 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Acoustic Features for Robust ASR
Sep 24, 2024



Automatic Speech Recognition (ASR) systems must be robust to the myriad types of noises present in real-world environments including environmental noise, room impulse response, special effects as well as attacks by malicious actors (adversarial attacks). Recent works seek to improve accuracy and robustness by developing novel Deep Neural Networks (DNNs) and curating diverse training datasets for them, while using relatively simple acoustic features. While this approach improves robustness to the types of noise present in the training data, it confers limited robustness against unseen noises and negligible robustness to adversarial attacks. In this paper, we revisit the approach of earlier works that developed acoustic features inspired by biological auditory perception that could be used to perform accurate and robust ASR. In contrast, Specifically, we evaluate the ASR accuracy and robustness of several biologically inspired acoustic features. In addition to several features from prior works, such as gammatone filterbank features (GammSpec), we also propose two new acoustic features called frequency masked spectrogram (FreqMask) and difference of gammatones spectrogram (DoGSpec) to simulate the neuro-psychological phenomena of frequency masking and lateral suppression. Experiments on diverse models and datasets show that (1) DoGSpec achieves significantly better robustness than the highly popular log mel spectrogram (LogMelSpec) with minimal accuracy degradation, and (2) GammSpec achieves better accuracy and robustness to non-adversarial noises from the Speech Robust Bench benchmark, but it is outperformed by DoGSpec against adversarial attacks.
Speech Robust Bench: A Robustness Benchmark For Speech Recognition
Mar 08, 2024



As Automatic Speech Recognition (ASR) models become ever more pervasive, it is important to ensure that they make reliable predictions under corruptions present in the physical and digital world. We propose Speech Robust Bench (SRB), a comprehensive benchmark for evaluating the robustness of ASR models to diverse corruptions. SRB is composed of 69 input perturbations which are intended to simulate various corruptions that ASR models may encounter in the physical and digital world. We use SRB to evaluate the robustness of several state-of-the-art ASR models and observe that model size and certain modeling choices such as discrete representations, and self-training appear to be conducive to robustness. We extend this analysis to measure the robustness of ASR models on data from various demographic subgroups, namely English and Spanish speakers, and males and females, and observed noticeable disparities in the model's robustness across subgroups. We believe that SRB will facilitate future research towards robust ASR models, by making it easier to conduct comprehensive and comparable robustness evaluations.
Training on Foveated Images Improves Robustness to Adversarial Attacks
Aug 01, 2023Deep neural networks (DNNs) have been shown to be vulnerable to adversarial attacks -- subtle, perceptually indistinguishable perturbations of inputs that change the response of the model. In the context of vision, we hypothesize that an important contributor to the robustness of human visual perception is constant exposure to low-fidelity visual stimuli in our peripheral vision. To investigate this hypothesis, we develop \RBlur, an image transform that simulates the loss in fidelity of peripheral vision by blurring the image and reducing its color saturation based on the distance from a given fixation point. We show that compared to DNNs trained on the original images, DNNs trained on images transformed by \RBlur are substantially more robust to adversarial attacks, as well as other, non-adversarial, corruptions, achieving up to 25\% higher accuracy on perturbed data.
Reasoning Over History: Context Aware Visual Dialog
Nov 02, 2020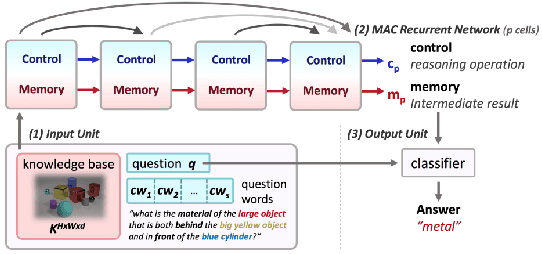
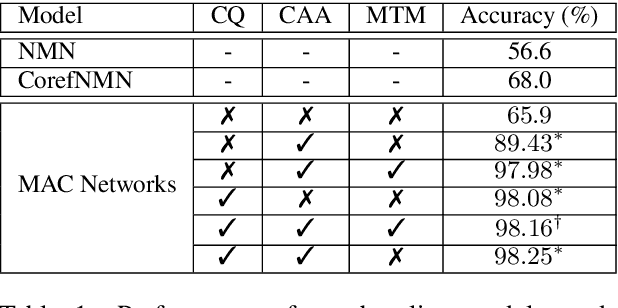
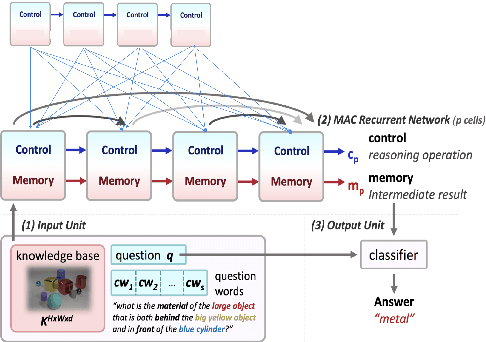

While neural models have been shown to exhibit strong performance on single-turn visual question answering (VQA) tasks, extending VQA to a multi-turn, conversational setting remains a challenge. One way to address this challenge is to augment existing strong neural VQA models with the mechanisms that allow them to retain information from previous dialog turns. One strong VQA model is the MAC network, which decomposes a task into a series of attention-based reasoning steps. However, since the MAC network is designed for single-turn question answering, it is not capable of referring to past dialog turns. More specifically, it struggles with tasks that require reasoning over the dialog history, particularly coreference resolution. We extend the MAC network architecture with Context-aware Attention and Memory (CAM), which attends over control states in past dialog turns to determine the necessary reasoning operations for the current question. MAC nets with CAM achieve up to 98.25% accuracy on the CLEVR-Dialog dataset, beating the existing state-of-the-art by 30% (absolute). Our error analysis indicates that with CAM, the model's performance particularly improved on questions that required coreference resolution.
Exploiting Non-Linear Redundancy for Neural Model Compression
May 28, 2020
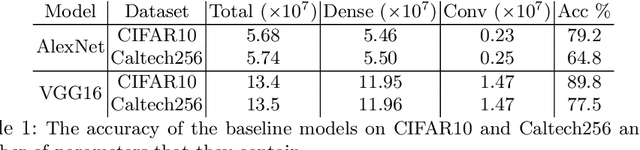
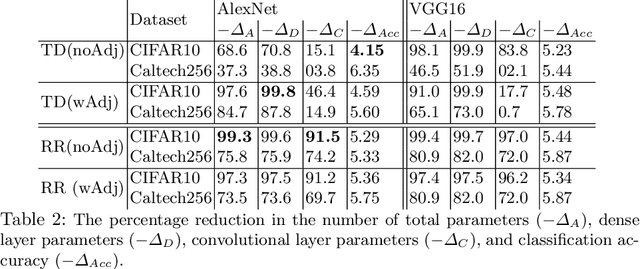
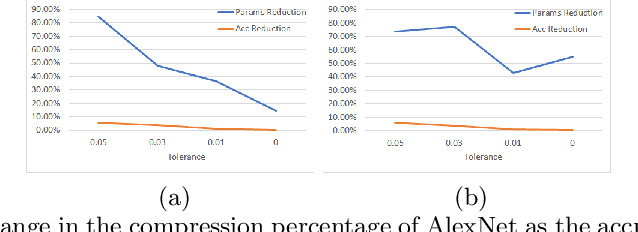
Deploying deep learning models, comprising of non-linear combination of millions, even billions, of parameters is challenging given the memory, power and compute constraints of the real world. This situation has led to research into model compression techniques most of which rely on suboptimal heuristics and do not consider the parameter redundancies due to linear dependence between neuron activations in overparametrized networks. In this paper, we propose a novel model compression approach based on exploitation of linear dependence, that compresses networks by elimination of entire neurons and redistribution of their activations over other neurons in a manner that is provably lossless while training. We combine this approach with an annealing algorithm that may be applied during training, or even on a trained model, and demonstrate, using popular datasets, that our method results in a reduction of up to 99\% in overall network size with small loss in performance. Furthermore, we provide theoretical results showing that in overparametrized, locally linear (ReLU) neural networks where redundant features exist, and with correct hyperparameter selection, our method is indeed able to capture and suppress those dependencies.