 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me What You Know About Sexism: Expert-LLM Interaction Strategies and Co-Created Definitions for Zero-Shot Sexism Detection
Apr 21, 2025This paper investigates hybrid intelligence and collaboration between researchers of sexism and Large Language Models (LLMs), with a four-component pipeline. First, nine sexism researchers answer questions about their knowledge of sexism and of LLMs. They then participate in two interactive experiments involving an LLM (GPT3.5). The first experiment has experts assessing the model's knowledge about sexism and suitability for use in research. The second experiment tasks them with creating three different definitions of sexism: an expert-written definition, an LLM-written one, and a co-created definition. Lastly, zero-shot classification experiments use the three definitions from each expert in a prompt template for sexism detection, evaluating GPT4o on 2.500 texts sampled from five sexism benchmarks. We then analyze the resulting 67.500 classification decisions. The LLM interactions lead to longer and more complex definitions of sexism. Expert-written definitions on average perform poorly compared to LLM-generated definitions. However, some experts do improve classification performance with their co-created definitions of sexism, also experts who are inexperienced in using LLMs.
A Few Hypocrites: Few-Shot Learning and Subtype Definitions for Detecting Hypocrisy Accusations in Online Climate Change Debates
Sep 25, 2024



The climate crisis is a salient issue in online discussions, and hypocrisy accusations are a central rhetorical element in these debates. However, for large-scale text analysis, hypocrisy accusation detection is an understudied tool, most often defined as a smaller subtask of fallacious argument detection. In this paper, we define hypocrisy accusation detection as an independent task in NLP, and identify different relevant subtypes of hypocrisy accusations. Our Climate Hypocrisy Accusation Corpus (CHAC) consists of 420 Reddit climate debate comments, expert-annotated into two different types of hypocrisy accusations: personal versus political hypocrisy. We evaluate few-shot in-context learning with 6 shots and 3 instruction-tuned Large Language Models (LLMs) for detecting hypocrisy accusations in this dataset. Results indicate that the GPT-4o and Llama-3 models in particular show promise in detecting hypocrisy accusations (F1 reaching 0.68, while previous work shows F1 of 0.44). However, context matters for a complex semantic concept such as hypocrisy accusations, and we find models struggle especially at identifying political hypocrisy accusations compared to personal moral hypocrisy. Our study contributes new insights in hypocrisy detection and climate change discourse, and is a stepping stone for large-scale analysis of hypocrisy accusation in online climate debates.
Investigating the Robustness of Modelling Decisions for Few-Shot Cross-Topic Stance Detection: A Preregistered Study
Apr 05, 2024For a viewpoint-diverse news recommender, identifying whether two news articles express the same viewpoint is essential. One way to determine "same or different" viewpoint is stance detection. In this paper, we investigate the robustness of operationalization choices for few-shot stance detection, with special attention to modelling stance across different topics. Our experiments test pre-registered hypotheses on stance detection. Specifically, we compare two stance task definitions (Pro/Con versus Same Side Stance), two LLM architectures (bi-encoding versus cross-encoding), and adding Natural Language Inference knowledge, with pre-trained RoBERTa models trained with shots of 100 examples from 7 different stance detection datasets. Some of our hypotheses and claims from earlier work can be confirmed, while others give more inconsistent results. The effect of the Same Side Stance definition on performance differs per dataset and is influenced by other modelling choices. We found no relationship between the number of training topics in the training shots and performance. In general, cross-encoding out-performs bi-encoding, and adding NLI training to our models gives considerable improvement, but these results are not consistent across all datasets. Our results indicate that it is essential to include multiple datasets and systematic modelling experiments when aiming to find robust modelling choices for the concept `stance'.
Improving and Evaluating the Detection of Fragmentation in News Recommendations with the Clustering of News Story Chains
Sep 18, 2023


News recommender systems play an increasingly influential role in shaping information access within democratic societies. However, tailoring recommendations to users' specific interests can result in the divergence of information streams. Fragmented access to information poses challenges to the integrity of the public sphere, thereby influencing democracy and public discourse. The Fragmentation metric quantifies the degree of fragmentation of information streams in news recommendations. Accurate measurement of this metric requires the application of Natural Language Processing (NLP) to identify distinct news events, stories, or timelines. This paper presents an extensive investigation of various approaches for quantifying Fragmentation in news recommendations. These approaches are evaluated both intrinsically, by measuring performance on news story clustering, and extrinsically, by assessing the Fragmentation scores of different simulated news recommender scenarios. Our findings demonstrate that agglomerative hierarchical clustering coupled with SentenceBERT text representation is substantially better at detecting Fragmentation than earlier implementations. Additionally, the analysis of simulated scenarios yields valuable insights and recommendations for stakeholders concerning the measurement and interpretation of Fragmentation.
* Cite published version: Polimeno et. al., Improving and Evaluating the Detection of Fragmentation in News Recommendations with the Clustering of News Story Chains, NORMalize 2023: The First Workshop on the Normative Design and Evaluation of Recommender Systems, September 19, 2023, co-located with the ACM Conference on Recommender Systems 2023 (RecSys 2023), Singapore
Will It Blend? Mixing Training Paradigms & Prompting for Argument Quality Prediction
Oct 05, 2022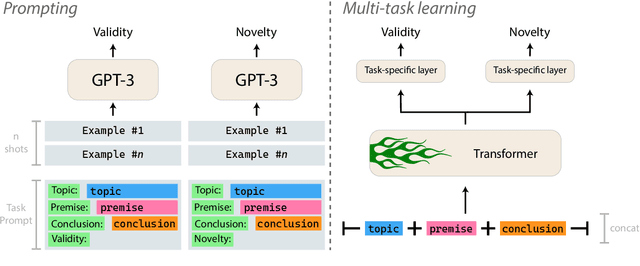

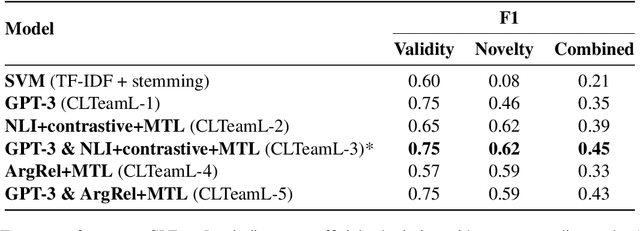
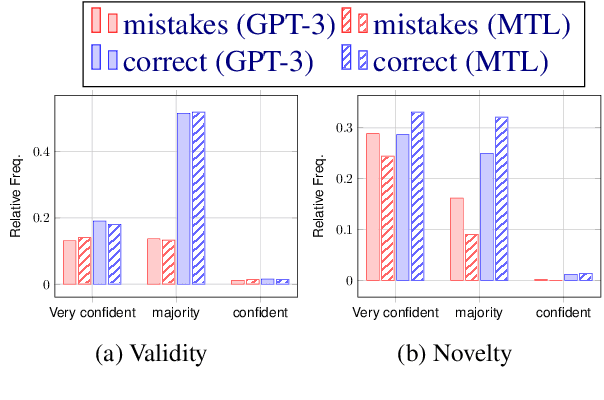
This paper describes our contributions to the Shared Task of the 9th Workshop on Argument Mining (2022). Our approach uses Large Language Models for the task of Argument Quality Prediction. We perform prompt engineering using GPT-3, and also investigate the training paradigms multi-task learning, contrastive learning, and intermediate-task training. We find that a mixed prediction setup outperforms single models. Prompting GPT-3 works best for predicting argument validity, and argument novelty is best estimated by a model trained using all three training paradigms.
Is Stance Detection Topic-Independent and Cross-topic Generalizable? -- A Reproduction Study
Oct 14, 2021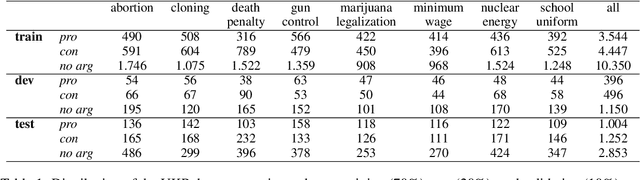
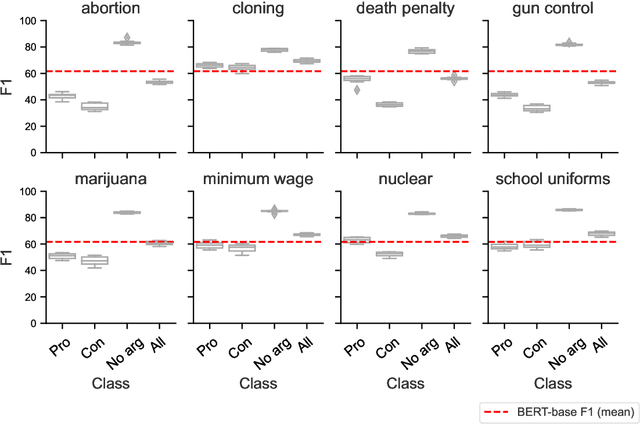
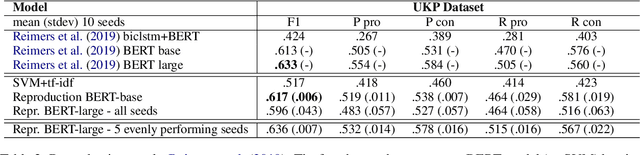

Cross-topic stance detection is the task to automatically detect stances (pro, against, or neutral) on unseen topics. We successfully reproduce state-of-the-art cross-topic stance detection work (Reimers et. al., 2019), and systematically analyze its reproducibility. Our attention then turns to the cross-topic aspect of this work, and the specificity of topics in terms of vocabulary and socio-cultural context. We ask: To what extent is stance detection topic-independent and generalizable across topics? We compare the model's performance on various unseen topics, and find topic (e.g. abortion, cloning), class (e.g. pro, con), and their interaction affecting the model's performance. We conclude that investigating performance on different topics, and addressing topic-specific vocabulary and context, is a future avenue for cross-topic stance detection.