 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Only Membership Inference Attacks
Paper and Code
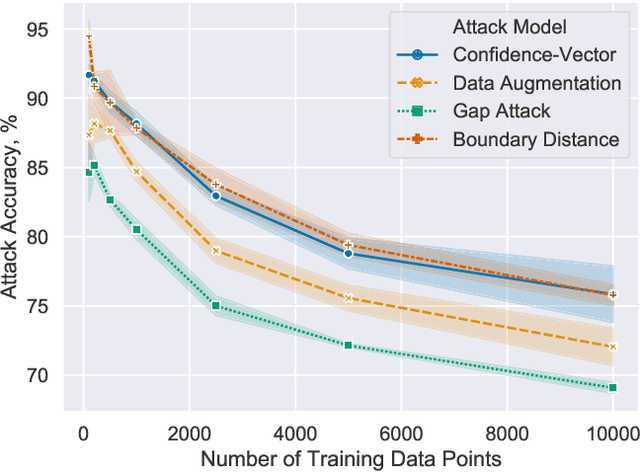
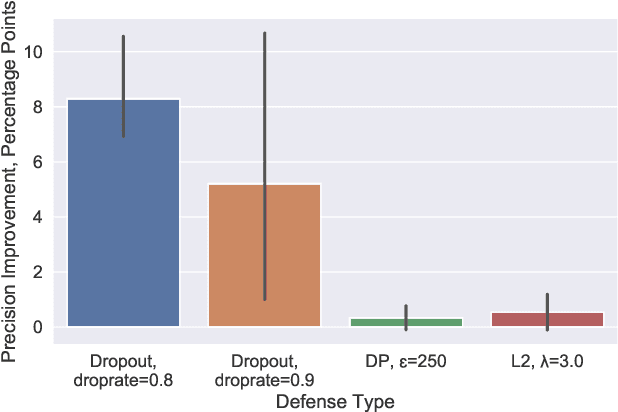
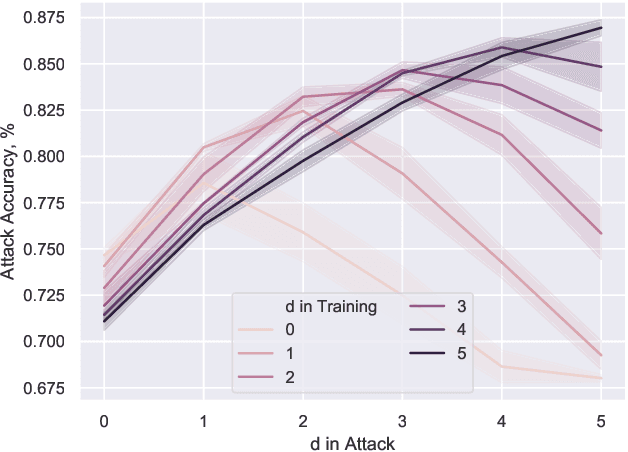
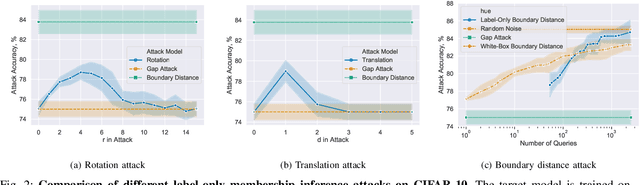
Membership inference attacks are one of the simplest forms of privacy leakage for machine learning models: given a data point and model, determine whether the point was used to train the model. Existing membership inference attacks exploit models' abnormal confidence when queried on their training data. These attacks do not apply if the adversary only gets access to models' predicted labels, without a confidence measure. In this paper, we introduce label-only membership inference attacks. Instead of relying on confidence scores, our attacks evaluate the robustness of a model's predicted labels under perturbations to obtain a fine-grained membership signal. These perturbations include common data augmentations or adversarial examples. We empirically show that our label-only membership inference attacks perform on par with prior attacks that required access to model confidences. We further demonstrate that label-only attacks break multiple defenses against membership inference attacks that (implicitly or explicitly) rely on a phenomenon we call confidence masking. These defenses modify a model's confidence scores in order to thwart attacks, but leave the model's predicted labels unchanged. Our label-only attacks demonstrate that confidence-masking is not a viable defense strategy against membership inference. Finally, we investigate worst-case label-only attacks, that infer membership for a small number of outlier data points. We show that label-only attacks also match confidence-based attacks in this setting. We find that training models with differential privacy and (strong) L2 regularization are the only known defense strategies that successfully prevents all attacks. This remains true even when the differential privacy budget is too high to offer meaningful provable guarantees.