 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded in Context: Retrieval-Based Method for Hallucination Detection
Apr 22, 2025

Despite advancements in grounded content generation, production Large Language Models (LLMs) based applications still suffer from hallucinated answers. We present "Grounded in Context" - Deepchecks' hallucination detection framework, designed for production-scale long-context data and tailored to diverse use cases, including summarization, data extraction, and RAG. Inspired by RAG architecture, our method integrates retrieval and Natural Language Inference (NLI) models to predict factual consistency between premises and hypotheses using an encoder-based model with only a 512-token context window. Our framework identifies unsupported claims with an F1 score of 0.83 in RAGTruth's response-level classification task, matching methods that trained on the dataset, and outperforming all comparable frameworks using similar-sized models.
Approximating a Target Distribution using Weight Queries
Jun 24, 2020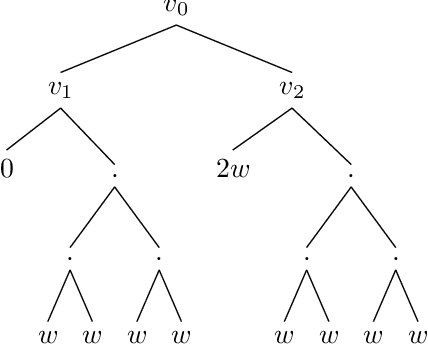
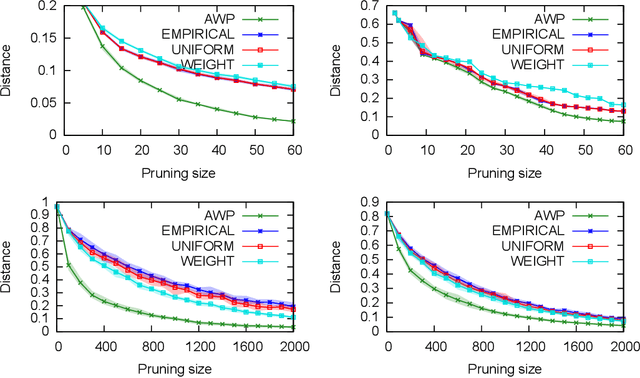
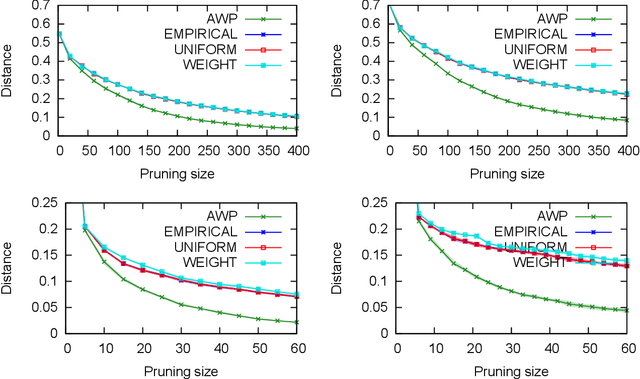
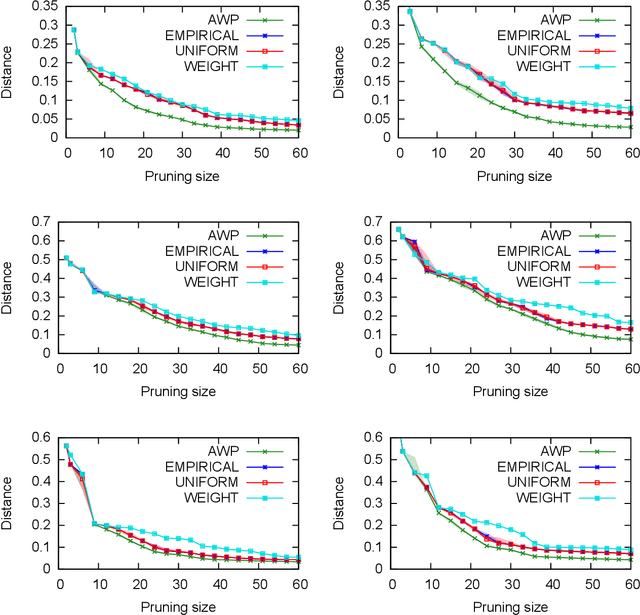
A basic assumption in classical learning and estimation is the availability of a random sample from the target distribution. In domain adaptation this assumption is replaced with the availability of a sample from a source distribution, and a smaller or unlabeled sample from the target distribution. In this work, we consider a setting in which no random sampling from the target distribution is possible. Instead, given a large data set, it is possible to query the probability (weight) of a data point, or a set of data points, according to the target distribution. This can be the case when access to the target distribution is mediated, e.g., by specific measurements or by user relevance queries. We propose an algorithm for finding a reweighing of the data set which approximates the target distribution weights, using a limited number of target weight queries. The weighted data set may then be used in estimation and learning tasks, as a proxy for a sample from the target distribution. Given a hierarchical tree structure over the data set, which induces a class of weight functions, we prove that the algorithm approximates the best possible function, and upper bound the number of weight queries. In experiments, we demonstrate the advantage of the proposed algorithm over several baselines. A python implementation of the proposed algorithm and all experiments can be found at https://github.com/Nadav-Barak/AWP.