 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDist-GAN: An Improved GAN using Distance Constraints
Jul 27, 2018


We introduce effective training algorithms for Generative Adversarial Networks (GAN) to alleviate mode collapse and gradient vanishing. In our system, we constrain the generator by an Autoencoder (AE). We propose a formulation to consider the reconstructed samples from AE as "real" samples for the discriminator. This couples the convergence of the AE with that of the discriminator, effectively slowing down the convergence of discriminator and reducing gradient vanishing. Importantly, we propose two novel distance constraints to improve the generator. First, we propose a latent-data distance constraint to enforce compatibility between the latent sample distances and the corresponding data sample distances. We use this constraint to explicitly prevent the generator from mode collapse. Second, we propose a discriminator-score distance constraint to align the distribution of the generated samples with that of the real samples through the discriminator score. We use this constraint to guide the generator to synthesize samples that resemble the real ones. Our proposed GAN using these distance constraints, namely Dist-GAN, can achieve better results than state-of-the-art methods across benchmark datasets: synthetic, MNIST, MNIST-1K, CelebA, CIFAR-10 and STL-10 datasets. Our code is published here (https://github.com/tntrung/gan) for research.
From Selective Deep Convolutional Features to Compact Binary Representations for Image Retrieval
Jul 20, 2018


In the large-scale image retrieval task, the two most important requirements are the discriminability of image representations and the efficiency in computation and storage of representations. Regarding the former requirement, Convolutional Neural Network (CNN) is proven to be a very powerful tool to extract highly discriminative local descriptors for effective image search. Additionally, in order to further improve the discriminative power of the descriptors, recent works adopt fine-tuned strategies. In this paper, taking a different approach, we propose a novel, computationally efficient, and competitive framework. Specifically, we firstly propose various strategies to compute masks, namely SIFT-mask, SUM-mask, and MAX-mask, to select a representative subset of local convolutional features and eliminate redundant features. Our in-depth analyses demonstrate that proposed masking schemes are effective to address the burstiness drawback and improve retrieval accuracy. Secondly, we propose to employ recent embedding and aggregating methods which can significantly boost the feature discriminability. Regarding the computation and storage efficiency, we include a hashing module to produce very compact binary image representations. Extensive experiments on six image retrieval benchmarks demonstrate that our proposed framework achieves the state-of-the-art retrieval performances.
Simultaneous Compression and Quantization: A Joint Approach for Efficient Unsupervised Hashing
Jul 18, 2018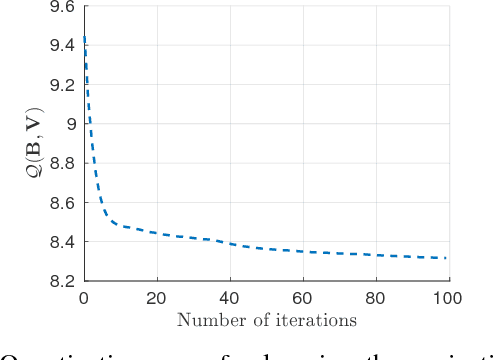
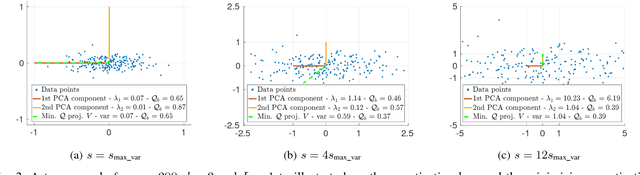
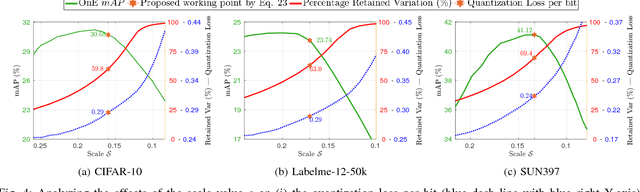
For unsupervised data-dependent hashing, the two most important requirements are to preserve similarity in the low-dimensional feature space and to minimize the binary quantization loss. A well-established hashing approach is Iterative Quantization (ITQ), which addresses these two requirements in separate steps. In this paper, we revisit the ITQ approach and propose novel formulations and algorithms to the problem. Specifically, we propose a novel approach, named Simultaneous Compression and Quantization (SCQ), to jointly learn to compress (reduce dimensionality) and binarize input data in a single formulation under strict orthogonal constraint. With this approach, we introduce a loss function and its relaxed version, termed Orthonormal Encoder (OnE) and Orthogonal Encoder (OgE) respectively, which involve challenging binary and orthogonal constraints. We propose to attack the optimization using novel algorithms based on recent advances in cyclic coordinate descent approach. Comprehensive experiments on unsupervised image retrieval demonstrate that our proposed methods consistently outperform other state-of-the-art hashing methods. Notably, our proposed methods outperform recent deep neural networks and GAN based hashing in accuracy, while being very computationally-efficient.
Efficient and Deep Person Re-Identification using Multi-Level Similarity
Apr 02, 2018
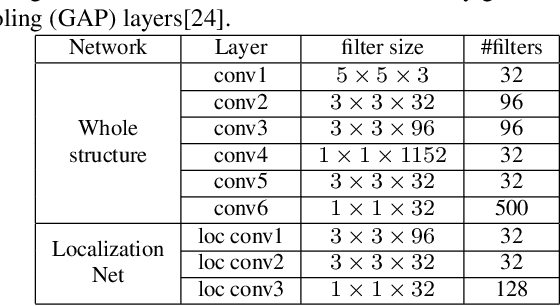
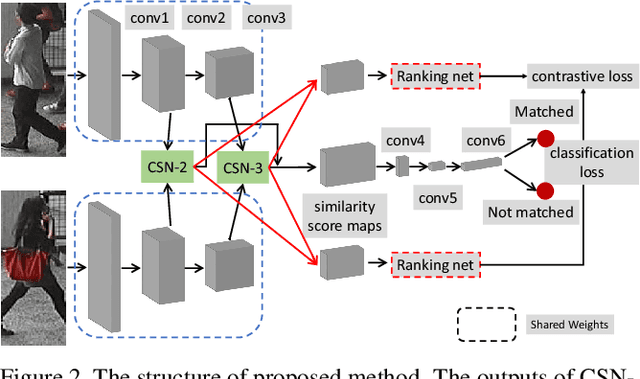
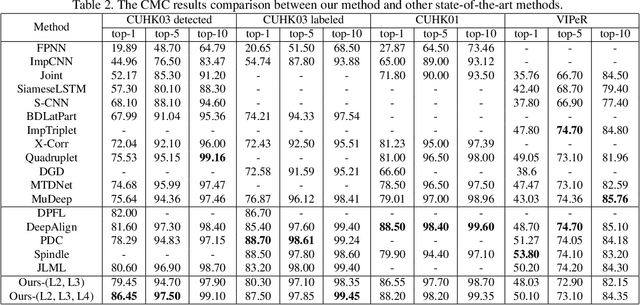
Person Re-Identification (ReID) requires comparing two images of person captured under different conditions. Existing work based on neural networks often computes the similarity of feature maps from one single convolutional layer. In this work, we propose an efficient, end-to-end fully convolutional Siamese network that computes the similarities at multiple levels. We demonstrate that multi-level similarity can improve the accuracy considerably using low-complexity network structures in ReID problem. Specifically, first, we use several convolutional layers to extract the features of two input images. Then, we propose Convolution Similarity Network to compute the similarity score maps for the inputs. We use spatial transformer networks (STNs) to determine spatial attention. We propose to apply efficient depth-wise convolution to compute the similarity. The proposed Convolution Similarity Networks can be inserted into different convolutional layers to extract visual similarities at different levels. Furthermore, we use an improved ranking loss to further improve the performance. Our work is the first to propose to compute visual similarities at low, middle and high levels for ReID. With extensive experiments and analysis, we demonstrate that our system, compact yet effective, can achieve competitive results with much smaller model size and computational complexity.
Fine-grained wound tissue analysis using deep neural network
Feb 28, 2018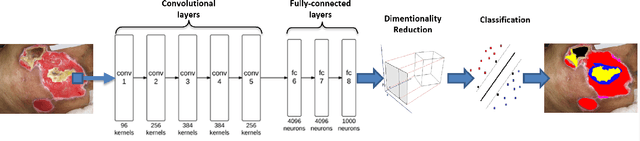
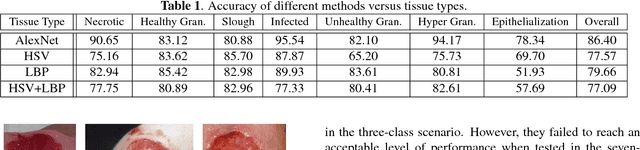

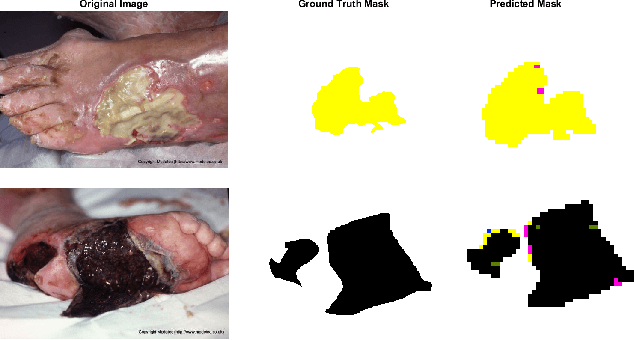
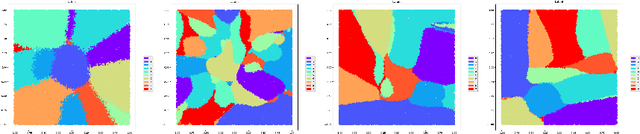
Tissue assessment for chronic wounds is the basis of wound grading and selection of treatment approaches. While several image processing approaches have been proposed for automatic wound tissue analysis, there has been a shortcoming in these approaches for clinical practices. In particular, seemingly, all previous approaches have assumed only 3 tissue types in the chronic wounds, while these wounds commonly exhibit 7 distinct tissue types that presence of each one changes the treatment procedure. In this paper, for the first time, we investigate the classification of 7 wound issue types. We work with wound professionals to build a new database of 7 types of wound tissue. We propose to use pre-trained deep neural networks for feature extraction and classification at the patch-level. We perform experiments to demonstrate that our approach outperforms other state-of-the-art. We will make our database publicly available to facilitate research in wound assessment.
On-device Scalable Image-based Localization
Feb 10, 2018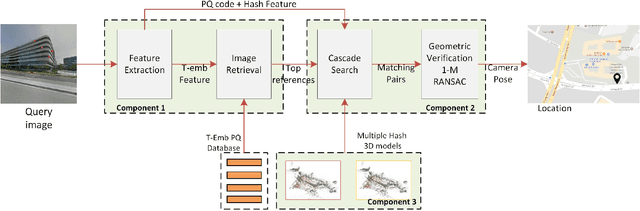

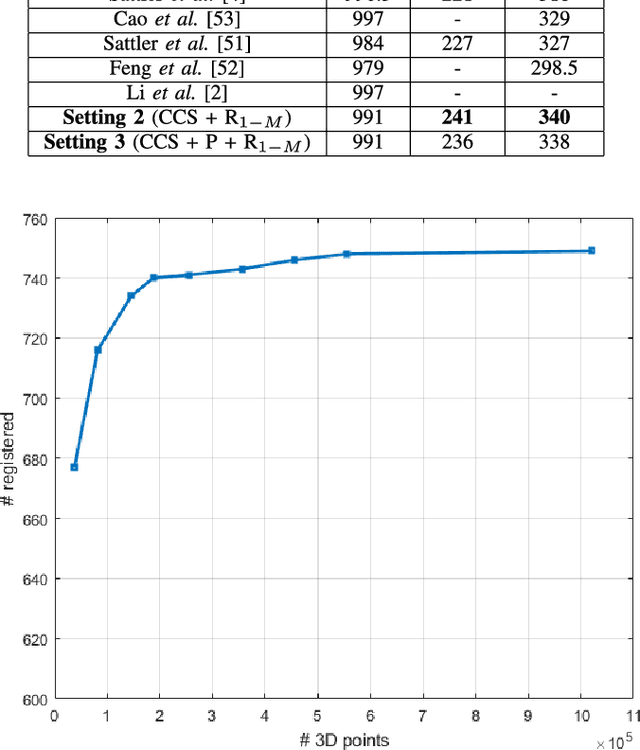

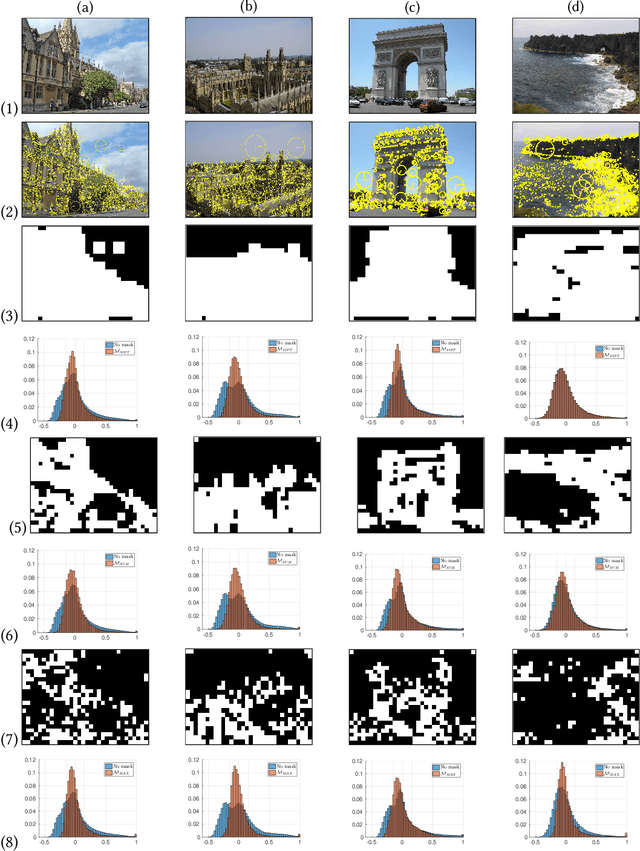
We present the scalable design of an entire on-device system for large-scale urban localization. The proposed design integrates compact image retrieval and 2D-3D correspondence search to estimate the camera pose in a city region of extensive coverage. Our design is GPS agnostic and does not require the network connection. The system explores the use of an abundant dataset: Google Street View (GSV). In order to overcome the resource constraints of mobile devices, we carefully optimize the system design at every stage: we use state-of-the-art image retrieval to quickly locate candidate regions and limit candidate 3D points; we propose a new hashing-based approach for fast computation of 2D-3D correspondences and new one-many RANSAC for accurate pose estimation. The experiments are conducted on benchmark datasets for 2D-3D correspondence search and on a database of over 227K Google Street View (GSV) images for the overall system. Results show that our 2D-3D correspondence search achieves state-of-the-art performance on some benchmark datasets and our system can accurately and quickly localize mobile images; the median error is less than 4 meters and the processing time is averagely less than 10s on a typical mobile device.
Compact Hash Code Learning with Binary Deep Neural Network
Feb 06, 2018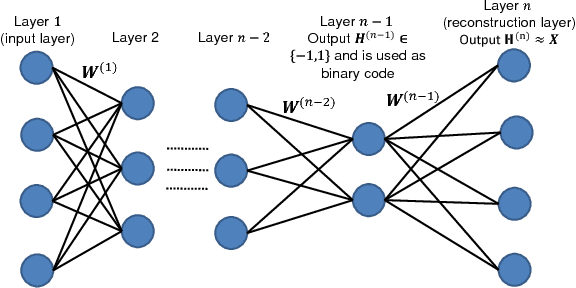
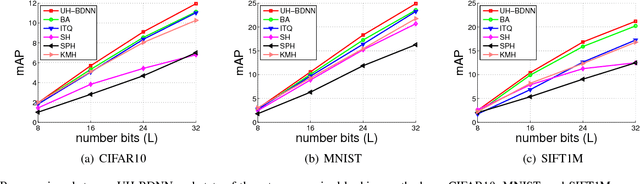
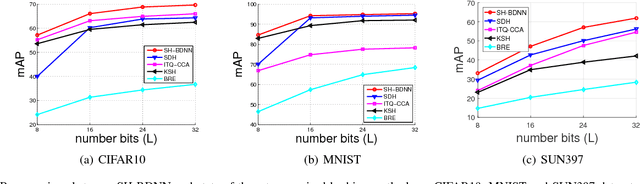
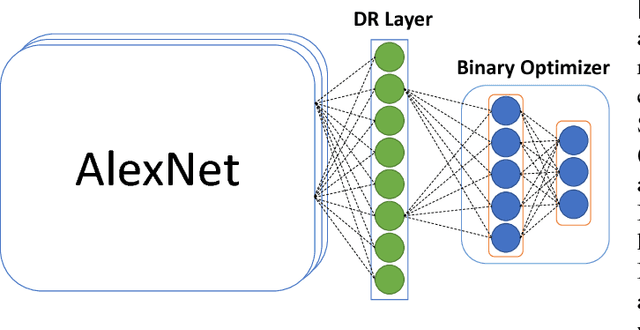
In this work, we firstly propose deep network models and learning algorithms for learning binary hash codes given image representations under both unsupervised and supervised manners. Then, by leveraging the powerful capacity of convolutional neural networks, we propose an end-to-end architecture which jointly learns to extract visual features and produce binary hash codes. Our novel network designs constrain one hidden layer to directly output the binary codes. This addresses a challenging issue in some previous works: optimizing nonsmooth objective functions due to binarization. Additionally, we incorporate independence and balance properties in the direct and strict forms into the learning schemes. Furthermore, we also include similarity preserving property in our objective functions. Our resulting optimizations involving these binary, independence, and balance constraints are difficult to solve. We propose to attack them with alternating optimization and careful relaxation. Experimental results on the benchmark datasets show that our proposed methods compare favorably with the state of the art.
Aircraft Fuselage Defect Detection using Deep Neural Networks
Dec 26, 2017

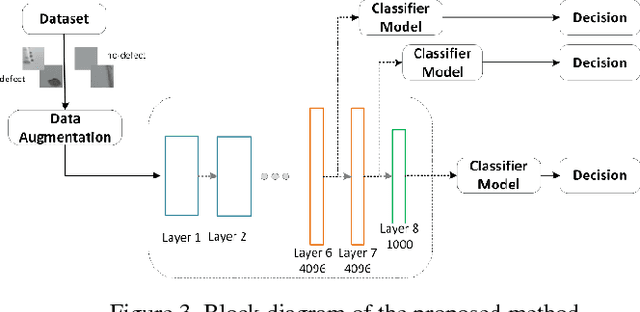
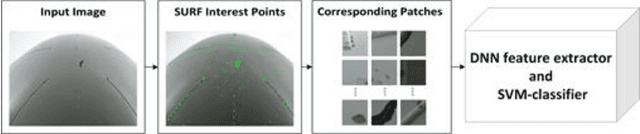
To ensure flight safety of aircraft structures, it is necessary to have regular maintenance using visual and nondestructive inspection (NDI) methods. In this paper, we propose an automatic image-based aircraft defect detection using Deep Neural Networks (DNNs). To the best of our knowledge, this is the first work for aircraft defect detection using DNNs. We perform a comprehensive evaluation of state-of-the-art feature descriptors and show that the best performance is achieved by vgg-f DNN as feature extractor with a linear SVM classifier. To reduce the processing time, we propose to apply SURF key point detector to identify defect patch candidates. Our experiment results suggest that we can achieve over 96% accuracy at around 15s processing time for a high-resolution (20-megapixel) image on a laptop.
Adaptive Quantization for Deep Neural Network
Dec 04, 2017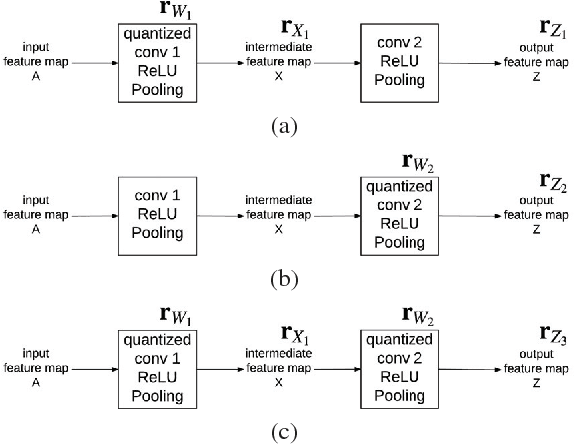
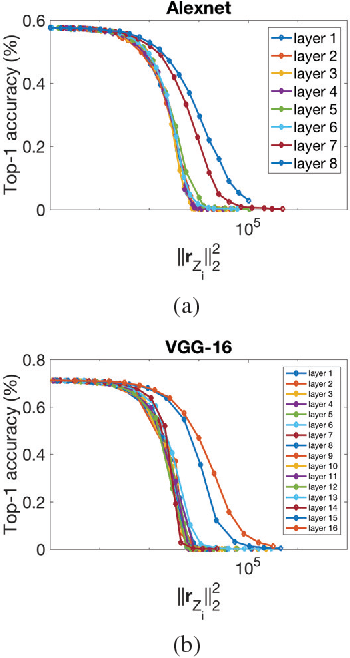
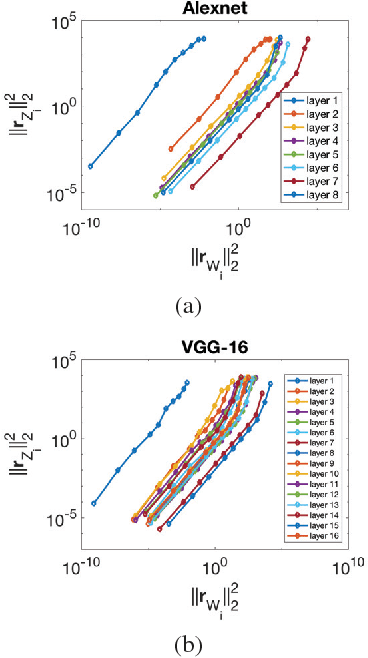
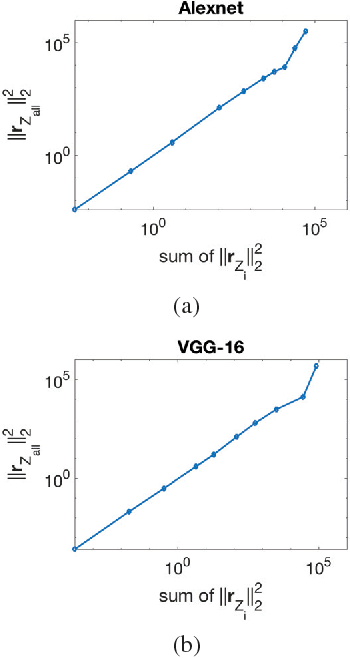
In recent years Deep Neural Networks (DNNs) have been rapidly developed in various applications, together with increasingly complex architectures. The performance gain of these DNNs generally comes with high computational costs and large memory consumption, which may not be affordable for mobile platforms. Deep model quantization can be used for reducing the computation and memory costs of DNNs, and deploying complex DNNs on mobile equipment. In this work, we propose an optimization framework for deep model quantization. First, we propose a measurement to estimate the effect of parameter quantization errors in individual layers on the overall model prediction accuracy. Then, we propose an optimization process based on this measurement for finding optimal quantization bit-width for each layer. This is the first work that theoretically analyse the relationship between parameter quantization errors of individual layers and model accuracy. Our new quantization algorithm outperforms previous quantization optimization methods, and achieves 20-40% higher compression rate compared to equal bit-width quantization at the same model prediction accuracy.
Selective Deep Convolutional Features for Image Retrieval
Nov 27, 2017
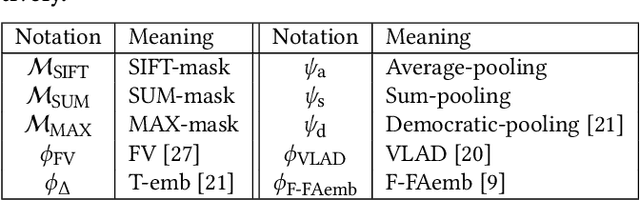


Convolutional Neural Network (CNN) is a very powerful approach to extract discriminative local descriptors for effective image search. Recent work adopts fine-tuned strategies to further improve the discriminative power of the descriptors. Taking a different approach, in this paper, we propose a novel framework to achieve competitive retrieval performance. Firstly, we propose various masking schemes, namely SIFT-mask, SUM-mask, and MAX-mask, to select a representative subset of local convolutional features and remove a large number of redundant features. We demonstrate that this can effectively address the burstiness issue and improve retrieval accuracy. Secondly, we propose to employ recent embedding and aggregating methods to further enhance feature discriminability. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art retrieval accuracy.