 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Knowledge Collides: A Mechanistic Study of Intra-Memory Knowledge Conflict in Language Models
Jan 14, 2026In language models (LMs), intra-memory knowledge conflict largely arises when inconsistent information about the same event is encoded within the model's parametric knowledge. While prior work has primarily focused on resolving conflicts between a model's internal knowledge and external resources through approaches such as fine-tuning or knowledge editing, the problem of localizing conflicts that originate during pre-training within the model's internal representations remain unexplored. In this work, we design a framework based on mechanistic interpretability methods to identify where and how conflicting knowledge from the pre-training data is encoded within LMs. Our findings contribute to a growing body of evidence that specific internal components of a language model are responsible for encoding conflicting knowledge from pre-training, and we demonstrate how mechanistic interpretability methods can be leveraged to causally intervene in and control conflicting knowledge at inference time.
Privacy-friendly Synthetic Data for the Development of Face Morphing Attack Detectors
Mar 16, 2022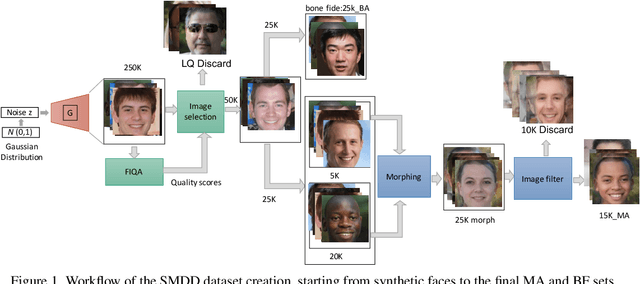
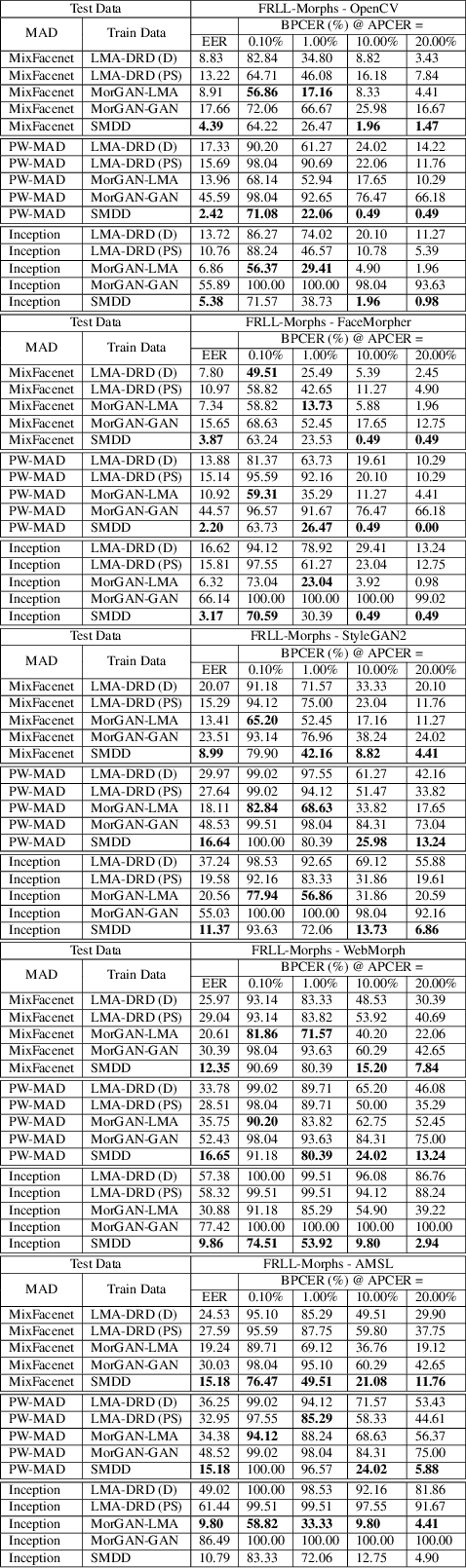

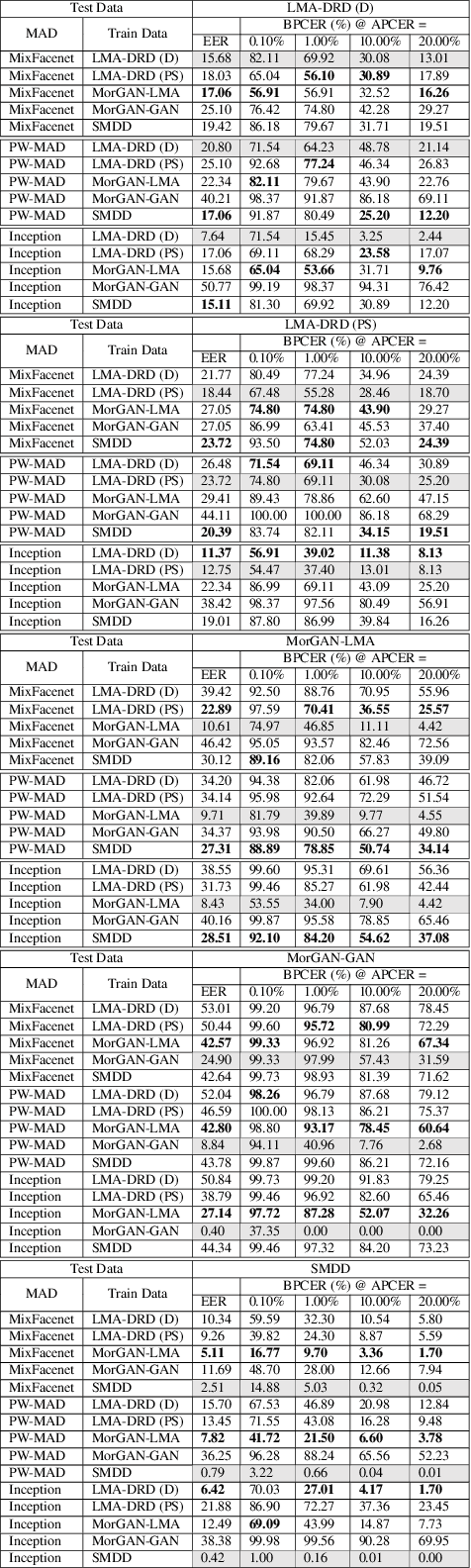
The main question this work aims at answering is: can morphing attack detection (MAD) solutions be successfully developed based on synthetic data?. Towards that, this work introduces the first synthetic-based MAD development dataset, namely the Synthetic Morphing Attack Detection Development dataset (SMDD). This dataset is utilized successfully to train three MAD backbones where it proved to lead to high MAD performance, even on completely unknown attack types. Additionally, an essential aspect of this work is the detailed legal analyses of the challenges of using and sharing real biometric data, rendering our proposed SMDD dataset extremely essential. The SMDD dataset, consisting of 30,000 attack and 50,000 bona fide samples, is made publicly available for research purposes.