 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace-Constrained Federated Learning with Low-Rank Adaptation
Jun 21, 2026Federated low-rank adaptation methods are attractive for fine-tuning large models under communication and privacy constraints, but heterogeneous client data can induce geometric misalignment between local low-rank updates. We study whether this subspace misalignment leads to destructive aggregation and slower convergence in LoRA-based federated learning. We propose a subspace-regularized federated LoRA objective that encourages local client updates to remain close to a shared global reference subspace. We present a complete empirical evaluation on two pretrained models, RoBERTa-large and SmolLM-360M, over HellaSwag in a non-IID 10-client federated setting, across 3 random seeds (42, 43, 44), yielding 24 total experimental runs (4 methods x 3 seeds x 2 models). On RoBERTa-large, Subspace-Reg achieves the strongest mean best accuracy (0.454 +/- 0.023), mean final accuracy (0.429 +/- 0.011), and lowest final loss (1.363) across all three seeds, outperforming FedAvg, SVD redistribution, and FedSVD baselines by a large margin. On SmolLM-360M, FedAvg leads on accuracy, revealing that accuracy gains are model-dependent. Crucially, Subspace-Reg achieves near-perfect basis overlap, approximately 0.9999, on both models and across all seeds, versus 0.958 to 0.991 for all baselines, providing robust support for the geometric alignment hypothesis. The code is publicly available at https://github.com/sadia-sigma-lab/Subspace-Constrained-Federated-learning-with-Lora.
GAUSS: Guided Encoder-Decoder Architecture for Hyperspectral Unmixing with Spatial Smoothness
Apr 16, 2022
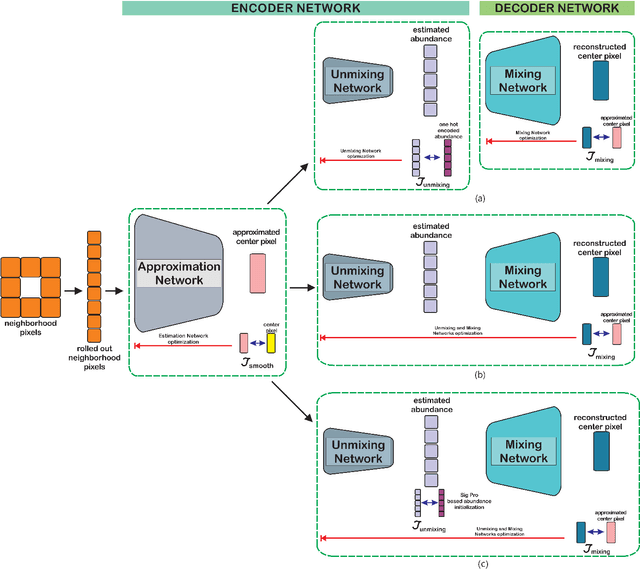

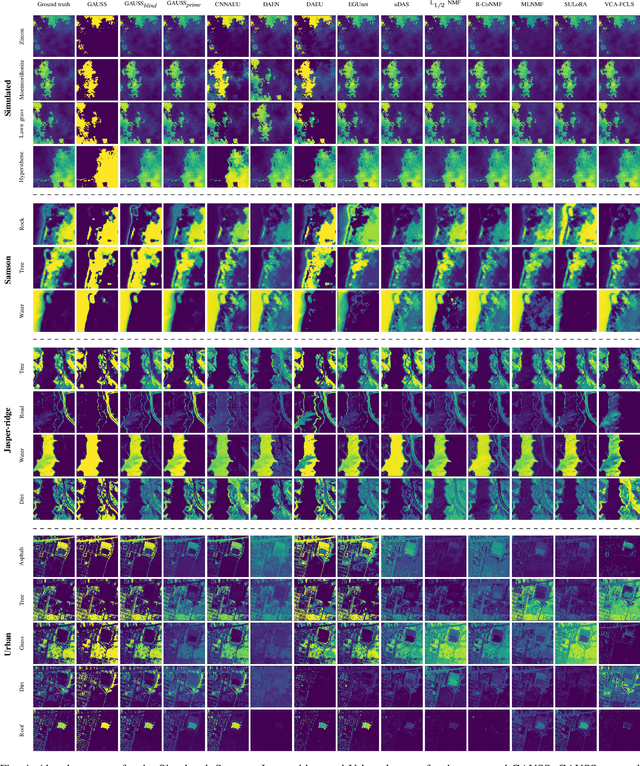
In recent hyperspectral unmixing (HU) literature, the application of deep learning (DL) has become more prominent, especially with the autoencoder (AE) architecture. We propose a split architecture and use a pseudo-ground truth for abundances to guide the `unmixing network' (UN) optimization. Preceding the UN, an `approximation network' (AN) is proposed, which will improve the association between the centre pixel and its neighbourhood. Hence, it will accentuate spatial correlation in the abundances as its output is the input to the UN and the reference for the `mixing network' (MN). In the Guided Encoder-Decoder Architecture for Hyperspectral Unmixing with Spatial Smoothness (GAUSS), we proposed using one-hot encoded abundances as the pseudo-ground truth to guide the UN; computed using the k-means algorithm to exclude the use of prior HU methods. Furthermore, we release the single-layer constraint on MN by introducing the UN generated abundances in contrast to the standard AE for HU. Secondly, we experimented with two modifications on the pre-trained network using the GAUSS method. In GAUSS$_\textit{blind}$, we have concatenated the UN and the MN to back-propagate the reconstruction error gradients to the encoder. Then, in the GAUSS$_\textit{prime}$, abundance results of a signal processing (SP) method with reliable abundance results were used as the pseudo-ground truth with the GAUSS architecture. According to quantitative and graphical results for four experimental datasets, the three architectures either transcended or equated the performance of existing HU algorithms from both DL and SP domains.