 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Explainable Face Verification based on Similarity Score Argument Backpropagation
Apr 26, 2023Explainable Face Recognition is gaining growing attention as the use of the technology is gaining ground in security-critical applications. Understanding why two faces images are matched or not matched by a given face recognition system is important to operators, users, anddevelopers to increase trust, accountability, develop better systems, and highlight unfair behavior. In this work, we propose xSSAB, an approach to back-propagate similarity score-based arguments that support or oppose the face matching decision to visualize spatial maps that indicate similar and dissimilar areas as interpreted by the underlying FR model. Furthermore, we present Patch-LFW, a new explainable face verification benchmark that enables along with a novel evaluation protocol, the first quantitative evaluation of the validity of similarity and dissimilarity maps in explainable face recognition approaches. We compare our efficient approach to state-of-the-art approaches demonstrating a superior trade-off between efficiency and performance. The code as well as the proposed Patch-LFW is publicly available at: https://github.com/marcohuber/xSSAB.
Are Explainability Tools Gender Biased? A Case Study on Face Presentation Attack Detection
Apr 26, 2023Face recognition (FR) systems continue to spread in our daily lives with an increasing demand for higher explainability and interpretability of FR systems that are mainly based on deep learning. While bias across demographic groups in FR systems has already been studied, the bias of explainability tools has not yet been investigated. As such tools aim at steering further development and enabling a better understanding of computer vision problems, the possible existence of bias in their outcome can lead to a chain of biased decisions. In this paper, we explore the existence of bias in the outcome of explainability tools by investigating the use case of face presentation attack detection. By utilizing two different explainability tools on models with different levels of bias, we investigate the bias in the outcome of such tools. Our study shows that these tools show clear signs of gender bias in the quality of their explanations.
Multispectral Imaging for Differential Face Morphing Attack Detection: A Preliminary Study
Apr 07, 2023



Face morphing attack detection is emerging as an increasingly challenging problem owing to advancements in high-quality and realistic morphing attack generation. Reliable detection of morphing attacks is essential because these attacks are targeted for border control applications. This paper presents a multispectral framework for differential morphing-attack detection (D-MAD). The D-MAD methods are based on using two facial images that are captured from the ePassport (also called the reference image) and the trusted device (for example, Automatic Border Control (ABC) gates) to detect whether the face image presented in ePassport is morphed. The proposed multispectral D-MAD framework introduce a multispectral image captured as a trusted capture to capture seven different spectral bands to detect morphing attacks. Extensive experiments were conducted on the newly created datasets with 143 unique data subjects that were captured using both visible and multispectral cameras in multiple sessions. The results indicate the superior performance of the proposed multispectral framework compared to visible images.
SynthASpoof: Developing Face Presentation Attack Detection Based on Privacy-friendly Synthetic Data
Mar 05, 2023Recently, significant progress has been made in face presentation attack detection (PAD), which aims to secure face recognition systems against presentation attacks, owing to the availability of several face PAD datasets. However, all available datasets are based on privacy and legally-sensitive authentic biometric data with a limited number of subjects. To target these legal and technical challenges, this work presents the first synthetic-based face PAD dataset, named SynthASpoof, as a large-scale PAD development dataset. The bona fide samples in SynthASpoof are synthetically generated and the attack samples are collected by presenting such synthetic data to capture systems in a real attack scenario. The experimental results demonstrate the feasibility of using SynthASpoof for the development of face PAD. Moreover, we boost the performance of such a solution by incorporating the domain generalization tool MixStyle into the PAD solutions. Additionally, we showed the viability of using synthetic data as a supplement to enrich the diversity of limited authentic training data and consistently enhance PAD performances. The SynthASpoof dataset, containing 25,000 bona fide and 78,800 attack samples, the implementation, and the pre-trained weights are made publicly available.
MorDIFF: Recognition Vulnerability and Attack Detectability of Face Morphing Attacks Created by Diffusion Autoencoders
Feb 03, 2023Investigating new methods of creating face morphing attacks is essential to foresee novel attacks and help mitigate them. Creating morphing attacks is commonly either performed on the image-level or on the representation-level. The representation-level morphing has been performed so far based on generative adversarial networks (GAN) where the encoded images are interpolated in the latent space to produce a morphed image based on the interpolated vector. Such a process was constrained by the limited reconstruction fidelity of GAN architectures. Recent advances in the diffusion autoencoder models have overcome the GAN limitations, leading to high reconstruction fidelity. This theoretically makes them a perfect candidate to perform representation-level face morphing. This work investigates using diffusion autoencoders to create face morphing attacks by comparing them to a wide range of image-level and representation-level morphs. Our vulnerability analyses on four state-of-the-art face recognition models have shown that such models are highly vulnerable to the created attacks, the MorDIFF, especially when compared to existing representation-level morphs. Detailed detectability analyses are also performed on the MorDIFF, showing that they are as challenging to detect as other morphing attacks created on the image- or representation-level. Data and morphing script are made public.
Periocular Biometrics: A Modality for Unconstrained Scenarios
Dec 28, 2022Periocular refers to the region of the face that surrounds the eye socket. This is a feature-rich area that can be used by itself to determine the identity of an individual. It is especially useful when the iris or the face cannot be reliably acquired. This can be the case of unconstrained or uncooperative scenarios, where the face may appear partially occluded, or the subject-to-camera distance may be high. However, it has received revived attention during the pandemic due to masked faces, leaving the ocular region as the only visible facial area, even in controlled scenarios. This paper discusses the state-of-the-art of periocular biometrics, giving an overall framework of its most significant research aspects.
Unsupervised Face Recognition using Unlabeled Synthetic Data
Nov 14, 2022



Over the past years, the main research innovations in face recognition focused on training deep neural networks on large-scale identity-labeled datasets using variations of multi-class classification losses. However, many of these datasets are retreated by their creators due to increased privacy and ethical concerns. Very recently, privacy-friendly synthetic data has been proposed as an alternative to privacy-sensitive authentic data to comply with privacy regulations and to ensure the continuity of face recognition research. In this paper, we propose an unsupervised face recognition model based on unlabeled synthetic data (USynthFace). Our proposed USynthFace learns to maximize the similarity between two augmented images of the same synthetic instance. We enable this by a large set of geometric and color transformations in addition to GAN-based augmentation that contributes to the USynthFace model training. We also conduct numerous empirical studies on different components of our USynthFace. With the proposed set of augmentation operations, we proved the effectiveness of our USynthFace in achieving relatively high recognition accuracies using unlabeled synthetic data.
A Survey on Computer Vision based Human Analysis in the COVID-19 Era
Nov 07, 2022



The emergence of COVID-19 has had a global and profound impact, not only on society as a whole, but also on the lives of individuals. Various prevention measures were introduced around the world to limit the transmission of the disease, including face masks, mandates for social distancing and regular disinfection in public spaces, and the use of screening applications. These developments also triggered the need for novel and improved computer vision techniques capable of (i) providing support to the prevention measures through an automated analysis of visual data, on the one hand, and (ii) facilitating normal operation of existing vision-based services, such as biometric authentication schemes, on the other. Especially important here, are computer vision techniques that focus on the analysis of people and faces in visual data and have been affected the most by the partial occlusions introduced by the mandates for facial masks. Such computer vision based human analysis techniques include face and face-mask detection approaches, face recognition techniques, crowd counting solutions, age and expression estimation procedures, models for detecting face-hand interactions and many others, and have seen considerable attention over recent years. The goal of this survey is to provide an introduction to the problems induced by COVID-19 into such research and to present a comprehensive review of the work done in the computer vision based human analysis field. Particular attention is paid to the impact of facial masks on the performance of various methods and recent solutions to mitigate this problem. Additionally, a detailed review of existing datasets useful for the development and evaluation of methods for COVID-19 related applications is also provided. Finally, to help advance the field further, a discussion on the main open challenges and future research direction is given.
Stating Comparison Score Uncertainty and Verification Decision Confidence Towards Transparent Face Recognition
Oct 19, 2022
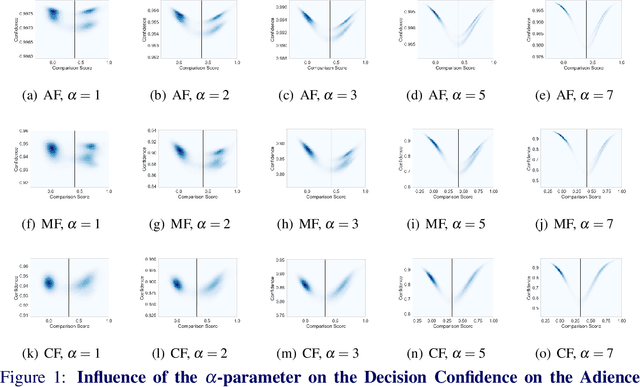
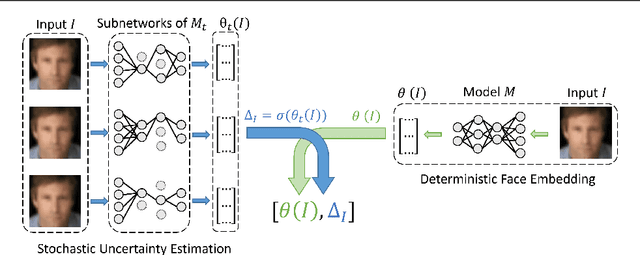
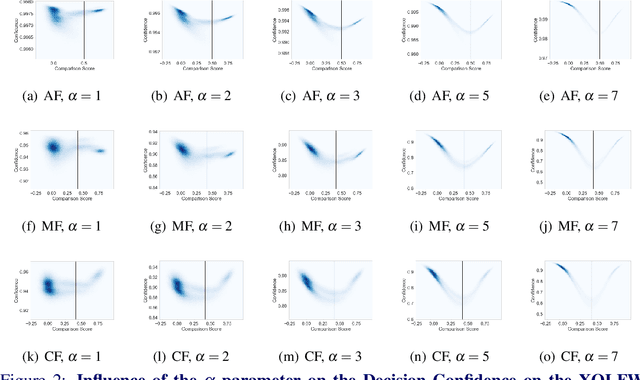
Face Recognition (FR) is increasingly used in critical verification decisions and thus, there is a need for assessing the trustworthiness of such decisions. The confidence of a decision is often based on the overall performance of the model or on the image quality. We propose to propagate model uncertainties to scores and decisions in an effort to increase the transparency of verification decisions. This work presents two contributions. First, we propose an approach to estimate the uncertainty of face comparison scores. Second, we introduce a confidence measure of the system's decision to provide insights into the verification decision. The suitability of the comparison scores uncertainties and the verification decision confidences have been experimentally proven on three face recognition models on two datasets.
Fairness in Face Presentation Attack Detection
Sep 19, 2022
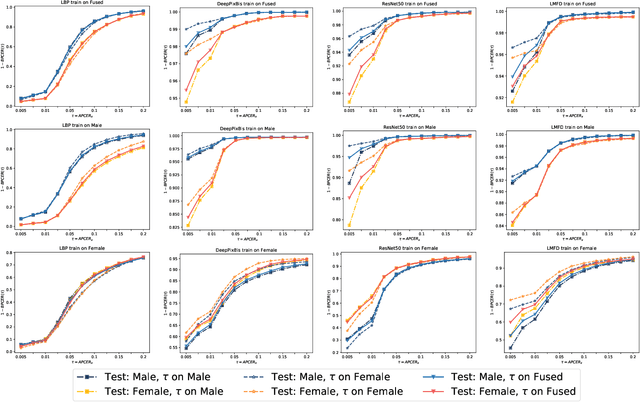
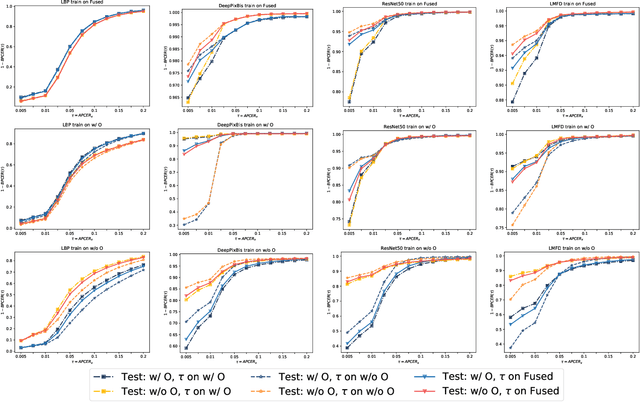

Face presentation attack detection (PAD) is critical to secure face recognition (FR) applications from presentation attacks. FR performance has been shown to be unfair to certain demographic and non-demographic groups. However, the fairness of face PAD is an understudied issue, mainly due to the lack of appropriately annotated data. To address this issue, this work first presents a Combined Attribute Annotated PAD Dataset (CAAD-PAD) by combining several well-known PAD datasets where we provide seven human-annotated attribute labels. This work then comprehensively analyses the fairness of a set of face PADs and its relation to the nature of training data and the Operational Decision Threshold Assignment (ODTA) on different data groups by studying four face PAD approaches on our CAAD-PAD. To simultaneously represent both the PAD fairness and the absolute PAD performance, we introduce a novel metric, namely the Accuracy Balanced Fairness (ABF). Extensive experiments on CAAD-PAD show that the training data and ODTA induce unfairness on gender, occlusion, and other attribute groups. Based on these analyses, we propose a data augmentation method, FairSWAP, which aims to disrupt the identity/semantic information and guide models to mine attack cues rather than attribute-related information. Detailed experimental results demonstrate that FairSWAP generally enhances both the PAD performance and the fairness of face PAD.