 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-Based Models Improve Adversarial Robustness
Sep 15, 2022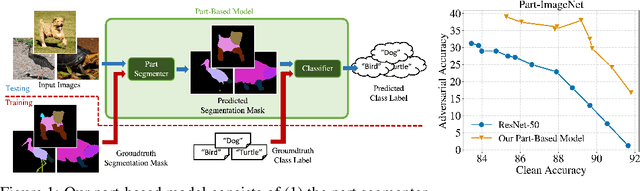
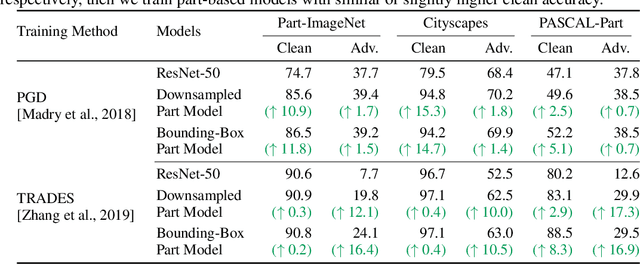

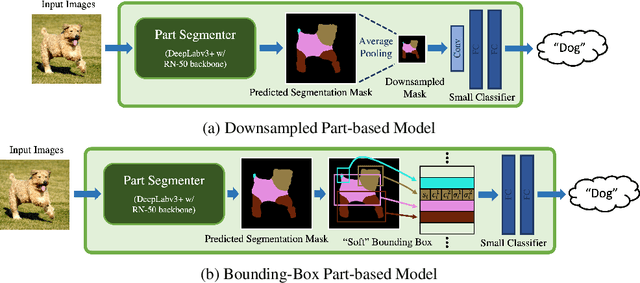
We show that combining human prior knowledge with end-to-end learning can improve the robustness of deep neural networks by introducing a part-based model for object classification. We believe that the richer form of annotation helps guide neural networks to learn more robust features without requiring more samples or larger models. Our model combines a part segmentation model with a tiny classifier and is trained end-to-end to simultaneously segment objects into parts and then classify the segmented object. Empirically, our part-based models achieve both higher accuracy and higher adversarial robustness than a ResNet-50 baseline on all three datasets. For instance, the clean accuracy of our part models is up to 15 percentage points higher than the baseline's, given the same level of robustness. Our experiments indicate that these models also reduce texture bias and yield better robustness against common corruptions and spurious correlations. The code is publicly available at https://github.com/chawins/adv-part-model.
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022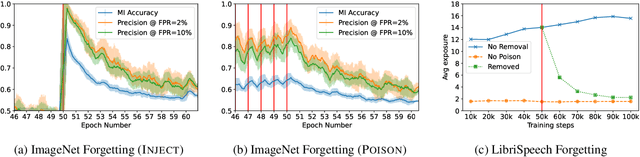
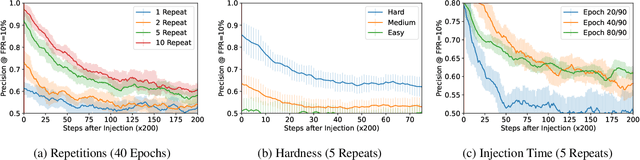
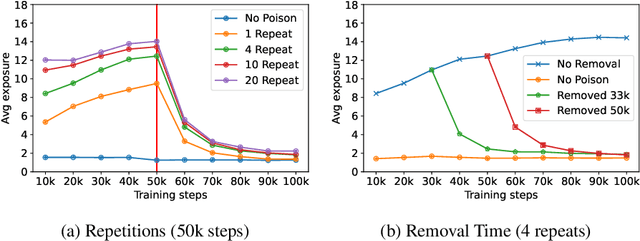
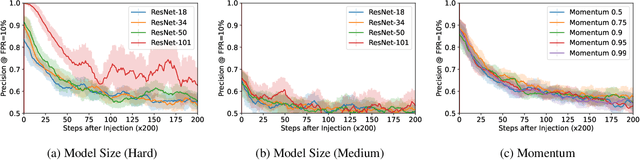
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
Increasing Confidence in Adversarial Robustness Evaluations
Jun 28, 2022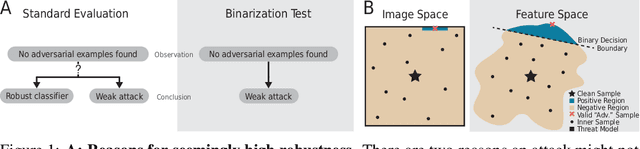
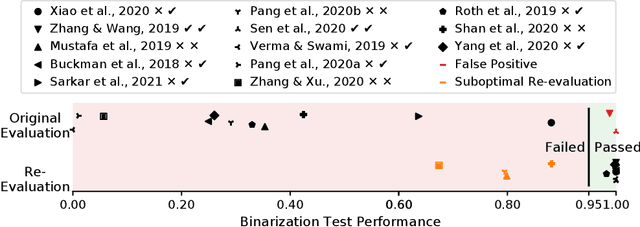
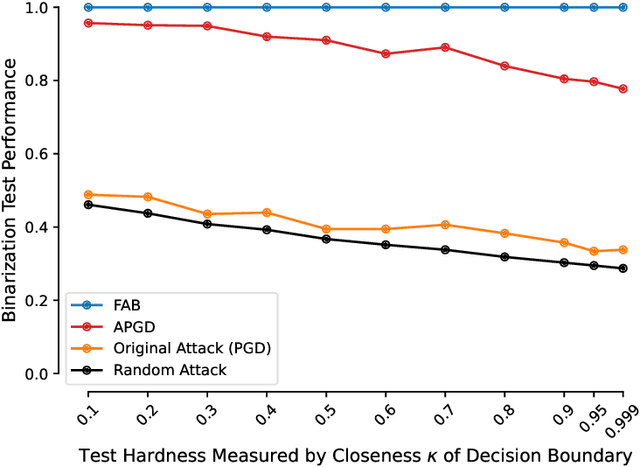
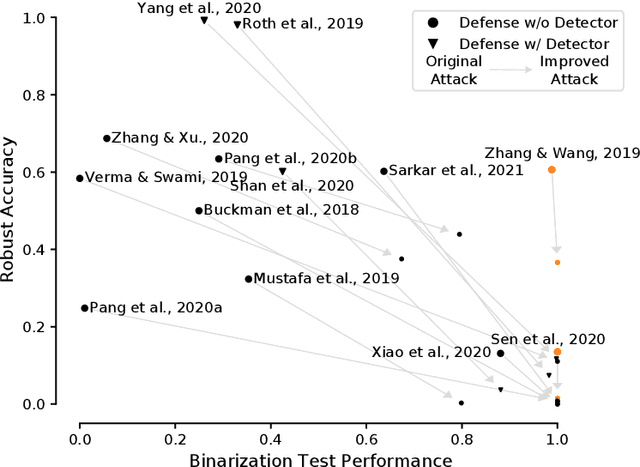
Hundreds of defenses have been proposed to make deep neural networks robust against minimal (adversarial) input perturbations. However, only a handful of these defenses held up their claims because correctly evaluating robustness is extremely challenging: Weak attacks often fail to find adversarial examples even if they unknowingly exist, thereby making a vulnerable network look robust. In this paper, we propose a test to identify weak attacks, and thus weak defense evaluations. Our test slightly modifies a neural network to guarantee the existence of an adversarial example for every sample. Consequentially, any correct attack must succeed in breaking this modified network. For eleven out of thirteen previously-published defenses, the original evaluation of the defense fails our test, while stronger attacks that break these defenses pass it. We hope that attack unit tests - such as ours - will be a major component in future robustness evaluations and increase confidence in an empirical field that is currently riddled with skepticism.
The Privacy Onion Effect: Memorization is Relative
Jun 22, 2022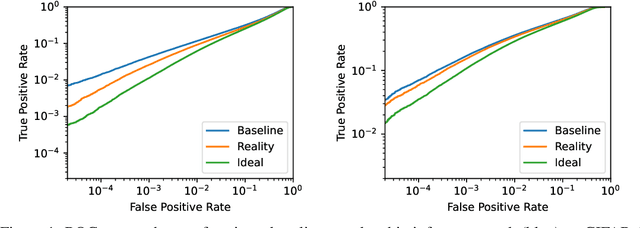
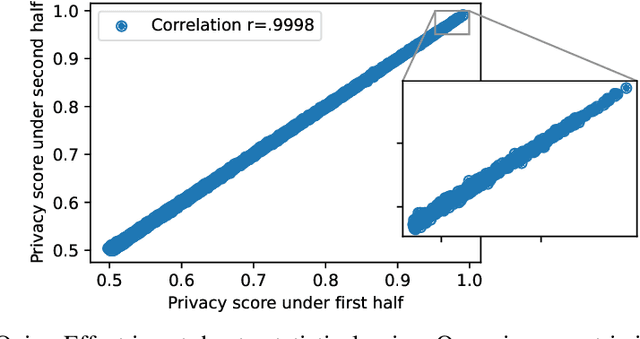
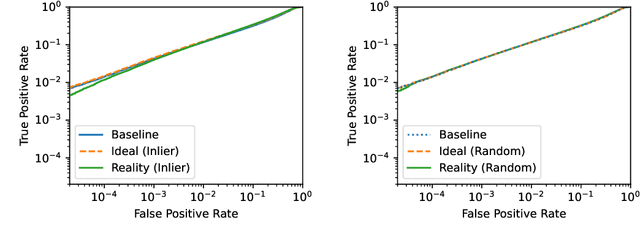
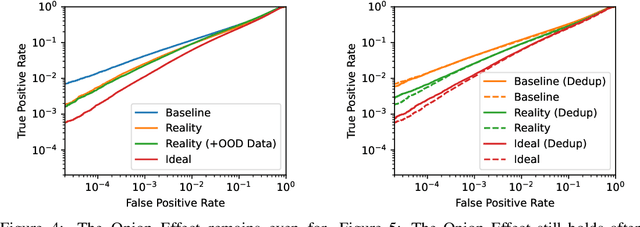
Machine learning models trained on private datasets have been shown to leak their private data. While recent work has found that the average data point is rarely leaked, the outlier samples are frequently subject to memorization and, consequently, privacy leakage. We demonstrate and analyse an Onion Effect of memorization: removing the "layer" of outlier points that are most vulnerable to a privacy attack exposes a new layer of previously-safe points to the same attack. We perform several experiments to study this effect, and understand why it occurs. The existence of this effect has various consequences. For example, it suggests that proposals to defend against memorization without training with rigorous privacy guarantees are unlikely to be effective. Further, it suggests that privacy-enhancing technologies such as machine unlearning could actually harm the privacy of other users.
(Certified!!) Adversarial Robustness for Free!
Jun 21, 2022
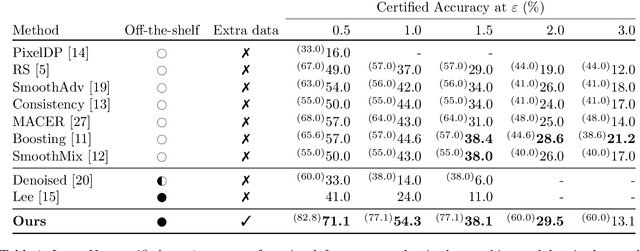
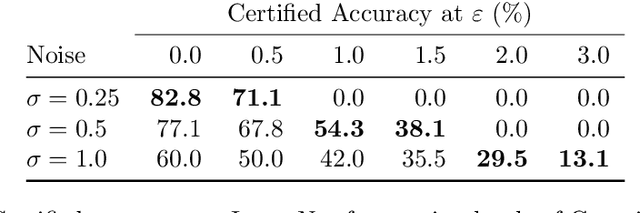
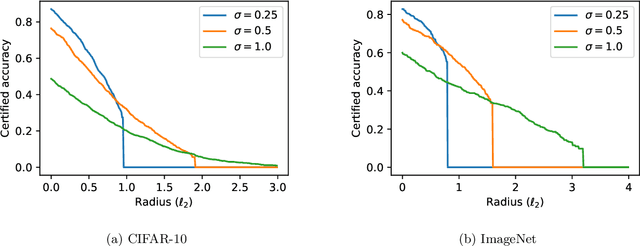
In this paper we show how to achieve state-of-the-art certified adversarial robustness to 2-norm bounded perturbations by relying exclusively on off-the-shelf pretrained models. To do so, we instantiate the denoised smoothing approach of Salman et al. by combining a pretrained denoising diffusion probabilistic model and a standard high-accuracy classifier. This allows us to certify 71% accuracy on ImageNet under adversarial perturbations constrained to be within a 2-norm of 0.5, an improvement of 14 percentage points over the prior certified SoTA using any approach, or an improvement of 30 percentage points over denoised smoothing. We obtain these results using only pretrained diffusion models and image classifiers, without requiring any fine tuning or retraining of model parameters.
Truth Serum: Poisoning Machine Learning Models to Reveal Their Secrets
Mar 31, 2022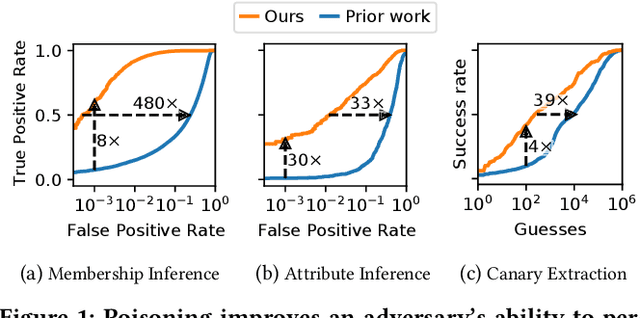
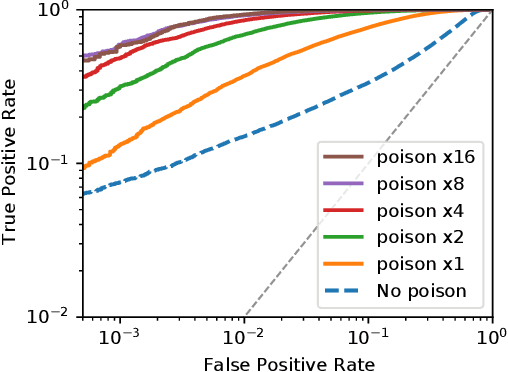
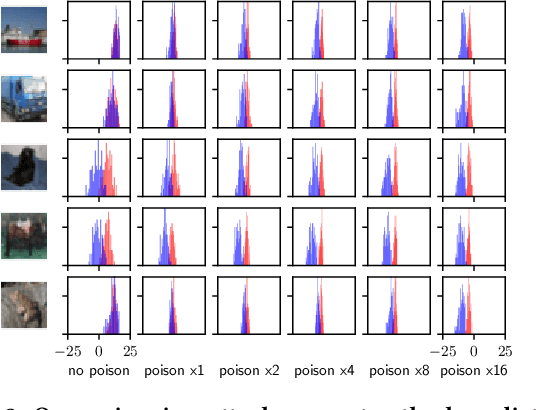
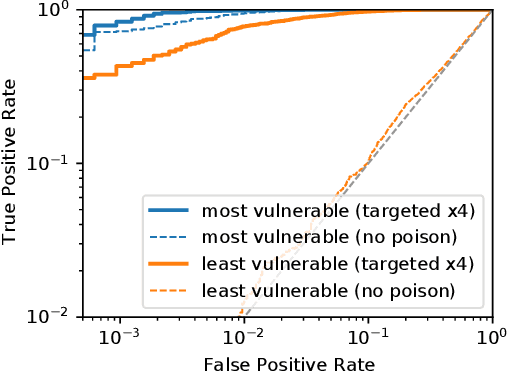
We introduce a new class of attacks on machine learning models. We show that an adversary who can poison a training dataset can cause models trained on this dataset to leak significant private details of training points belonging to other parties. Our active inference attacks connect two independent lines of work targeting the integrity and privacy of machine learning training data. Our attacks are effective across membership inference, attribute inference, and data extraction. For example, our targeted attacks can poison <0.1% of the training dataset to boost the performance of inference attacks by 1 to 2 orders of magnitude. Further, an adversary who controls a significant fraction of the training data (e.g., 50%) can launch untargeted attacks that enable 8x more precise inference on all other users' otherwise-private data points. Our results cast doubts on the relevance of cryptographic privacy guarantees in multiparty computation protocols for machine learning, if parties can arbitrarily select their share of training data.
Debugging Differential Privacy: A Case Study for Privacy Auditing
Mar 28, 2022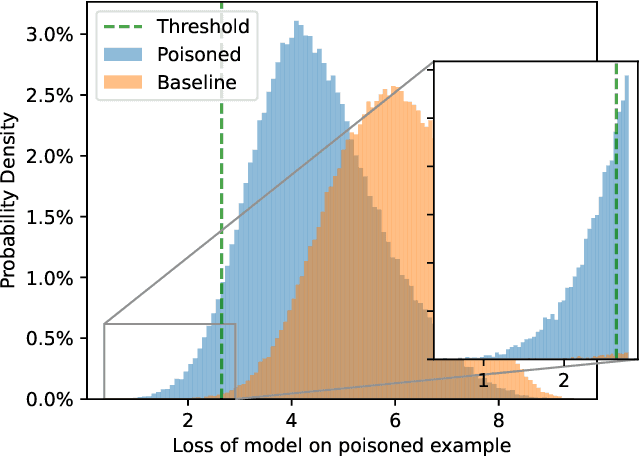
Differential Privacy can provide provable privacy guarantees for training data in machine learning. However, the presence of proofs does not preclude the presence of errors. Inspired by recent advances in auditing which have been used for estimating lower bounds on differentially private algorithms, here we show that auditing can also be used to find flaws in (purportedly) differentially private schemes. In this case study, we audit a recent open source implementation of a differentially private deep learning algorithm and find, with 99.99999999% confidence, that the implementation does not satisfy the claimed differential privacy guarantee.
Quantifying Memorization Across Neural Language Models
Feb 24, 2022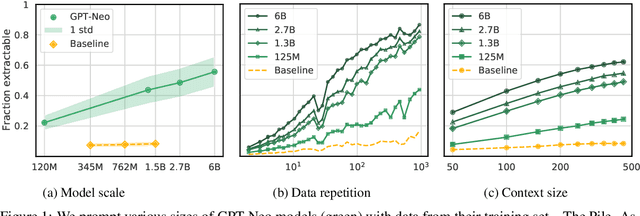
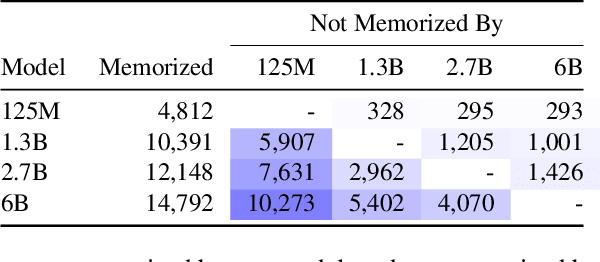
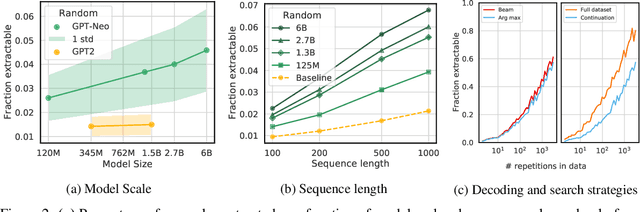
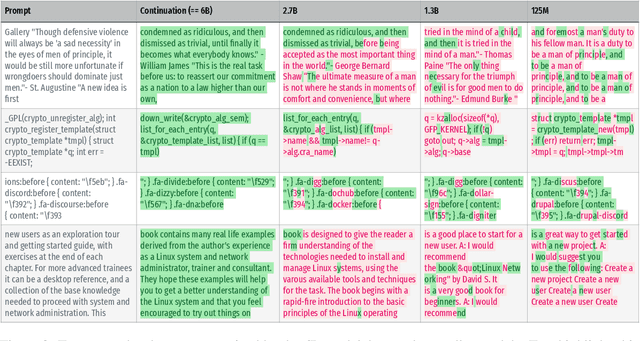
Large language models (LMs) have been shown to memorize parts of their training data, and when prompted appropriately, they will emit the memorized training data verbatim. This is undesirable because memorization violates privacy (exposing user data), degrades utility (repeated easy-to-memorize text is often low quality), and hurts fairness (some texts are memorized over others). We describe three log-linear relationships that quantify the degree to which LMs emit memorized training data. Memorization significantly grows as we increase (1) the capacity of a model, (2) the number of times an example has been duplicated, and (3) the number of tokens of context used to prompt the model. Surprisingly, we find the situation becomes complicated when generalizing these results across model families. On the whole, we find that memorization in LMs is more prevalent than previously believed and will likely get worse as models continues to scale, at least without active mitigations.
Counterfactual Memorization in Neural Language Models
Dec 24, 2021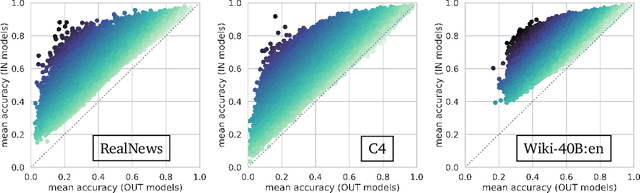
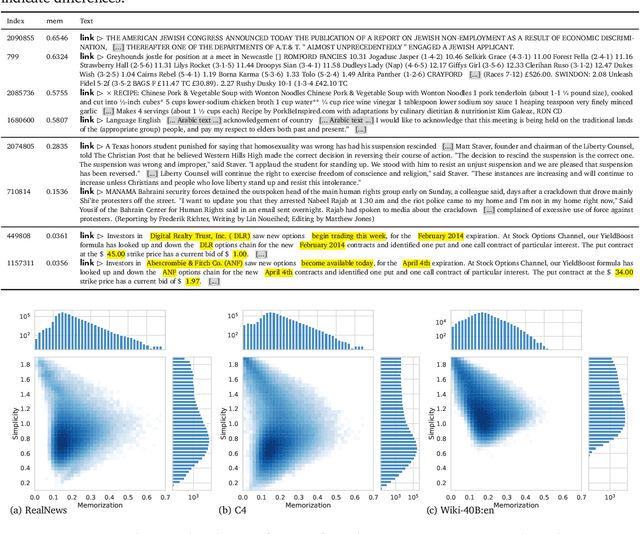

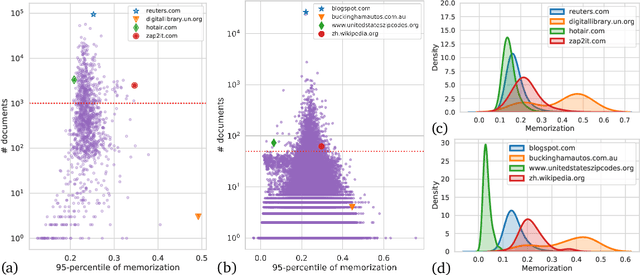
Modern neural language models widely used in tasks across NLP risk memorizing sensitive information from their training data. As models continue to scale up in parameters, training data, and compute, understanding memorization in language models is both important from a learning-theoretical point of view, and is practically crucial in real world applications. An open question in previous studies of memorization in language models is how to filter out "common" memorization. In fact, most memorization criteria strongly correlate with the number of occurrences in the training set, capturing "common" memorization such as familiar phrases, public knowledge or templated texts. In this paper, we provide a principled perspective inspired by a taxonomy of human memory in Psychology. From this perspective, we formulate a notion of counterfactual memorization, which characterizes how a model's predictions change if a particular document is omitted during training. We identify and study counterfactually-memorized training examples in standard text datasets. We further estimate the influence of each training example on the validation set and on generated texts, and show that this can provide direct evidence of the source of memorization at test time.
Membership Inference Attacks From First Principles
Dec 07, 2021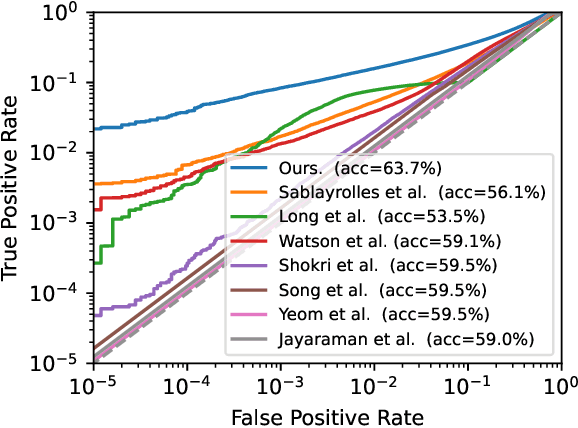
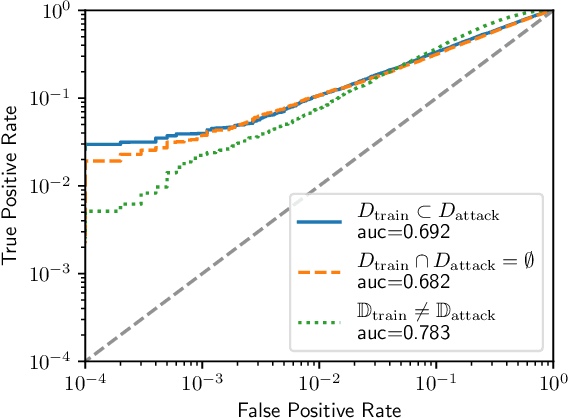
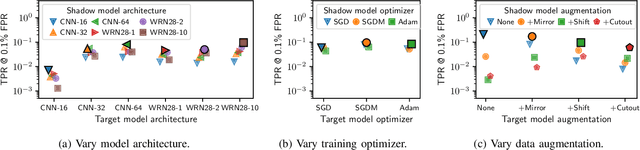
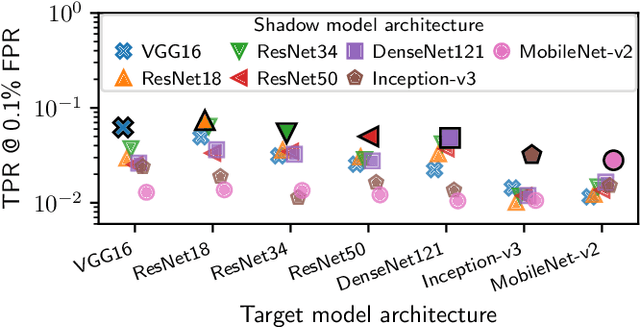
A membership inference attack allows an adversary to query a trained machine learning model to predict whether or not a particular example was contained in the model's training dataset. These attacks are currently evaluated using average-case "accuracy" metrics that fail to characterize whether the attack can confidently identify any members of the training set. We argue that attacks should instead be evaluated by computing their true-positive rate at low (e.g., <0.1%) false-positive rates, and find most prior attacks perform poorly when evaluated in this way. To address this we develop a Likelihood Ratio Attack (LiRA) that carefully combines multiple ideas from the literature. Our attack is 10x more powerful at low false-positive rates, and also strictly dominates prior attacks on existing metrics.