recovers the nonnegative factors of CGTF. Our algorithm enjoys closed-form updates that result in reduced computational complexity and allow for convergence claims. A novel direction is further explored by employing the interpretable factors to detect graph communities having the tensor as side information. The resulting community detection approach is successful even when some links in the graphs are missing. Results with real data sets corroborate the merits of the proposed methods relative to state-of-the-art competing factorization techniques in providing recommendations and detecting communities.
Tensors, Learning, and 'Kolmogorov Extension' for Finite-alphabet Random Vectors
Jul 27, 2018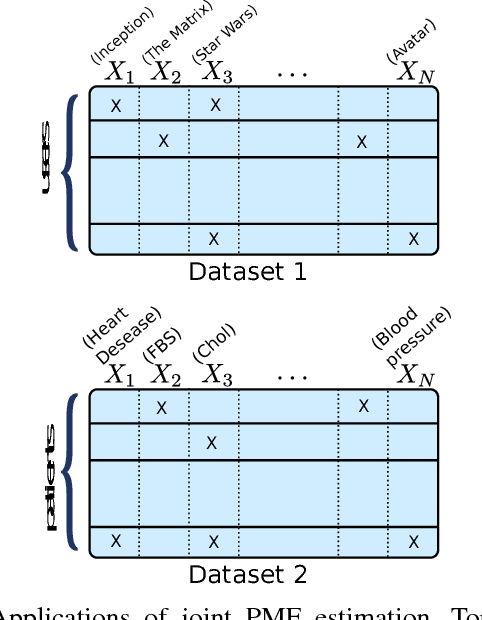
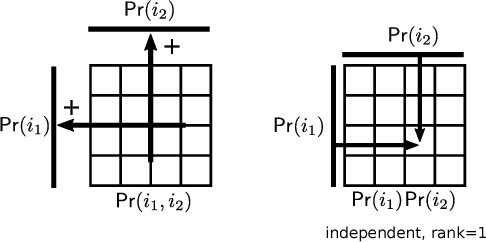
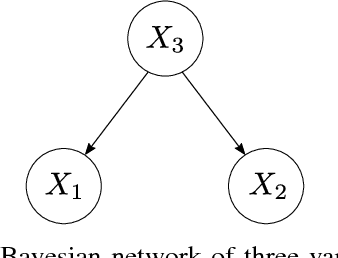
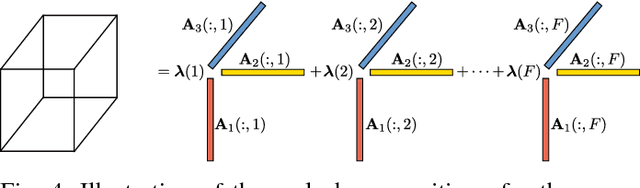
Estimating the joint probability mass function (PMF) of a set of random variables lies at the heart of statistical learning and signal processing. Without structural assumptions, such as modeling the variables as a Markov chain, tree, or other graphical model, joint PMF estimation is often considered mission impossible - the number of unknowns grows exponentially with the number of variables. But who gives us the structural model? Is there a generic, `non-parametric' way to control joint PMF complexity without relying on a priori structural assumptions regarding the underlying probability model? Is it possible to discover the operational structure without biasing the analysis up front? What if we only observe random subsets of the variables, can we still reliably estimate the joint PMF of all? This paper shows, perhaps surprisingly, that if the joint PMF of any three variables can be estimated, then the joint PMF of all the variables can be provably recovered under relatively mild conditions. The result is reminiscent of Kolmogorov's extension theorem - consistent specification of lower-dimensional distributions induces a unique probability measure for the entire process. The difference is that for processes of limited complexity (rank of the high-dimensional PMF) it is possible to obtain complete characterization from only three-dimensional distributions. In fact not all three-dimensional PMFs are needed; and under more stringent conditions even two-dimensional will do. Exploiting multilinear algebra, this paper proves that such higher-dimensional PMF completion can be guaranteed - several pertinent identifiability results are derived. It also provides a practical and efficient algorithm to carry out the recovery task. Judiciously designed simulations and real-data experiments on movie recommendation and data classification are presented to showcase the effectiveness of the approach.
Learning Hidden Markov Models from Pairwise Co-occurrences with Application to Topic Modeling
Jun 18, 2018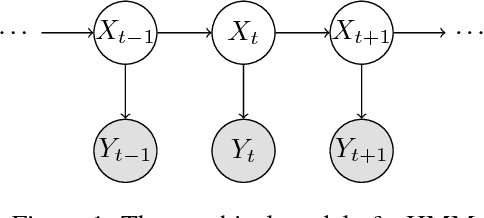

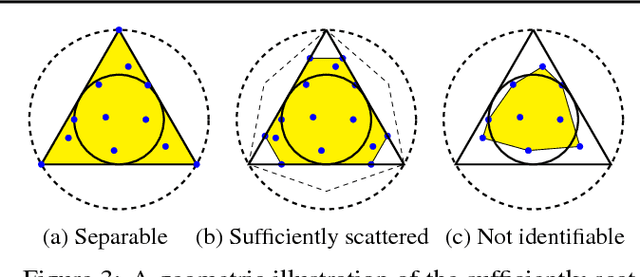
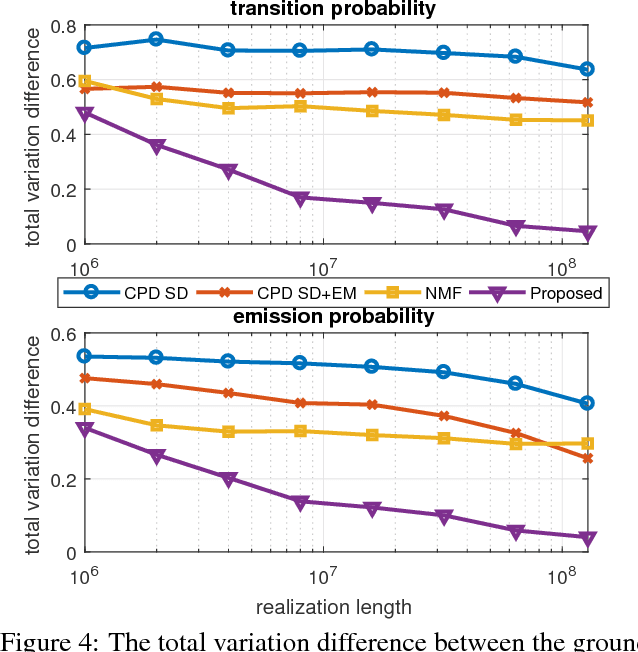
We present a new algorithm for identifying the transition and emission probabilities of a hidden Markov model (HMM) from the emitted data. Expectation-maximization becomes computationally prohibitive for long observation records, which are often required for identification. The new algorithm is particularly suitable for cases where the available sample size is large enough to accurately estimate second-order output probabilities, but not higher-order ones. We show that if one is only able to obtain a reliable estimate of the pairwise co-occurrence probabilities of the emissions, it is still possible to uniquely identify the HMM if the emission probability is \emph{sufficiently scattered}. We apply our method to hidden topic Markov modeling, and demonstrate that we can learn topics with higher quality if documents are modeled as observations of HMMs sharing the same emission (topic) probability, compared to the simple but widely used bag-of-words model.