 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of NLU Benchmarks Diagnosing Linguistic Phenomena: Why not Standardize Diagnostics Benchmarks?
Jul 27, 2025Natural Language Understanding (NLU) is a basic task in Natural Language Processing (NLP). The evaluation of NLU capabilities has become a trending research topic that attracts researchers in the last few years, resulting in the development of numerous benchmarks. These benchmarks include various tasks and datasets in order to evaluate the results of pretrained models via public leaderboards. Notably, several benchmarks contain diagnostics datasets designed for investigation and fine-grained error analysis across a wide range of linguistic phenomena. This survey provides a comprehensive review of available English, Arabic, and Multilingual NLU benchmarks, with a particular emphasis on their diagnostics datasets and the linguistic phenomena they covered. We present a detailed comparison and analysis of these benchmarks, highlighting their strengths and limitations in evaluating NLU tasks and providing in-depth error analysis. When highlighting the gaps in the state-of-the-art, we noted that there is no naming convention for macro and micro categories or even a standard set of linguistic phenomena that should be covered. Consequently, we formulated a research question regarding the evaluation metrics of the evaluation diagnostics benchmarks: "Why do not we have an evaluation standard for the NLU evaluation diagnostics benchmarks?" similar to ISO standard in industry. We conducted a deep analysis and comparisons of the covered linguistic phenomena in order to support experts in building a global hierarchy for linguistic phenomena in future. We think that having evaluation metrics for diagnostics evaluation could be valuable to gain more insights when comparing the results of the studied models on different diagnostics benchmarks.
ArEEG_Words: Dataset for Envisioned Speech Recognition using EEG for Arabic Words
Nov 28, 2024



Brain-Computer-Interface (BCI) aims to support communication-impaired patients by translating neural signals into speech. A notable research topic in BCI involves Electroencephalography (EEG) signals that measure the electrical activity in the brain. While significant advancements have been made in BCI EEG research, a major limitation still exists: the scarcity of publicly available EEG datasets for non-English languages, such as Arabic. To address this gap, we introduce in this paper ArEEG_Words dataset, a novel EEG dataset recorded from 22 participants with mean age of 22 years (5 female, 17 male) using a 14-channel Emotiv Epoc X device. The participants were asked to be free from any effects on their nervous system, such as coffee, alcohol, cigarettes, and so 8 hours before recording. They were asked to stay calm in a clam room during imagining one of the 16 Arabic Words for 10 seconds. The words include 16 commonly used words such as up, down, left, and right. A total of 352 EEG recordings were collected, then each recording was divided into multiple 250ms signals, resulting in a total of 15,360 EEG signals. To the best of our knowledge, ArEEG_Words data is the first of its kind in Arabic EEG domain. Moreover, it is publicly available for researchers as we hope that will fill the gap in Arabic EEG research.
ArEEG_Chars: Dataset for Envisioned Speech Recognition using EEG for Arabic Characters
Feb 24, 2024



Brain-Computer-Interface (BCI) has been a hot research topic in the last few years that could help paralyzed people in their lives. Several researches were done to classify electroencephalography (EEG) signals automatically into English characters and words. Arabic language is one of the most used languages around the world. However, to the best of our knowledge, there is no dataset for Arabic characters EEG signals. In this paper, we have created an EEG dataset for Arabic characters and named it ArEEG_Chars. Moreover, several experiments were done on ArEEG_Chars using deep learning. Best results were achieved using LSTM and reached an accuracy of 97%. ArEEG_Chars dataset will be public for researchers.
ArNLI: Arabic Natural Language Inference for Entailment and Contradiction Detection
Sep 28, 2022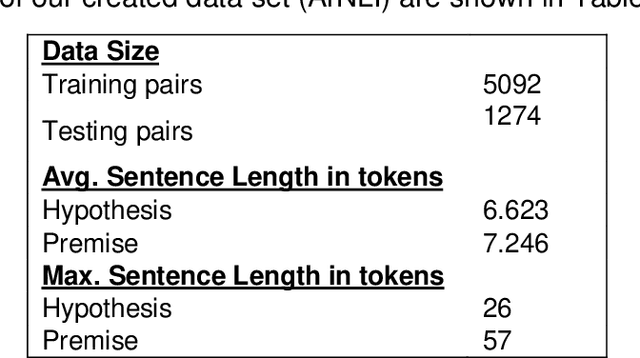
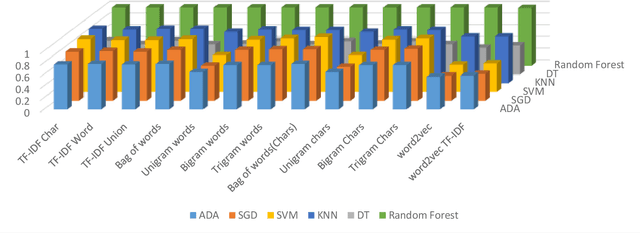
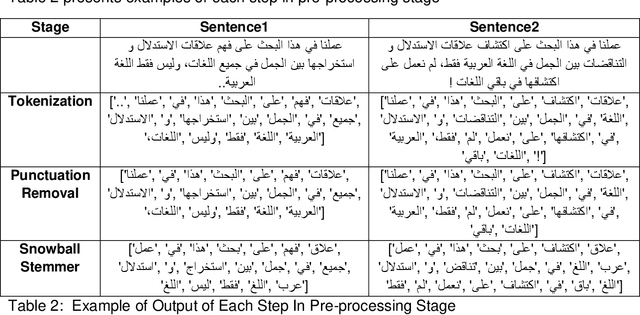
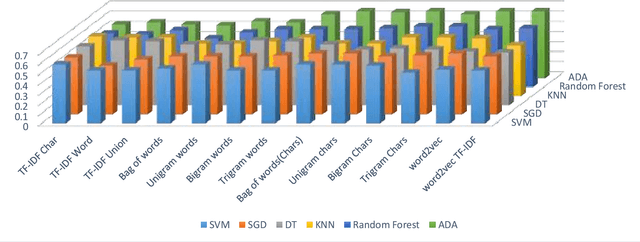
Natural Language Inference (NLI) is a hot topic research in natural language processing, contradiction detection between sentences is a special case of NLI. This is considered a difficult NLP task which has a big influence when added as a component in many NLP applications, such as Question Answering Systems, text Summarization. Arabic Language is one of the most challenging low-resources languages in detecting contradictions due to its rich lexical, semantics ambiguity. We have created a data set of more than 12k sentences and named ArNLI, that will be publicly available. Moreover, we have applied a new model inspired by Stanford contradiction detection proposed solutions on English language. We proposed an approach to detect contradictions between pairs of sentences in Arabic language using contradiction vector combined with language model vector as an input to machine learning model. We analyzed results of different traditional machine learning classifiers and compared their results on our created data set (ArNLI) and on an automatic translation of both PHEME, SICK English data sets. Best results achieved using Random Forest classifier with an accuracy of 99%, 60%, 75% on PHEME, SICK and ArNLI respectively.