 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTSUM: Relation Triple-based Interpretable Summarization with Multi-level Salience Visualization
Oct 21, 2023


In this paper, we present RTSUM, an unsupervised summarization framework that utilizes relation triples as the basic unit for summarization. Given an input document, RTSUM first selects salient relation triples via multi-level salience scoring and then generates a concise summary from the selected relation triples by using a text-to-text language model. On the basis of RTSUM, we also develop a web demo for an interpretable summarizing tool, providing fine-grained interpretations with the output summary. With support for customization options, our tool visualizes the salience for textual units at three distinct levels: sentences, relation triples, and phrases. The codes,are publicly available.
Improving Document Clustering by Eliminating Unnatural Language
Mar 17, 2017
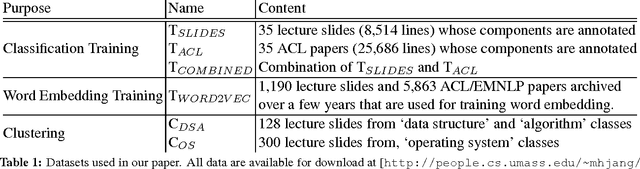


Technical documents contain a fair amount of unnatural language, such as tables, formulas, pseudo-codes, etc. Unnatural language can be an important factor of confusing existing NLP tools. This paper presents an effective method of distinguishing unnatural language from natural language, and evaluates the impact of unnatural language detection on NLP tasks such as document clustering. We view this problem as an information extraction task and build a multiclass classification model identifying unnatural language components into four categories. First, we create a new annotated corpus by collecting slides and papers in various formats, PPT, PDF, and HTML, where unnatural language components are annotated into four categories. We then explore features available from plain text to build a statistical model that can handle any format as long as it is converted into plain text. Our experiments show that removing unnatural language components gives an absolute improvement in document clustering up to 15%. Our corpus and tool are publicly available.