 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's the Harm? Sharp Bounds on the Fraction Negatively Affected by Treatment
May 20, 2022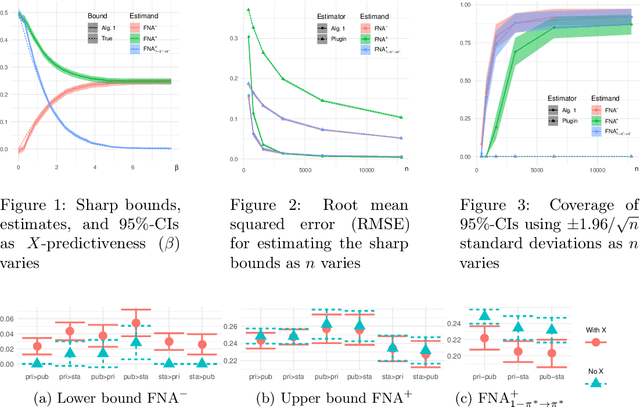
The fundamental problem of causal inference -- that we never observe counterfactuals -- prevents us from identifying how many might be negatively affected by a proposed intervention. If, in an A/B test, half of users click (or buy, or watch, or renew, etc.), whether exposed to the standard experience A or a new one B, hypothetically it could be because the change affects no one, because the change positively affects half the user population to go from no-click to click while negatively affecting the other half, or something in between. While unknowable, this impact is clearly of material importance to the decision to implement a change or not, whether due to fairness, long-term, systemic, or operational considerations. We therefore derive the tightest-possible (i.e., sharp) bounds on the fraction negatively affected (and other related estimands) given data with only factual observations, whether experimental or observational. Naturally, the more we can stratify individuals by observable covariates, the tighter the sharp bounds. Since these bounds involve unknown functions that must be learned from data, we develop a robust inference algorithm that is efficient almost regardless of how and how fast these functions are learned, remains consistent when some are mislearned, and still gives valid conservative bounds when most are mislearned. Our methodology altogether therefore strongly supports credible conclusions: it avoids spuriously point-identifying this unknowable impact, focusing on the best bounds instead, and it permits exceedingly robust inference on these. We demonstrate our method in simulation studies and in a case study of career counseling for the unemployed.
Estimating Structural Disparities for Face Models
Apr 13, 2022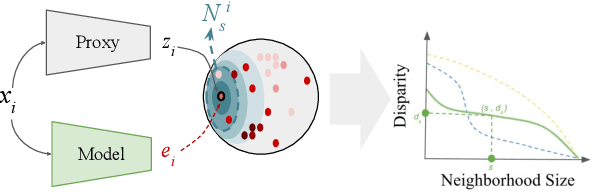
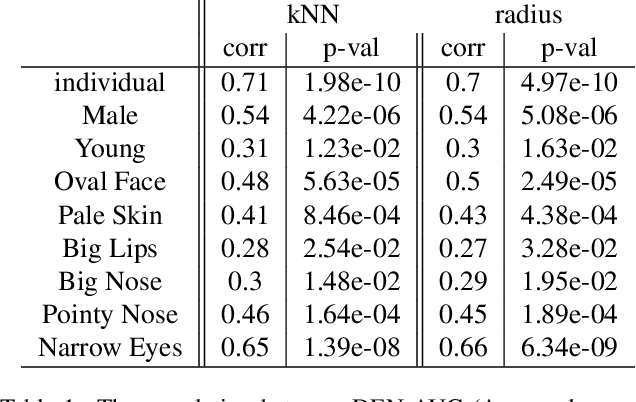

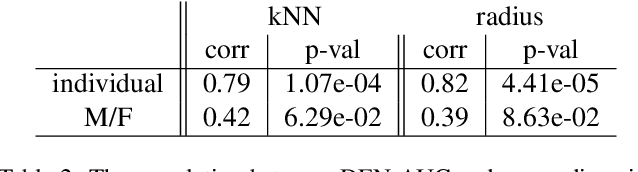
In machine learning, disparity metrics are often defined by measuring the difference in the performance or outcome of a model, across different sub-populations (groups) of datapoints. Thus, the inputs to disparity quantification consist of a model's predictions $\hat{y}$, the ground-truth labels for the predictions $y$, and group labels $g$ for the data points. Performance of the model for each group is calculated by comparing $\hat{y}$ and $y$ for the datapoints within a specific group, and as a result, disparity of performance across the different groups can be calculated. In many real world scenarios however, group labels ($g$) may not be available at scale during training and validation time, or collecting them might not be feasible or desirable as they could often be sensitive information. As a result, evaluating disparity metrics across categorical groups would not be feasible. On the other hand, in many scenarios noisy groupings may be obtainable using some form of a proxy, which would allow measuring disparity metrics across sub-populations. Here we explore performing such analysis on computer vision models trained on human faces, and on tasks such as face attribute prediction and affect estimation. Our experiments indicate that embeddings resulting from an off-the-shelf face recognition model, could meaningfully serve as a proxy for such estimation.
Doubly Robust Distributionally Robust Off-Policy Evaluation and Learning
Feb 19, 2022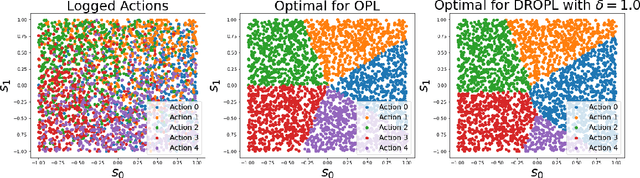
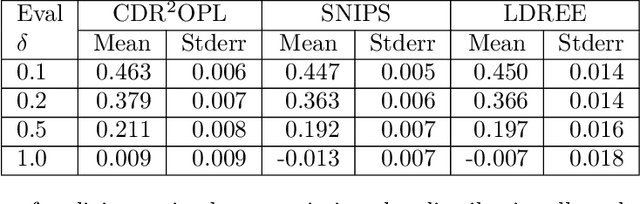
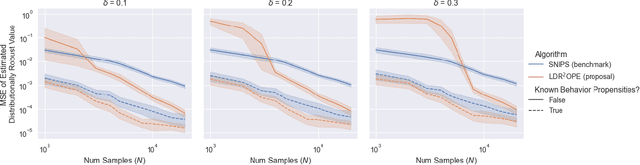
Off-policy evaluation and learning (OPE/L) use offline observational data to make better decisions, which is crucial in applications where experimentation is necessarily limited. OPE/L is nonetheless sensitive to discrepancies between the data-generating environment and that where policies are deployed. Recent work proposed distributionally robust OPE/L (DROPE/L) to remedy this, but the proposal relies on inverse-propensity weighting, whose regret rates may deteriorate if propensities are estimated and whose variance is suboptimal even if not. For vanilla OPE/L, this is solved by doubly robust (DR) methods, but they do not naturally extend to the more complex DROPE/L, which involves a worst-case expectation. In this paper, we propose the first DR algorithms for DROPE/L with KL-divergence uncertainty sets. For evaluation, we propose Localized Doubly Robust DROPE (LDR$^2$OPE) and prove its semiparametric efficiency under weak product rates conditions. Notably, thanks to a localization technique, LDR$^2$OPE only requires fitting a small number of regressions, just like DR methods for vanilla OPE. For learning, we propose Continuum Doubly Robust DROPL (CDR$^2$OPL) and show that, under a product rate condition involving a continuum of regressions, it enjoys a fast regret rate of $\mathcal{O}(N^{-1/2})$ even when unknown propensities are nonparametrically estimated. We further extend our results to general $f$-divergence uncertainty sets. We illustrate the advantage of our algorithms in simulations.
Long-term Causal Inference Under Persistent Confounding via Data Combination
Feb 15, 2022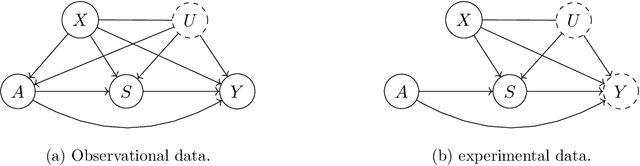
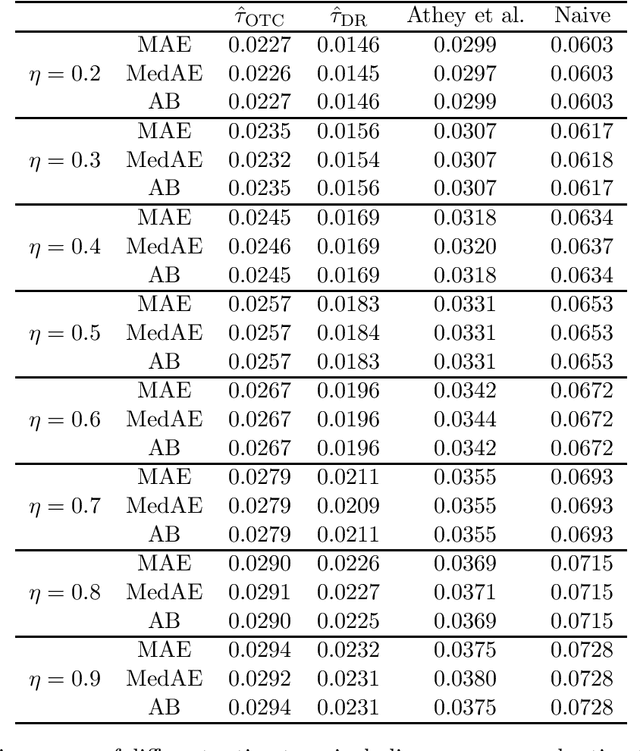
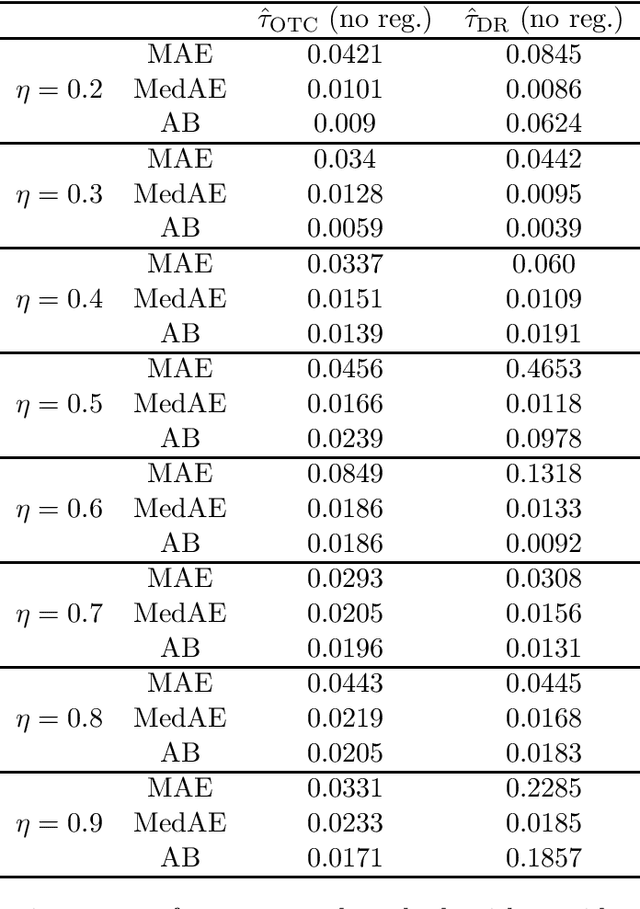
We study the identification and estimation of long-term treatment effects when both experimental and observational data are available. Since the long-term outcome is observed only after a long delay, it is not measured in the experimental data, but only recorded in the observational data. However, both types of data include observations of some short-term outcomes. In this paper, we uniquely tackle the challenge of persistent unmeasured confounders, i.e., some unmeasured confounders that can simultaneously affect the treatment, short-term outcomes and the long-term outcome, noting that they invalidate identification strategies in previous literature. To address this challenge, we exploit the sequential structure of multiple short-term outcomes, and develop three novel identification strategies for the average long-term treatment effect. We further propose three corresponding estimators and prove their asymptotic consistency and asymptotic normality. We finally apply our methods to estimate the effect of a job training program on long-term employment using semi-synthetic data. We numerically show that our proposals outperform existing methods that fail to handle persistent confounders.
Treatment Effect Risk: Bounds and Inference
Jan 15, 2022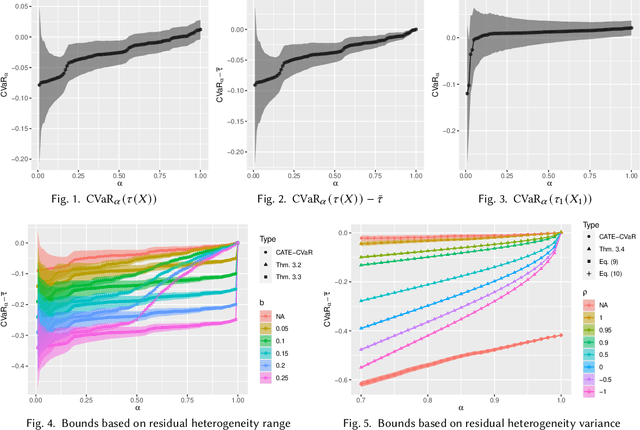
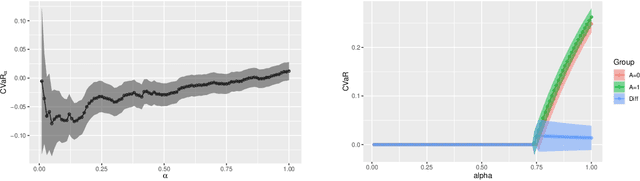
Since the average treatment effect (ATE) measures the change in social welfare, even if positive, there is a risk of negative effect on, say, some 10% of the population. Assessing such risk is difficult, however, because any one individual treatment effect (ITE) is never observed so the 10% worst-affected cannot be identified, while distributional treatment effects only compare the first deciles within each treatment group, which does not correspond to any 10%-subpopulation. In this paper we consider how to nonetheless assess this important risk measure, formalized as the conditional value at risk (CVaR) of the ITE distribution. We leverage the availability of pre-treatment covariates and characterize the tightest-possible upper and lower bounds on ITE-CVaR given by the covariate-conditional average treatment effect (CATE) function. Some bounds can also be interpreted as summarizing a complex CATE function into a single metric and are of interest independently of being a bound. We then proceed to study how to estimate these bounds efficiently from data and construct confidence intervals. This is challenging even in randomized experiments as it requires understanding the distribution of the unknown CATE function, which can be very complex if we use rich covariates so as to best control for heterogeneity. We develop a debiasing method that overcomes this and prove it enjoys favorable statistical properties even when CATE and other nuisances are estimated by black-box machine learning or even inconsistently. Studying a hypothetical change to French job-search counseling services, our bounds and inference demonstrate a small social benefit entails a negative impact on a substantial subpopulation.
Doubly-Valid/Doubly-Sharp Sensitivity Analysis for Causal Inference with Unmeasured Confounding
Dec 21, 2021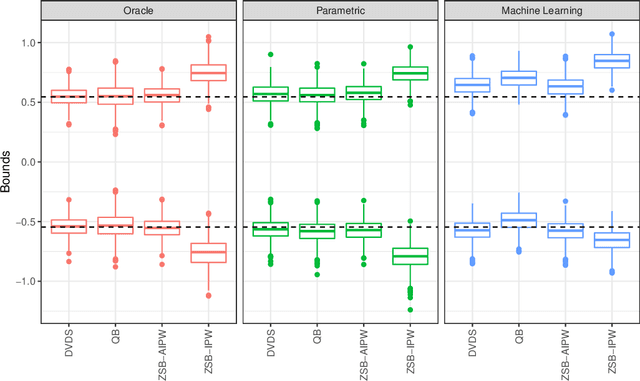
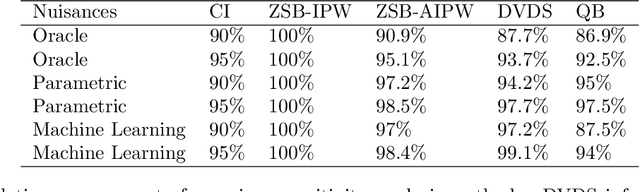
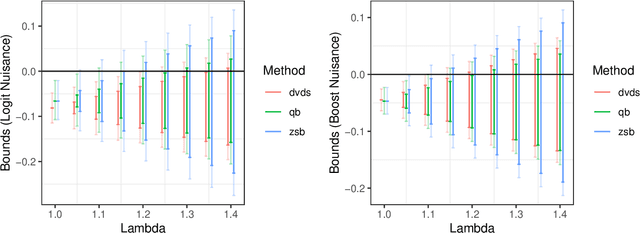
We study the problem of constructing bounds on the average treatment effect in the presence of unobserved confounding under the marginal sensitivity model of Tan (2006). Combining an existing characterization involving adversarial propensity scores with a new distributionally robust characterization of the problem, we propose novel estimators of these bounds that we call "doubly-valid/doubly-sharp" (DVDS) estimators. Double sharpness corresponds to the fact that DVDS estimators consistently estimate the tightest possible (i.e., sharp) bounds implied by the sensitivity model even when one of two nuisance parameters is misspecified and achieve semiparametric efficiency when all nuisance parameters are suitably consistent. Double validity is an entirely new property for partial identification: DVDS estimators still provide valid, though not sharp, bounds even when most nuisance parameters are misspecified. In fact, even in cases when DVDS point estimates fail to be asymptotically normal, standard Wald confidence intervals may remain valid. In the case of binary outcomes, the DVDS estimators are particularly convenient and possesses a closed-form expression in terms of the outcome regression and propensity score. We demonstrate the DVDS estimators in a simulation study as well as a case study of right heart catheterization.
Proximal Reinforcement Learning: Efficient Off-Policy Evaluation in Partially Observed Markov Decision Processes
Oct 28, 2021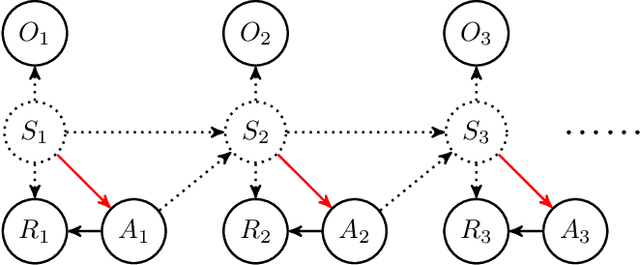
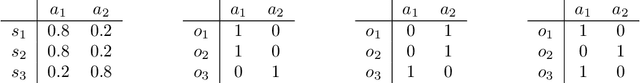
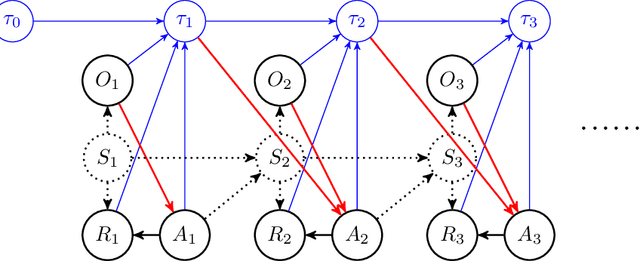
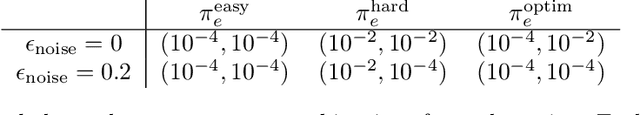
In applications of offline reinforcement learning to observational data, such as in healthcare or education, a general concern is that observed actions might be affected by unobserved factors, inducing confounding and biasing estimates derived under the assumption of a perfect Markov decision process (MDP) model. Here we tackle this by considering off-policy evaluation in a partially observed MDP (POMDP). Specifically, we consider estimating the value of a given target policy in a POMDP given trajectories with only partial state observations generated by a different and unknown policy that may depend on the unobserved state. We tackle two questions: what conditions allow us to identify the target policy value from the observed data and, given identification, how to best estimate it. To answer these, we extend the framework of proximal causal inference to our POMDP setting, providing a variety of settings where identification is made possible by the existence of so-called bridge functions. We then show how to construct semiparametrically efficient estimators in these settings. We term the resulting framework proximal reinforcement learning (PRL). We demonstrate the benefits of PRL in an extensive simulation study.
Stateful Offline Contextual Policy Evaluation and Learning
Oct 19, 2021
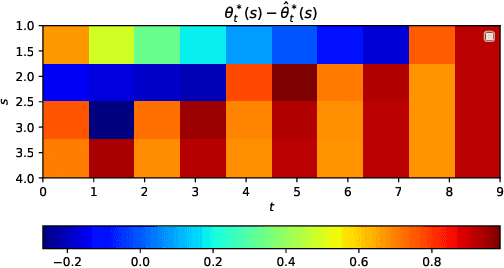
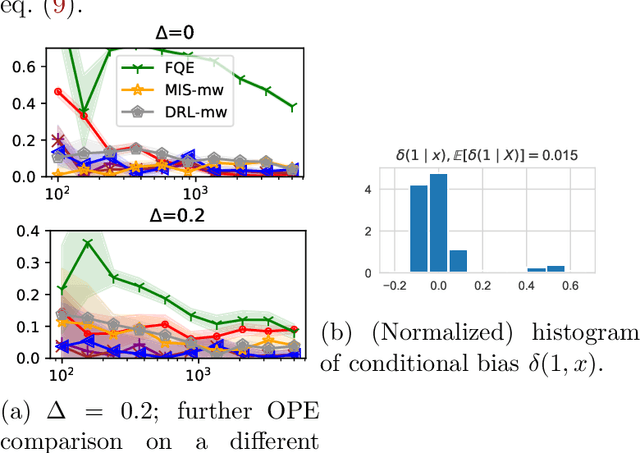
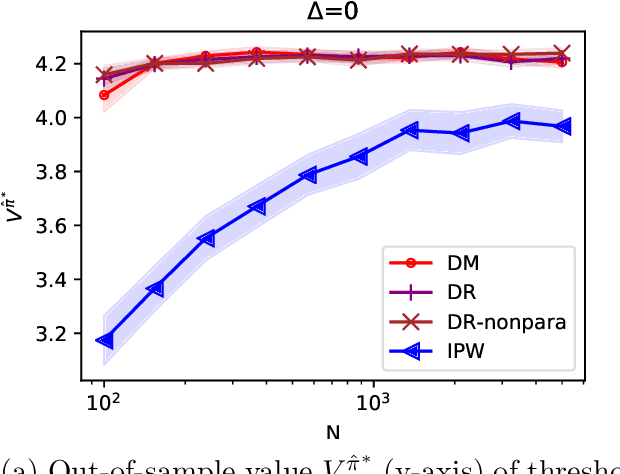
We study off-policy evaluation and learning from sequential data in a structured class of Markov decision processes that arise from repeated interactions with an exogenous sequence of arrivals with contexts, which generate unknown individual-level responses to agent actions. This model can be thought of as an offline generalization of contextual bandits with resource constraints. We formalize the relevant causal structure of problems such as dynamic personalized pricing and other operations management problems in the presence of potentially high-dimensional user types. The key insight is that an individual-level response is often not causally affected by the state variable and can therefore easily be generalized across timesteps and states. When this is true, we study implications for (doubly robust) off-policy evaluation and learning by instead leveraging single time-step evaluation, estimating the expectation over a single arrival via data from a population, for fitted-value iteration in a marginal MDP. We study sample complexity and analyze error amplification that leads to the persistence, rather than attenuation, of confounding error over time. In simulations of dynamic and capacitated pricing, we show improved out-of-sample policy performance in this class of relevant problems.
Residual Overfit Method of Exploration
Oct 06, 2021Exploration is a crucial aspect of bandit and reinforcement learning algorithms. The uncertainty quantification necessary for exploration often comes from either closed-form expressions based on simple models or resampling and posterior approximations that are computationally intensive. We propose instead an approximate exploration methodology based on fitting only two point estimates, one tuned and one overfit. The approach, which we term the residual overfit method of exploration (ROME), drives exploration towards actions where the overfit model exhibits the most overfitting compared to the tuned model. The intuition is that overfitting occurs the most at actions and contexts with insufficient data to form accurate predictions of the reward. We justify this intuition formally from both a frequentist and a Bayesian information theoretic perspective. The result is a method that generalizes to a wide variety of models and avoids the computational overhead of resampling or posterior approximations. We compare ROME against a set of established contextual bandit methods on three datasets and find it to be one of the best performing.
Control Variates for Slate Off-Policy Evaluation
Jun 15, 2021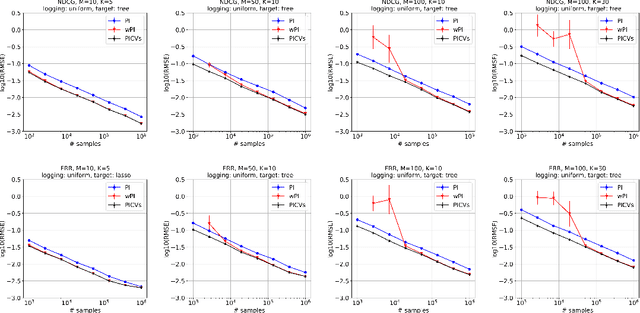
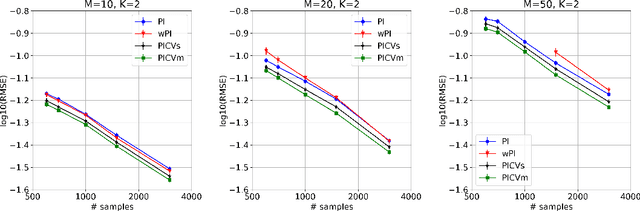
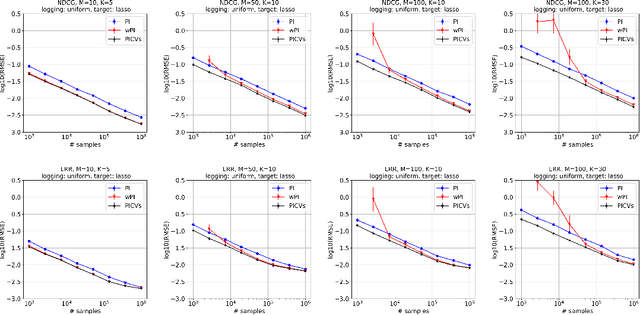
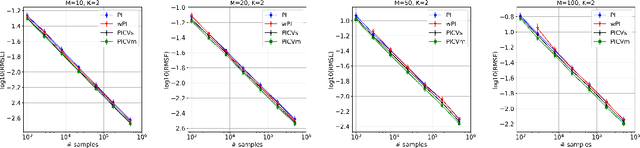
We study the problem of off-policy evaluation from batched contextual bandit data with multidimensional actions, often termed slates. The problem is common to recommender systems and user-interface optimization, and it is particularly challenging because of the combinatorially-sized action space. Swaminathan et al. (2017) have proposed the pseudoinverse (PI) estimator under the assumption that the conditional mean rewards are additive in actions. Using control variates, we consider a large class of unbiased estimators that includes as specific cases the PI estimator and (asymptotically) its self-normalized variant. By optimizing over this class, we obtain new estimators with risk improvement guarantees over both the PI and self-normalized PI estimators. Experiments with real-world recommender data as well as synthetic data validate these improvements in practice.