 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Drift using Shapley Values
Jan 18, 2024Machine learning models often deteriorate in their performance when they are used to predict the outcomes over data on which they were not trained. These scenarios can often arise in real world when the distribution of data changes gradually or abruptly due to major events like a pandemic. There have been many attempts in machine learning research to come up with techniques that are resilient to such Concept drifts. However, there is no principled framework to identify the drivers behind the drift in model performance. In this paper, we propose a novel framework - DBShap that uses Shapley values to identify the main contributors of the drift and quantify their respective contributions. The proposed framework not only quantifies the importance of individual features in driving the drift but also includes the change in the underlying relation between the input and output as a possible driver. The explanation provided by DBShap can be used to understand the root cause behind the drift and use it to make the model resilient to the drift.
Probabilistic Dependency Networks for Prediction and Diagnostics
Aug 13, 2015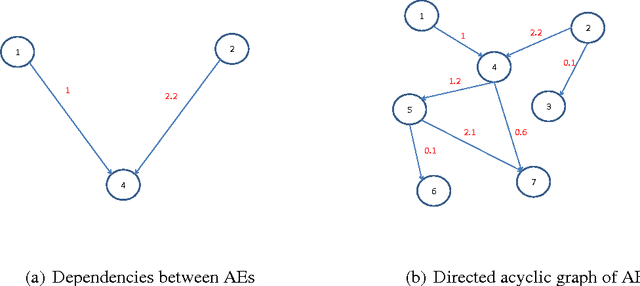
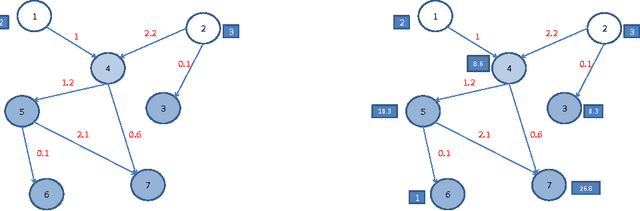
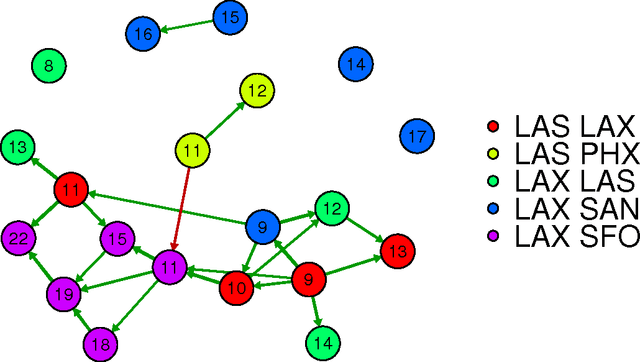
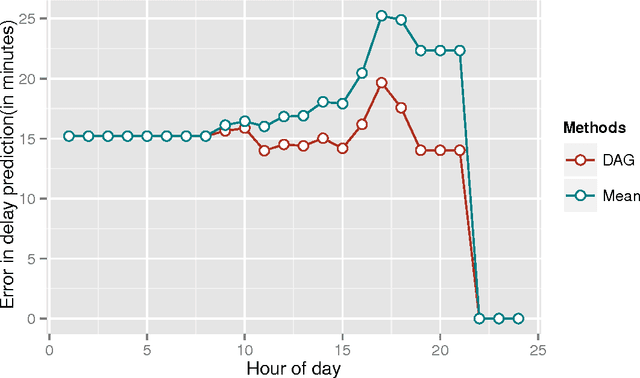
Research in transportation frequently involve modelling and predicting attributes of events that occur at regular intervals. The event could be arrival of a bus at a bus stop, the volume of a traffic at a particular point, the demand at a particular bus stop etc. In this work, we propose a specific implementation of probabilistic graphical models to learn the probabilistic dependency between the events that occur in a network. A dependency graph is built from the past observed instances of the event and we use the graph to understand the causal effects of some events on others in the system. The dependency graph is also used to predict the attributes of future events and is shown to have a good prediction accuracy compared to the state of the art.
Boosting as a Product of Experts
Feb 14, 2012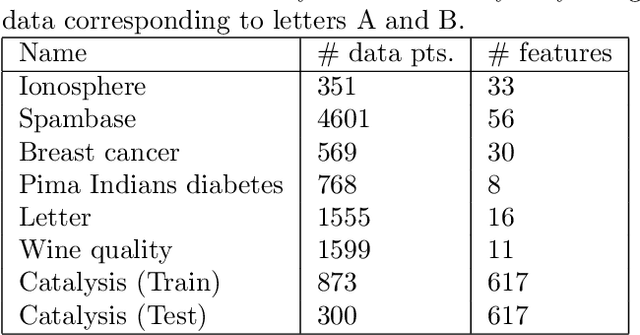
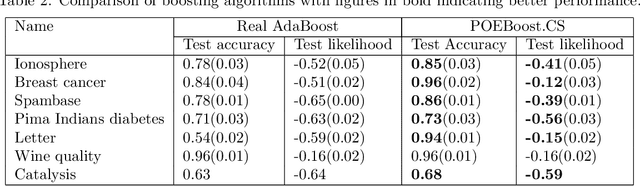
In this paper, we derive a novel probabilistic model of boosting as a Product of Experts. We re-derive the boosting algorithm as a greedy incremental model selection procedure which ensures that addition of new experts to the ensemble does not decrease the likelihood of the data. These learning rules lead to a generic boosting algorithm - POE- Boost which turns out to be similar to the AdaBoost algorithm under certain assumptions on the expert probabilities. The paper then extends the POEBoost algorithm to POEBoost.CS which handles hypothesis that produce probabilistic predictions. This new algorithm is shown to have better generalization performance compared to other state of the art algorithms.