 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor-Based Spatial-Temporal Attention Convolutional Networks for Dynamic 3D Point Cloud Sequences
Dec 20, 2020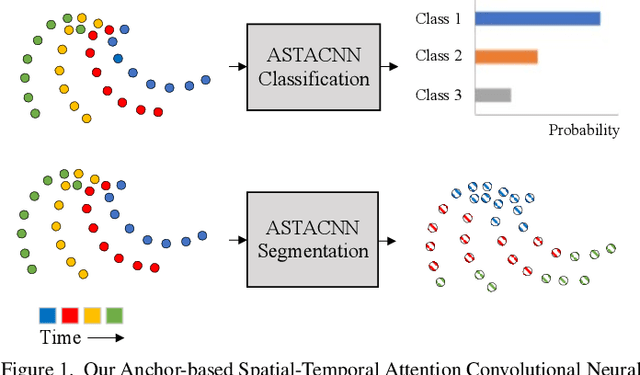
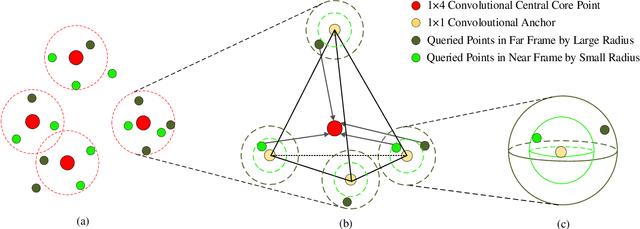
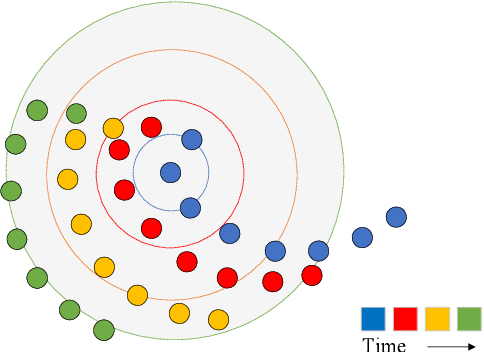
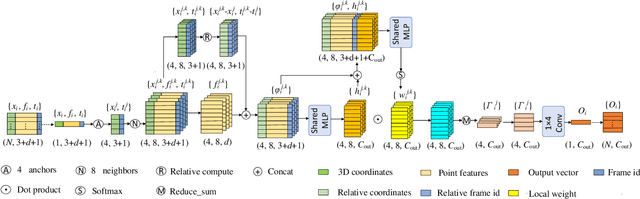
Recently, learning based methods for the robot perception from the image or video have much developed, but deep learning methods for dynamic 3D point cloud sequences are underexplored. With the widespread application of 3D sensors such as LiDAR and depth camera, efficient and accurate perception of the 3D environment from 3D sequence data is pivotal to autonomous driving and service robots. An Anchor-based Spatial-Temporal Attention Convolution operation (ASTAConv) is proposed in this paper to process dynamic 3D point cloud sequences. The proposed convolution operation builds a regular receptive field around each point by setting several virtual anchors around each point. The features of neighborhood points are firstly aggregated to each anchor based on spatial-temporal attention mechanism. Then, anchor-based sparse 3D convolution is adopted to aggregate the features of these anchors to the core points. The proposed method makes better use of the structured information within the local region, and learn spatial-temporal embedding features from dynamic 3D point cloud sequences. Then Anchor-based Spatial-Temporal Attention Convolutional Neural Networks (ASTACNNs) are proposed for classification and segmentation tasks and are evaluated on action recognition and semantic segmentation tasks. The experimental results on MSRAction3D and Synthia datasets demonstrate that the higher accuracy can be achieved than the previous state-of-the-art method by our novel strategy of multi-frame fusion.