 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Zero Constraint Violation for Constrained Reinforcement Learning via Primal-Dual Approach
Sep 13, 2021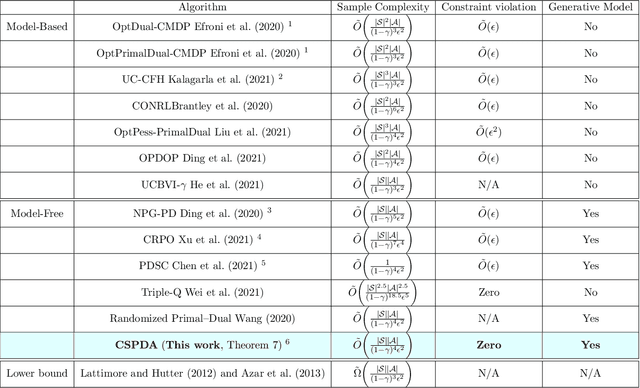
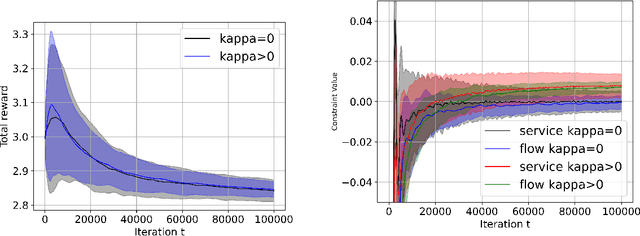
Reinforcement learning is widely used in applications where one needs to perform sequential decisions while interacting with the environment. The problem becomes more challenging when the decision requirement includes satisfying some safety constraints. The problem is mathematically formulated as constrained Markov decision process (CMDP). In the literature, various algorithms are available to solve CMDP problems in a model-free manner to achieve $\epsilon$-optimal cumulative reward with $\epsilon$ feasible policies. An $\epsilon$-feasible policy implies that it suffers from constraint violation. An important question here is whether we can achieve $\epsilon$-optimal cumulative reward with zero constraint violations or not. To achieve that, we advocate the use of a randomized primal-dual approach to solving the CMDP problems and propose a conservative stochastic primal-dual algorithm (CSPDA) which is shown to exhibit $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity to achieve $\epsilon$-optimal cumulative reward with zero constraint violations. In the prior works, the best available sample complexity for the $\epsilon$-optimal policy with zero constraint violation is $\tilde{\mathcal{O}}(1/\epsilon^5)$. Hence, the proposed algorithm provides a significant improvement as compared to the state of the art.
Concave Utility Reinforcement Learning with Zero-Constraint Violations
Sep 12, 2021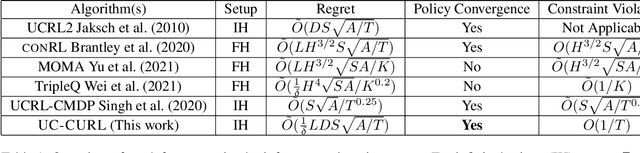
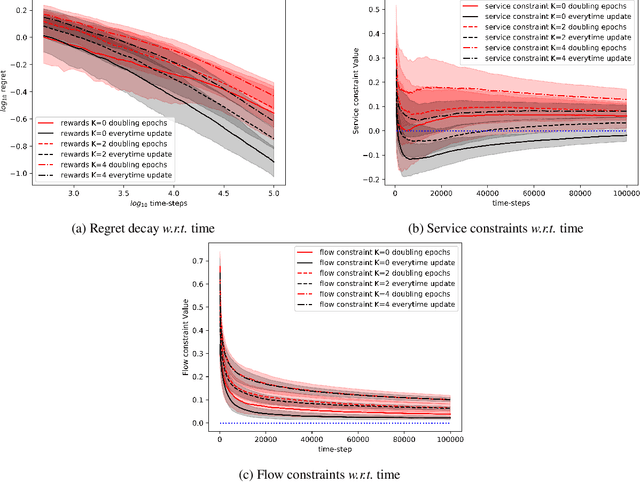
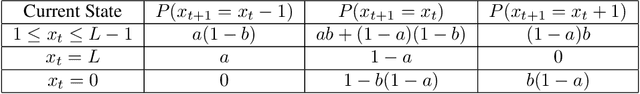
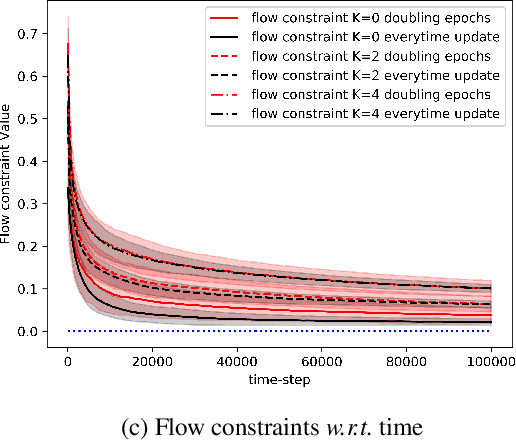
We consider the problem of tabular infinite horizon concave utility reinforcement learning (CURL) with convex constraints. Various learning applications with constraints, such as robotics, do not allow for policies that can violate constraints. To this end, we propose a model-based learning algorithm that achieves zero constraint violations. To obtain this result, we assume that the concave objective and the convex constraints have a solution interior to the set of feasible occupation measures. We then solve a tighter optimization problem to ensure that the constraints are never violated despite the imprecise model knowledge and model stochasticity. We also propose a novel Bellman error based analysis for tabular infinite-horizon setups which allows to analyse stochastic policies. Combining the Bellman error based analysis and tighter optimization equation, for $T$ interactions with the environment, we obtain a regret guarantee for objective which grows as $\Tilde{O}(1/\sqrt{T})$, excluding other factors.
On the Approximation of Cooperative Heterogeneous Multi-Agent Reinforcement Learning (MARL) using Mean Field Control (MFC)
Sep 09, 2021Mean field control (MFC) is an effective way to mitigate the curse of dimensionality of cooperative multi-agent reinforcement learning (MARL) problems. This work considers a collection of $N_{\mathrm{pop}}$ heterogeneous agents that can be segregated into $K$ classes such that the $k$-th class contains $N_k$ homogeneous agents. We aim to prove approximation guarantees of the MARL problem for this heterogeneous system by its corresponding MFC problem. We consider three scenarios where the reward and transition dynamics of all agents are respectively taken to be functions of $(1)$ joint state and action distributions across all classes, $(2)$ individual distributions of each class, and $(3)$ marginal distributions of the entire population. We show that, in these cases, the $K$-class MARL problem can be approximated by MFC with errors given as $e_1=\mathcal{O}(\frac{\sqrt{|\mathcal{X}||\mathcal{U}|}}{N_{\mathrm{pop}}}\sum_{k}\sqrt{N_k})$, $e_2=\mathcal{O}(\sqrt{|\mathcal{X}||\mathcal{U}|}\sum_{k}\frac{1}{\sqrt{N_k}})$ and $e_3=\mathcal{O}\left(\sqrt{|\mathcal{X}||\mathcal{U}|}\left[\frac{A}{N_{\mathrm{pop}}}\sum_{k\in[K]}\sqrt{N_k}+\frac{B}{\sqrt{N_{\mathrm{pop}}}}\right]\right)$, respectively, where $A, B$ are some constants and $|\mathcal{X}|,|\mathcal{U}|$ are the sizes of state and action spaces of each agent. Finally, we design a Natural Policy Gradient (NPG) based algorithm that, in the three cases stated above, can converge to an optimal MARL policy within $\mathcal{O}(e_j)$ error with a sample complexity of $\mathcal{O}(e_j^{-3})$, $j\in\{1,2,3\}$, respectively.
Markov Decision Processes with Long-Term Average Constraints
Jun 12, 2021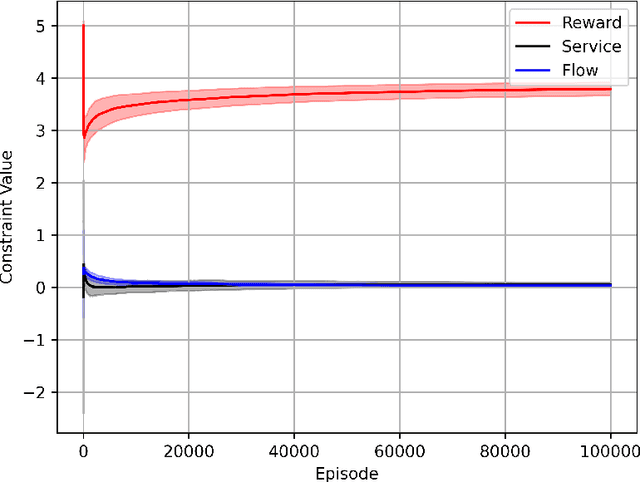

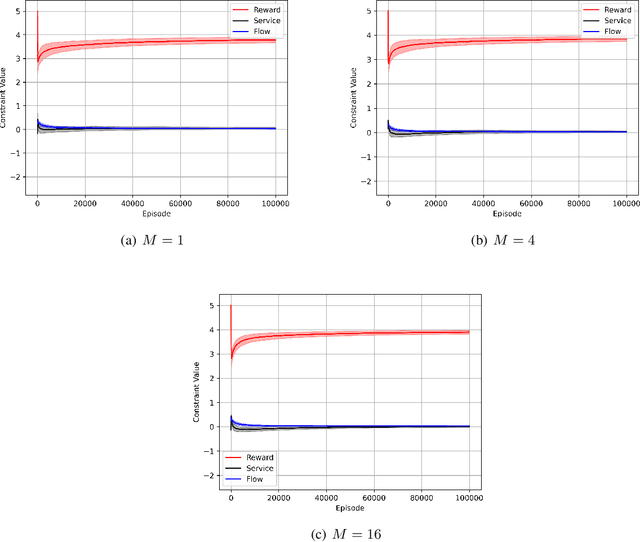
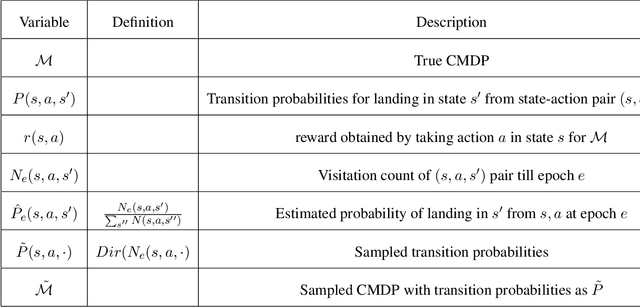
We consider the problem of constrained Markov Decision Process (CMDP) where an agent interacts with a unichain Markov Decision Process. At every interaction, the agent obtains a reward. Further, there are $K$ cost functions. The agent aims to maximize the long-term average reward while simultaneously keeping the $K$ long-term average costs lower than a certain threshold. In this paper, we propose CMDP-PSRL, a posterior sampling based algorithm using which the agent can learn optimal policies to interact with the CMDP. Further, for MDP with $S$ states, $A$ actions, and diameter $D$, we prove that following CMDP-PSRL algorithm, the agent can bound the regret of not accumulating rewards from optimal policy by $\Tilde{O}(poly(DSA)\sqrt{T})$. Further, we show that the violations for any of the $K$ constraints is also bounded by $\Tilde{O}(poly(DSA)\sqrt{T})$. To the best of our knowledge, this is the first work which obtains a $\Tilde{O}(\sqrt{T})$ regret bounds for ergodic MDPs with long-term average constraints.
Joint Optimization of Multi-Objective Reinforcement Learning with Policy Gradient Based Algorithm
May 28, 2021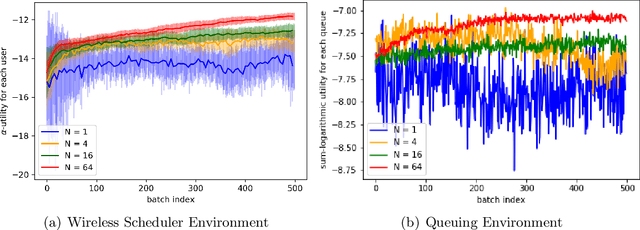
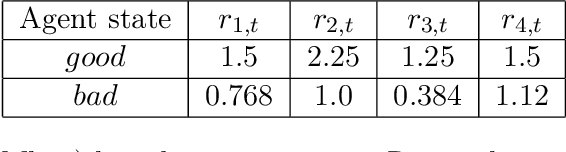
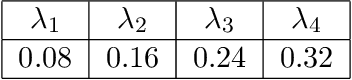
Many engineering problems have multiple objectives, and the overall aim is to optimize a non-linear function of these objectives. In this paper, we formulate the problem of maximizing a non-linear concave function of multiple long-term objectives. A policy-gradient based model-free algorithm is proposed for the problem. To compute an estimate of the gradient, a biased estimator is proposed. The proposed algorithm is shown to achieve convergence to within an $\epsilon$ of the global optima after sampling $\mathcal{O}(\frac{M^4\sigma^2}{(1-\gamma)^8\epsilon^4})$ trajectories where $\gamma$ is the discount factor and $M$ is the number of the agents, thus achieving the same dependence on $\epsilon$ as the policy gradient algorithm for the standard reinforcement learning.
Communication Efficient Parallel Reinforcement Learning
Feb 22, 2021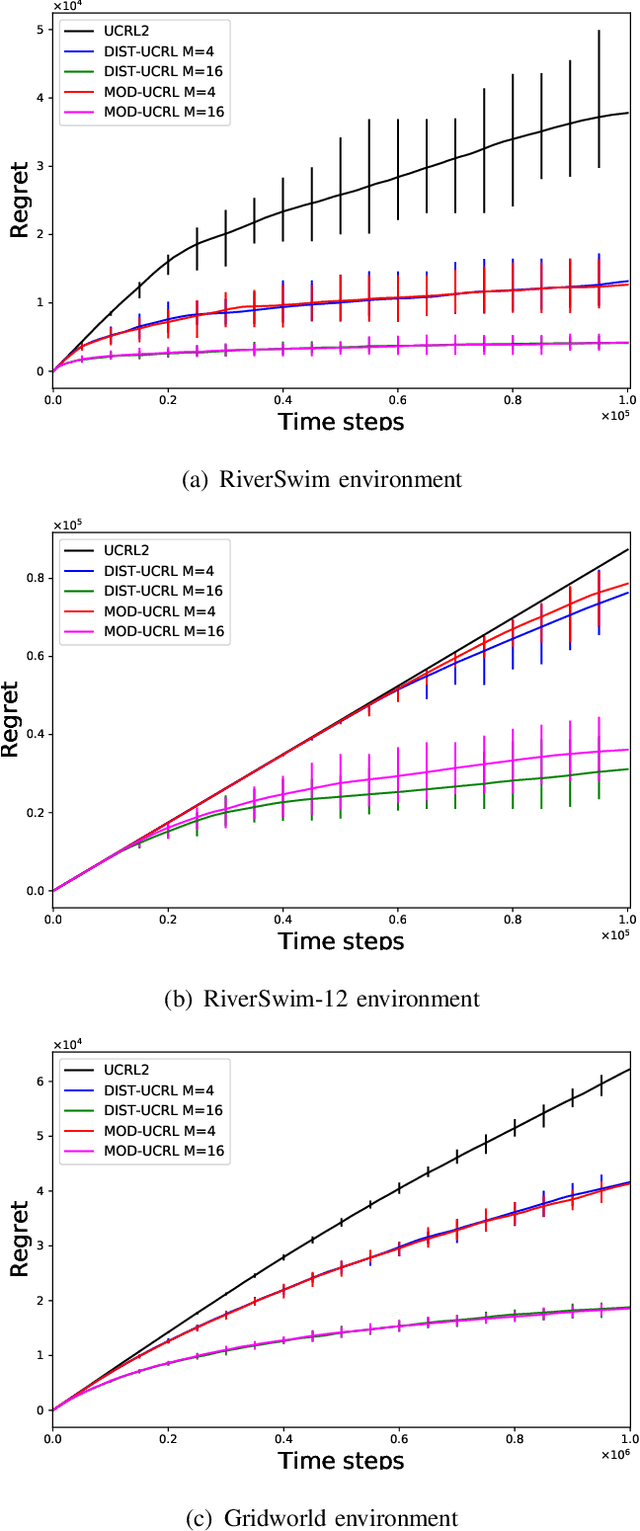
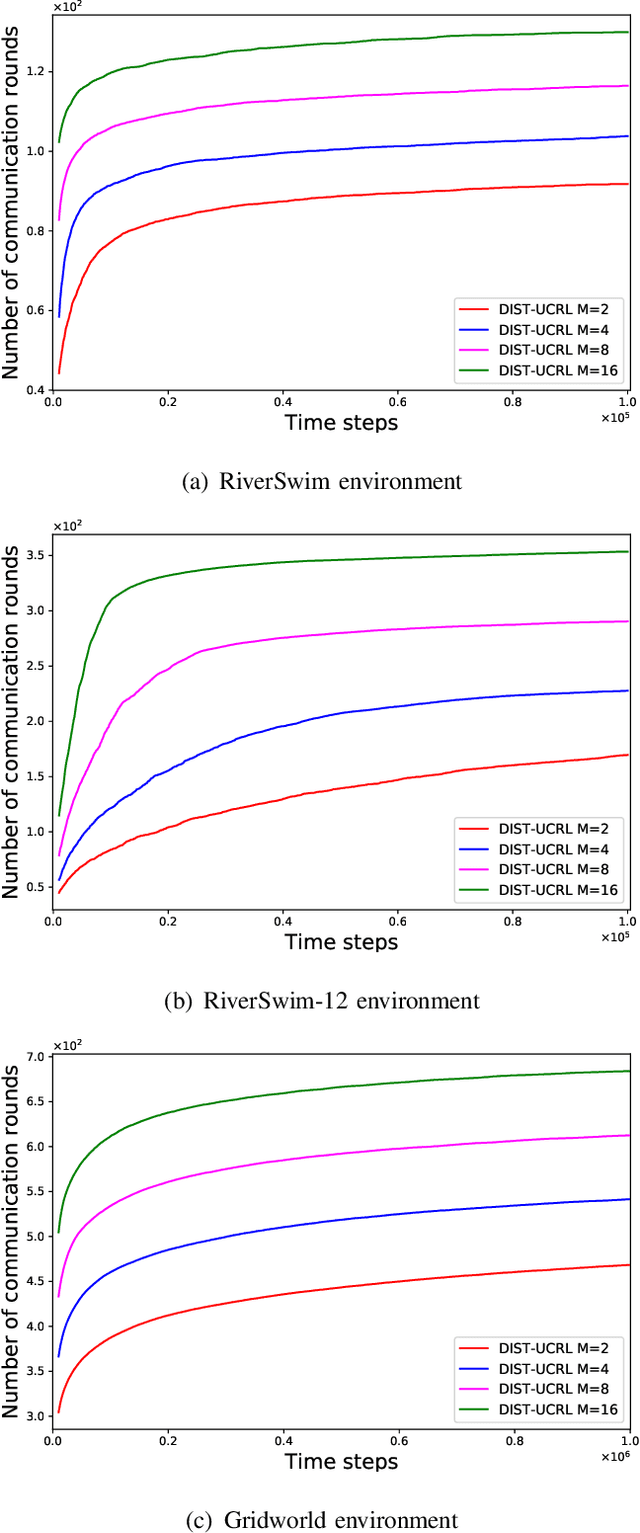
We consider the problem where $M$ agents interact with $M$ identical and independent environments with $S$ states and $A$ actions using reinforcement learning for $T$ rounds. The agents share their data with a central server to minimize their regret. We aim to find an algorithm that allows the agents to minimize the regret with infrequent communication rounds. We provide \NAM\ which runs at each agent and prove that the total cumulative regret of $M$ agents is upper bounded as $\Tilde{O}(DS\sqrt{MAT})$ for a Markov Decision Process with diameter $D$, number of states $S$, and number of actions $A$. The agents synchronize after their visitations to any state-action pair exceeds a certain threshold. Using this, we obtain a bound of $O\left(MSA\log(MT)\right)$ on the total number of communications rounds. Finally, we evaluate the algorithm against multiple environments and demonstrate that the proposed algorithm performs at par with an always communication version of the UCRL2 algorithm, while with significantly lower communication.
Multi-Agent Multi-Armed Bandits with Limited Communication
Feb 10, 2021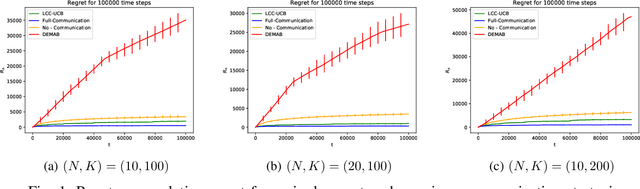
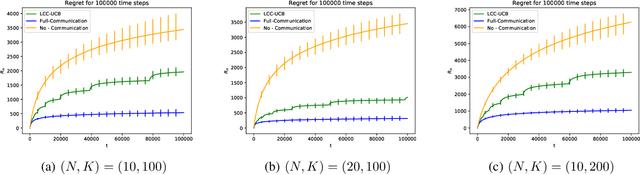
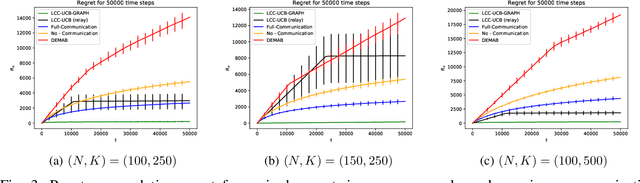
We consider the problem where $N$ agents collaboratively interact with an instance of a stochastic $K$ arm bandit problem for $K \gg N$. The agents aim to simultaneously minimize the cumulative regret over all the agents for a total of $T$ time steps, the number of communication rounds, and the number of bits in each communication round. We present Limited Communication Collaboration - Upper Confidence Bound (LCC-UCB), a doubling-epoch based algorithm where each agent communicates only after the end of the epoch and shares the index of the best arm it knows. With our algorithm, LCC-UCB, each agent enjoys a regret of $\tilde{O}\left(\sqrt{({K/N}+ N)T}\right)$, communicates for $O(\log T)$ steps and broadcasts $O(\log K)$ bits in each communication step. We extend the work to sparse graphs with maximum degree $K_G$, and diameter $D$ and propose LCC-UCB-GRAPH which enjoys a regret bound of $\tilde{O}\left(D\sqrt{(K/N+ K_G)DT}\right)$. Finally, we empirically show that the LCC-UCB and the LCC-UCB-GRAPH algorithm perform well and outperform strategies that communicate through a central node
Blind Decision Making: Reinforcement Learning with Delayed Observations
Nov 16, 2020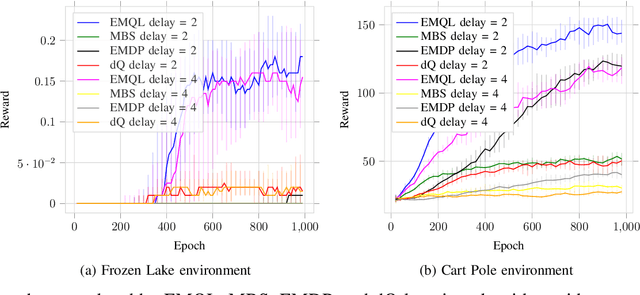
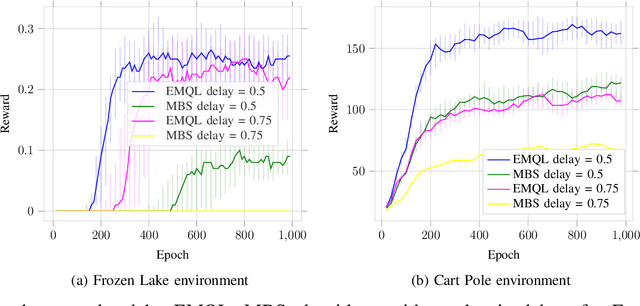
Reinforcement learning typically assumes that the state update from the previous actions happens instantaneously, and thus can be used for making future decisions. However, this may not always be true. When the state update is not available, the decision taken is partly in the blind since it cannot rely on the current state information. This paper proposes an approach, where the delay in the knowledge of the state can be used, and the decisions are made based on the available information which may not include the current state information. One approach could be to include the actions after the last-known state as a part of the state information, however, that leads to an increased state-space making the problem complex and slower in convergence. The proposed algorithm gives an alternate approach where the state space is not enlarged, as compared to the case when there is no delay in the state update. Evaluations on the basic RL environments further illustrate the improved performance of the proposed algorithm.
DART: aDaptive Accept RejecT for non-linear top-K subset identification
Nov 16, 2020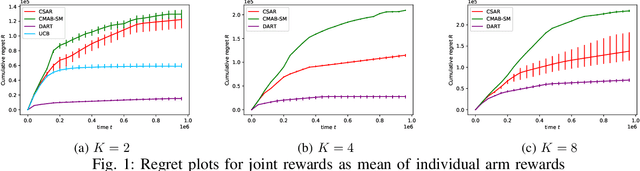
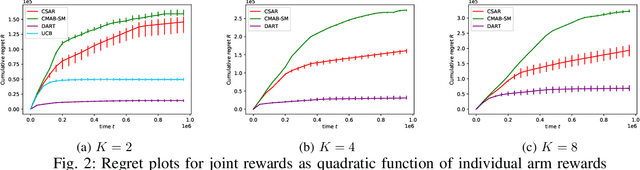
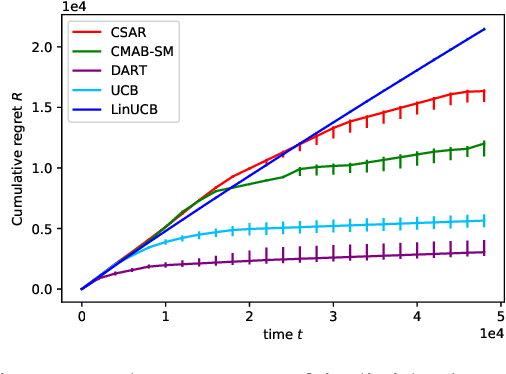
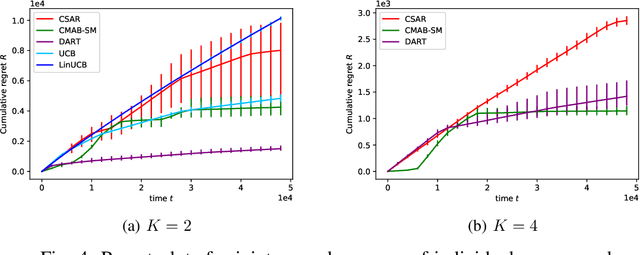
We consider the bandit problem of selecting $K$ out of $N$ arms at each time step. The reward can be a non-linear function of the rewards of the selected individual arms. The direct use of a multi-armed bandit algorithm requires choosing among $\binom{N}{K}$ options, making the action space large. To simplify the problem, existing works on combinatorial bandits {typically} assume feedback as a linear function of individual rewards. In this paper, we prove the lower bound for top-$K$ subset selection with bandit feedback with possibly correlated rewards. We present a novel algorithm for the combinatorial setting without using individual arm feedback or requiring linearity of the reward function. Additionally, our algorithm works on correlated rewards of individual arms. Our algorithm, aDaptive Accept RejecT (DART), sequentially finds good arms and eliminates bad arms based on confidence bounds. DART is computationally efficient and uses storage linear in $N$. Further, DART achieves a regret bound of $\tilde{\mathcal{O}}(K\sqrt{KNT})$ for a time horizon $T$, which matches the lower bound in bandit feedback up to a factor of $\sqrt{\log{2NT}}$. When applied to the problem of cross-selling optimization and maximizing the mean of individual rewards, the performance of the proposed algorithm surpasses that of state-of-the-art algorithms. We also show that DART significantly outperforms existing methods for both linear and non-linear joint reward environments.
Escaping Saddle Points for Zeroth-order Nonconvex Optimization using Estimated Gradient Descent
Oct 03, 2019Gradient descent and its variants are widely used in machine learning. However, oracle access of gradient may not be available in many applications, limiting the direct use of gradient descent. This paper proposes a method of estimating gradient to perform gradient descent, that converges to a stationary point for general non-convex optimization problems. Beyond the first-order stationary properties, the second-order stationary properties are important in machine learning applications to achieve better performance. We show that the proposed model-free non-convex optimization algorithm returns an $\epsilon$-second-order stationary point with $\widetilde{O}(\frac{d^{2+\frac{\theta}{2}}}{\epsilon^{8+\theta}})$ queries of the function for any arbitrary $\theta>0$.