 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Understand What We Cannot Say? Measuring Multilevel Alignment Through Abortion Stigma Across Cognitive, Interpersonal, and Structural Levels
Dec 22, 2025



As large language models increasingly mediate stigmatized health decisions, their capacity to genuinely understand complex psychological and physiological phenomena remains poorly evaluated. Can AI understand what we cannot say? We investigate whether LLMs coherently represent abortion stigma across the cognitive, interpersonal, and structural levels where it operates. We systematically tested 627 demographically diverse personas across five leading LLMs using the validated Individual Level Abortion Stigma Scale (ILAS). Our multilevel analysis examined whether models coherently represent stigma at the cognitive level (self-judgment), interpersonal level (worries about judgment and isolation), and structural level (community condemnation and disclosure patterns), as well as overall stigma. Models fail tests of genuine understanding across all levels. They overestimate interpersonal stigma while underestimating cognitive stigma, assume uniform community condemnation, introduce demographic biases absent from human validation data, miss the empirically validated stigma-secrecy relationship, and contradict themselves within theoretical constructs. These patterns reveal that current alignment approaches ensure appropriate language but not coherent multilevel understanding. This work provides empirical evidence that current LLMs lack coherent multilevel understanding of psychological and physiological constructs. AI safety in high-stakes contexts demands new approaches to design (multilevel coherence), evaluation (continuous auditing), governance and regulation (mandatory audits, accountability, deployment restrictions), and AI literacy in domains where understanding what people cannot say determines whether support helps or harms.
VizNet: Towards A Large-Scale Visualization Learning and Benchmarking Repository
May 12, 2019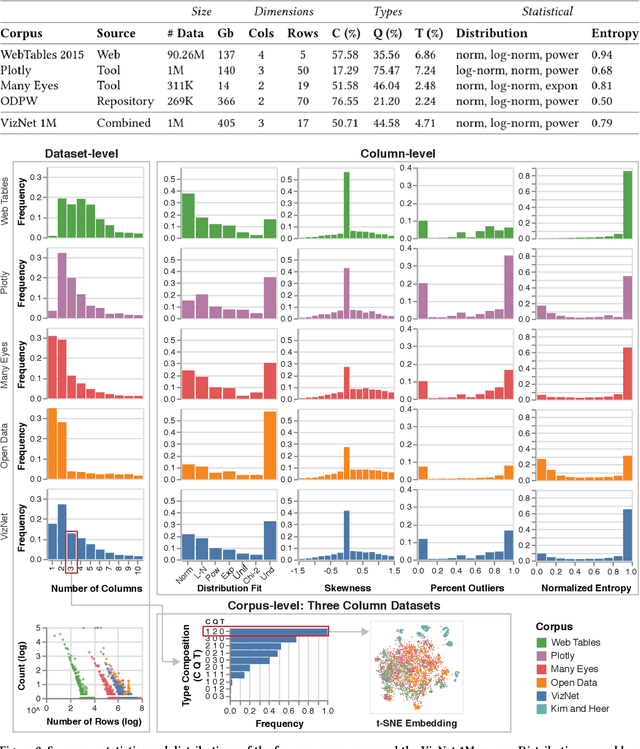
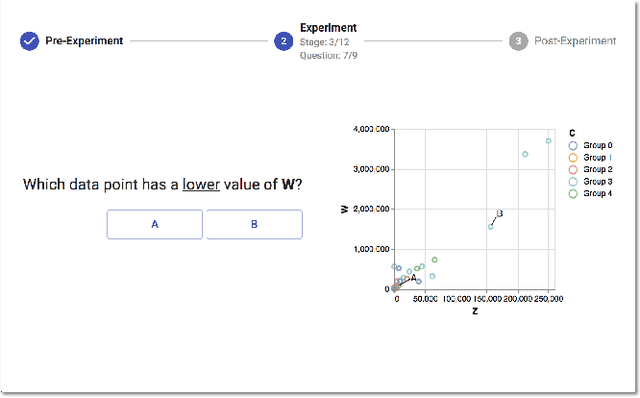
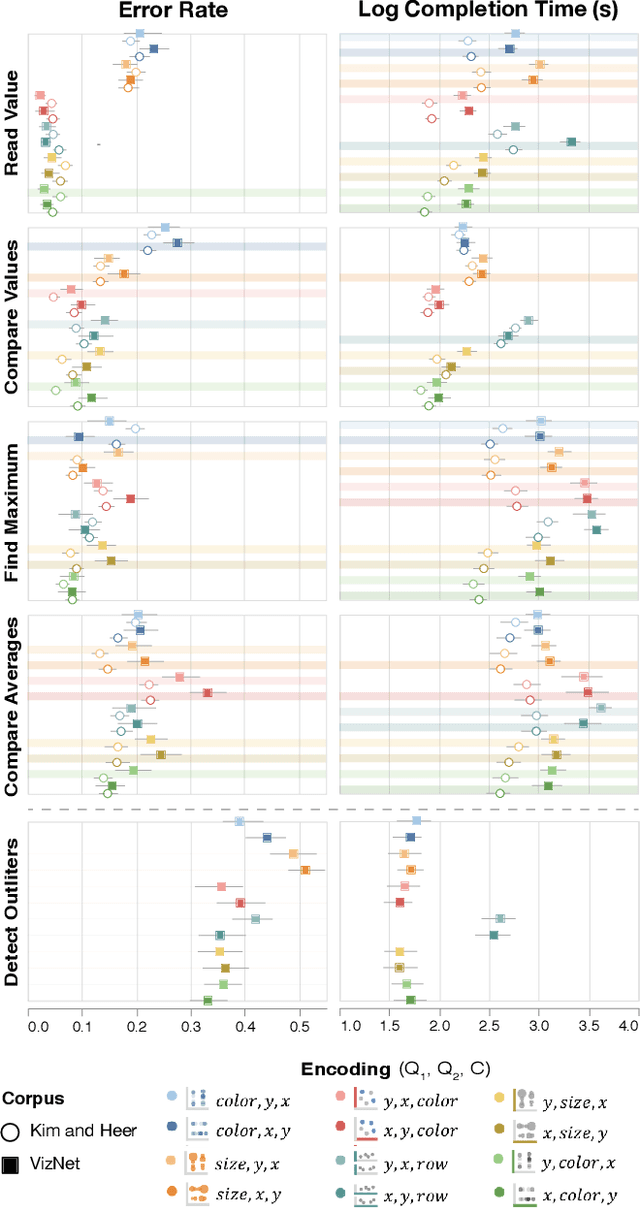
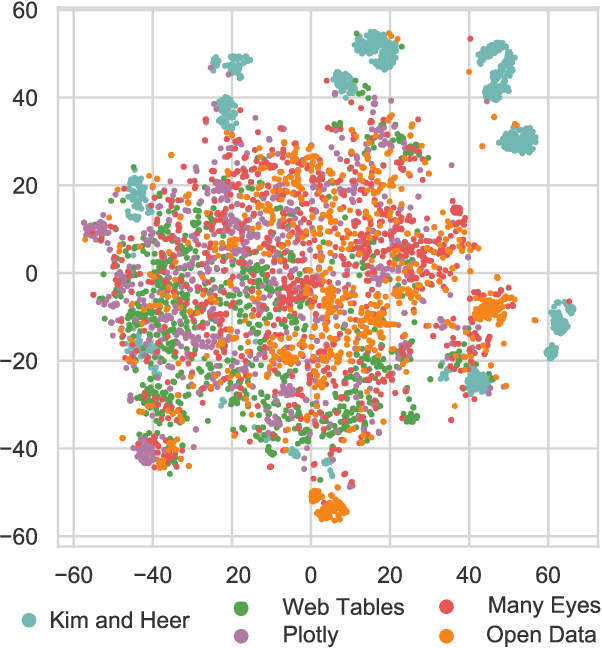
Researchers currently rely on ad hoc datasets to train automated visualization tools and evaluate the effectiveness of visualization designs. These exemplars often lack the characteristics of real-world datasets, and their one-off nature makes it difficult to compare different techniques. In this paper, we present VizNet: a large-scale corpus of over 31 million datasets compiled from open data repositories and online visualization galleries. On average, these datasets comprise 17 records over 3 dimensions and across the corpus, we find 51% of the dimensions record categorical data, 44% quantitative, and only 5% temporal. VizNet provides the necessary common baseline for comparing visualization design techniques, and developing benchmark models and algorithms for automating visual analysis. To demonstrate VizNet's utility as a platform for conducting online crowdsourced experiments at scale, we replicate a prior study assessing the influence of user task and data distribution on visual encoding effectiveness, and extend it by considering an additional task: outlier detection. To contend with running such studies at scale, we demonstrate how a metric of perceptual effectiveness can be learned from experimental results, and show its predictive power across test datasets.