 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Adversarial Attacks For Camera-based Smart Systems: Current Trends, Categorization, Applications, Research Challenges, and Future Outlook
Aug 11, 2023



In this paper, we present a comprehensive survey of the current trends focusing specifically on physical adversarial attacks. We aim to provide a thorough understanding of the concept of physical adversarial attacks, analyzing their key characteristics and distinguishing features. Furthermore, we explore the specific requirements and challenges associated with executing attacks in the physical world. Our article delves into various physical adversarial attack methods, categorized according to their target tasks in different applications, including classification, detection, face recognition, semantic segmentation and depth estimation. We assess the performance of these attack methods in terms of their effectiveness, stealthiness, and robustness. We examine how each technique strives to ensure the successful manipulation of DNNs while mitigating the risk of detection and withstanding real-world distortions. Lastly, we discuss the current challenges and outline potential future research directions in the field of physical adversarial attacks. We highlight the need for enhanced defense mechanisms, the exploration of novel attack strategies, the evaluation of attacks in different application domains, and the establishment of standardized benchmarks and evaluation criteria for physical adversarial attacks. Through this comprehensive survey, we aim to provide a valuable resource for researchers, practitioners, and policymakers to gain a holistic understanding of physical adversarial attacks in computer vision and facilitate the development of robust and secure DNN-based systems.
SAAM: Stealthy Adversarial Attack on Monoculor Depth Estimation
Aug 06, 2023



In this paper, we investigate the vulnerability of MDE to adversarial patches. We propose a novel \underline{S}tealthy \underline{A}dversarial \underline{A}ttacks on \underline{M}DE (SAAM) that compromises MDE by either corrupting the estimated distance or causing an object to seamlessly blend into its surroundings. Our experiments, demonstrate that the designed stealthy patch successfully causes a DNN-based MDE to misestimate the depth of objects. In fact, our proposed adversarial patch achieves a significant 60\% depth error with 99\% ratio of the affected region. Importantly, despite its adversarial nature, the patch maintains a naturalistic appearance, making it inconspicuous to human observers. We believe that this work sheds light on the threat of adversarial attacks in the context of MDE on edge devices. We hope it raises awareness within the community about the potential real-life harm of such attacks and encourages further research into developing more robust and adaptive defense mechanisms.
Approximate Computing Survey, Part II: Application-Specific & Architectural Approximation Techniques and Applications
Jul 20, 2023



The challenging deployment of compute-intensive applications from domains such Artificial Intelligence (AI) and Digital Signal Processing (DSP), forces the community of computing systems to explore new design approaches. Approximate Computing appears as an emerging solution, allowing to tune the quality of results in the design of a system in order to improve the energy efficiency and/or performance. This radical paradigm shift has attracted interest from both academia and industry, resulting in significant research on approximation techniques and methodologies at different design layers (from system down to integrated circuits). Motivated by the wide appeal of Approximate Computing over the last 10 years, we conduct a two-part survey to cover key aspects (e.g., terminology and applications) and review the state-of-the art approximation techniques from all layers of the traditional computing stack. In Part II of our survey, we classify and present the technical details of application-specific and architectural approximation techniques, which both target the design of resource-efficient processors/accelerators & systems. Moreover, we present a detailed analysis of the application spectrum of Approximate Computing and discuss open challenges and future directions.
FAQ: Mitigating the Impact of Faults in the Weight Memory of DNN Accelerators through Fault-Aware Quantization
May 21, 2023


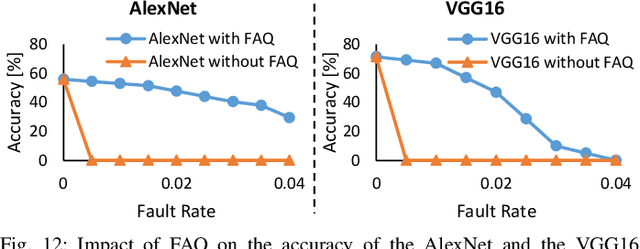
Permanent faults induced due to imperfections in the manufacturing process of Deep Neural Network (DNN) accelerators are a major concern, as they negatively impact the manufacturing yield of the chip fabrication process. Fault-aware training is the state-of-the-art approach for mitigating such faults. However, it incurs huge retraining overheads, specifically when used for large DNNs trained on complex datasets. To address this issue, we propose a novel Fault-Aware Quantization (FAQ) technique for mitigating the effects of stuck-at permanent faults in the on-chip weight memory of DNN accelerators at a negligible overhead cost compared to fault-aware retraining while offering comparable accuracy results. We propose a lookup table-based algorithm to achieve ultra-low model conversion time. We present extensive evaluation of the proposed approach using five different DNNs, i.e., ResNet-18, VGG11, VGG16, AlexNet and MobileNetV2, and three different datasets, i.e., CIFAR-10, CIFAR-100 and ImageNet. The results demonstrate that FAQ helps in maintaining the baseline accuracy of the DNNs at low and moderate fault rates without involving costly fault-aware training. For example, for ResNet-18 trained on the CIFAR-10 dataset, at 0.04 fault rate FAQ offers (on average) an increase of 76.38% in accuracy. Similarly, for VGG11 trained on the CIFAR-10 dataset, at 0.04 fault rate FAQ offers (on average) an increase of 70.47% in accuracy. The results also show that FAQ incurs negligible overheads, i.e., less than 5% of the time required to run 1 epoch of retraining. We additionally demonstrate the efficacy of our technique when used in conjunction with fault-aware retraining and show that the use of FAQ inside fault-aware retraining enables fast accuracy recovery.
DAP: A Dynamic Adversarial Patch for Evading Person Detectors
May 19, 2023



In this paper, we present a novel approach for generating naturalistic adversarial patches without using GANs. Our proposed approach generates a Dynamic Adversarial Patch (DAP) that looks naturalistic while maintaining high attack efficiency and robustness in real-world scenarios. To achieve this, we redefine the optimization problem by introducing a new objective function, where a similarity metric is used to construct a similarity loss. This guides the patch to follow predefined patterns while maximizing the victim model's loss function. Our technique is based on directly modifying the pixel values in the patch which gives higher flexibility and larger space to incorporate multiple transformations compared to the GAN-based techniques. Furthermore, most clothing-based physical attacks assume static objects and ignore the possible transformations caused by non-rigid deformation due to changes in a person's pose. To address this limitation, we incorporate a ``Creases Transformation'' (CT) block, i.e., a preprocessing block following an Expectation Over Transformation (EOT) block used to generate a large variation of transformed patches incorporated in the training process to increase its robustness to different possible real-world distortions (e.g., creases in the clothing, rotation, re-scaling, random noise, brightness and contrast variations, etc.). We demonstrate that the presence of different real-world variations in clothing and object poses (i.e., above-mentioned distortions) lead to a drop in the performance of state-of-the-art attacks. For instance, these techniques can merely achieve 20\% in the physical world and 30.8\% in the digital world while our attack provides superior success rate of up to 65\% and 84.56\%, respectively when attacking the YOLOv3tiny detector deployed in smart cameras at the edge.
eFAT: Improving the Effectiveness of Fault-Aware Training for Mitigating Permanent Faults in DNN Hardware Accelerators
Apr 20, 2023



Fault-Aware Training (FAT) has emerged as a highly effective technique for addressing permanent faults in DNN accelerators, as it offers fault mitigation without significant performance or accuracy loss, specifically at low and moderate fault rates. However, it leads to very high retraining overheads, especially when used for large DNNs designed for complex AI applications. Moreover, as each fabricated chip can have a distinct fault pattern, FAT is required to be performed for each faulty chip individually, considering its unique fault map, which further aggravates the problem. To reduce the overheads of FAT while maintaining its benefits, we propose (1) the concepts of resilience-driven retraining amount selection, and (2) resilience-driven grouping and fusion of multiple fault maps (belonging to different chips) to perform consolidated retraining for a group of faulty chips. To realize these concepts, in this work, we present a novel framework, eFAT, that computes the resilience of a given DNN to faults at different fault rates and with different levels of retraining, and it uses that knowledge to build a resilience map given a user-defined accuracy constraint. Then, it uses the resilience map to compute the amount of retraining required for each chip, considering its unique fault map. Afterward, it performs resilience and reward-driven grouping and fusion of fault maps to further reduce the number of retraining iterations required for tuning the given DNN for the given set of faulty chips. We demonstrate the effectiveness of our framework for a systolic array-based DNN accelerator experiencing permanent faults in the computational array. Our extensive results for numerous chips show that the proposed technique significantly reduces the retraining cost when used for tuning a DNN for multiple faulty chips.
EnforceSNN: Enabling Resilient and Energy-Efficient Spiking Neural Network Inference considering Approximate DRAMs for Embedded Systems
Apr 08, 2023



Spiking Neural Networks (SNNs) have shown capabilities of achieving high accuracy under unsupervised settings and low operational power/energy due to their bio-plausible computations. Previous studies identified that DRAM-based off-chip memory accesses dominate the energy consumption of SNN processing. However, state-of-the-art works do not optimize the DRAM energy-per-access, thereby hindering the SNN-based systems from achieving further energy efficiency gains. To substantially reduce the DRAM energy-per-access, an effective solution is to decrease the DRAM supply voltage, but it may lead to errors in DRAM cells (i.e., so-called approximate DRAM). Towards this, we propose \textit{EnforceSNN}, a novel design framework that provides a solution for resilient and energy-efficient SNN inference using reduced-voltage DRAM for embedded systems. The key mechanisms of our EnforceSNN are: (1) employing quantized weights to reduce the DRAM access energy; (2) devising an efficient DRAM mapping policy to minimize the DRAM energy-per-access; (3) analyzing the SNN error tolerance to understand its accuracy profile considering different bit error rate (BER) values; (4) leveraging the information for developing an efficient fault-aware training (FAT) that considers different BER values and bit error locations in DRAM to improve the SNN error tolerance; and (5) developing an algorithm to select the SNN model that offers good trade-offs among accuracy, memory, and energy consumption. The experimental results show that our EnforceSNN maintains the accuracy (i.e., no accuracy loss for BER less-or-equal 10^-3) as compared to the baseline SNN with accurate DRAM, while achieving up to 84.9\% of DRAM energy saving and up to 4.1x speed-up of DRAM data throughput across different network sizes.
RescueSNN: Enabling Reliable Executions on Spiking Neural Network Accelerators under Permanent Faults
Apr 08, 2023



To maximize the performance and energy efficiency of Spiking Neural Network (SNN) processing on resource-constrained embedded systems, specialized hardware accelerators/chips are employed. However, these SNN chips may suffer from permanent faults which can affect the functionality of weight memory and neuron behavior, thereby causing potentially significant accuracy degradation and system malfunctioning. Such permanent faults may come from manufacturing defects during the fabrication process, and/or from device/transistor damages (e.g., due to wear out) during the run-time operation. However, the impact of permanent faults in SNN chips and the respective mitigation techniques have not been thoroughly investigated yet. Toward this, we propose RescueSNN, a novel methodology to mitigate permanent faults in the compute engine of SNN chips without requiring additional retraining, thereby significantly cutting down the design time and retraining costs, while maintaining the throughput and quality. The key ideas of our RescueSNN methodology are (1) analyzing the characteristics of SNN under permanent faults; (2) leveraging this analysis to improve the SNN fault-tolerance through effective fault-aware mapping (FAM); and (3) devising lightweight hardware enhancements to support FAM. Our FAM technique leverages the fault map of SNN compute engine for (i) minimizing weight corruption when mapping weight bits on the faulty memory cells, and (ii) selectively employing faulty neurons that do not cause significant accuracy degradation to maintain accuracy and throughput, while considering the SNN operations and processing dataflow. The experimental results show that our RescueSNN improves accuracy by up to 80% while maintaining the throughput reduction below 25% in high fault rate (e.g., 0.5 of the potential fault locations), as compared to running SNNs on the faulty chip without mitigation.
Exploring Machine Learning Privacy/Utility trade-off from a hyperparameters Lens
Mar 03, 2023



Machine Learning (ML) architectures have been applied to several applications that involve sensitive data, where a guarantee of users' data privacy is required. Differentially Private Stochastic Gradient Descent (DPSGD) is the state-of-the-art method to train privacy-preserving models. However, DPSGD comes at a considerable accuracy loss leading to sub-optimal privacy/utility trade-offs. Towards investigating new ground for better privacy-utility trade-off, this work questions; (i) if models' hyperparameters have any inherent impact on ML models' privacy-preserving properties, and (ii) if models' hyperparameters have any impact on the privacy/utility trade-off of differentially private models. We propose a comprehensive design space exploration of different hyperparameters such as the choice of activation functions, the learning rate and the use of batch normalization. Interestingly, we found that utility can be improved by using Bounded RELU as activation functions with the same privacy-preserving characteristics. With a drop-in replacement of the activation function, we achieve new state-of-the-art accuracy on MNIST (96.02\%), FashionMnist (84.76\%), and CIFAR-10 (44.42\%) without any modification of the learning procedure fundamentals of DPSGD.
AdvRain: Adversarial Raindrops to Attack Camera-based Smart Vision Systems
Mar 02, 2023



Vision-based perception modules are increasingly deployed in many applications, especially autonomous vehicles and intelligent robots. These modules are being used to acquire information about the surroundings and identify obstacles. Hence, accurate detection and classification are essential to reach appropriate decisions and take appropriate and safe actions at all times. Current studies have demonstrated that "printed adversarial attacks", known as physical adversarial attacks, can successfully mislead perception models such as object detectors and image classifiers. However, most of these physical attacks are based on noticeable and eye-catching patterns for generated perturbations making them identifiable/detectable by human eye or in test drives. In this paper, we propose a camera-based inconspicuous adversarial attack (\textbf{AdvRain}) capable of fooling camera-based perception systems over all objects of the same class. Unlike mask based fake-weather attacks that require access to the underlying computing hardware or image memory, our attack is based on emulating the effects of a natural weather condition (i.e., Raindrops) that can be printed on a translucent sticker, which is externally placed over the lens of a camera. To accomplish this, we provide an iterative process based on performing a random search aiming to identify critical positions to make sure that the performed transformation is adversarial for a target classifier. Our transformation is based on blurring predefined parts of the captured image corresponding to the areas covered by the raindrop. We achieve a drop in average model accuracy of more than $45\%$ and $40\%$ on VGG19 for ImageNet and Resnet34 for Caltech-101, respectively, using only $20$ raindrops.