 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenger at MultiPRIDE: Is It Hate Speech or Reclaimed?
May 31, 2026The spread of hate speech has become increasingly harmful in modern digital environments, particularly on social networking platforms. While recent advances have shown promising results in automatic hate speech detection, a key challenge remains: distinguishing genuine hate speech from reclaimed language. Accurate labeling is difficult due to the nuanced and context-dependent nature of reclaimed expressions. In this paper, we present a simple and interpretable approach for distinguishing hate speech from reclaimed language, developed for the MultiPride Shared Task. Our method generates dense semantic text embeddings and incorporates a label-noise filtering stage using Cleanlab with logistic regression, followed by a Multi-layer Perceptron (MLP) neural network for final classification. The system is designed to operate under limited computational resources while maintaining strong performance. We evaluate our approach using precision, recall, and F1-score, including macro-averaged metrics. Experimental results demonstrate robust performance despite extreme class imbalance in the dataset. Overall, the findings highlight the potential for further improvements through larger embedding models and more advanced preprocessing techniques while preserving interpretability.
* 9 pages, 2 figures, Published in EVALITA 2026, CEUR Workshop Proceedings Vol. 4195
Peacemaker at ATE-IT: Automatic term extraction from Italian text for waste management data using encoder model
May 31, 2026The development of automatic term extraction has become increasingly important in modern technology. Automatic term extraction can be found in virtually every search engine that is currently available to users. Recent advancements have provided promising results for the extraction of automatic terms; however, accurate labeling is difficult because of several factors, such as the limited number of annotated documents available for training and the complexity of extracting multi-word expressions due to shifts in the domain. In this paper, we will present a low-cost and interpretable method of automatic term extraction, developed specifically for Task A of the ATE Shared Task. This new method utilizes fine-tuning extraction strategies that can run on a small amount of computational resources. We evaluated our automated system using both type-level and micro-level measures of precision, recall, and F1-score to measure both complementary aspects of the extraction performance. According to the experimental results, our proposed approach achieves consistent and balanced performance compared to other teams. Even though the technique itself is relatively straightforward, it serves as a good starting point for low-resource models. Overall, the findings point toward the possibility of significant future advancements (in model expansion) with higher-level performance still able to retain their ability to be interpreted.
* 9 pages, 2 figures, Published in EVALITA 2026, CEUR Workshop Proceedings Vol. 4195
Simorgh at SemEval-2026 task 7: Region-Aware Hybrid Retrieval for Low-Resource Cultural Reasoning in Multilingual Question Answering
May 26, 2026Although Large Language Models (LLMs) demonstrate excellent capabilities and performance for general reasoning tasks within the general public domain, they may face challenges with culturally grounded knowledge within languages with limited digital and textual data. In this paper, we investigate culturally grounded multiple-choice question answering with the BLEnD benchmark, which consists of a multilingual corpus of 30 languages and covers various socio-cultural domains, such as cuisine, sports, family, etc. We propose a region-aware hybrid retrieval approach that combines BM25 lexical matching and dense semantic similarity with regional weighting heuristics to improve the relevance of the answer. The retrieved documents are used to construct a structured prompt for the Qwen3-14B quantized model with logit-based deterministic answer selection. The experimental results show improvements to cross-lingual stability with the hybrid retrieval approach over pure parametric inference for culturally grounded question answering. However, there are still notable performance gaps between languages with more and less training data. This shows that the limitations of the retrieval augmentation approach are not entirely overcome by the training data imbalance problem.
Homa at SemEval-2025 Task 5: Aligning Librarian Records with OntoAligner for Subject Tagging
Apr 30, 2025



This paper presents our system, Homa, for SemEval-2025 Task 5: Subject Tagging, which focuses on automatically assigning subject labels to technical records from TIBKAT using the Gemeinsame Normdatei (GND) taxonomy. We leverage OntoAligner, a modular ontology alignment toolkit, to address this task by integrating retrieval-augmented generation (RAG) techniques. Our approach formulates the subject tagging problem as an alignment task, where records are matched to GND categories based on semantic similarity. We evaluate OntoAligner's adaptability for subject indexing and analyze its effectiveness in handling multilingual records. Experimental results demonstrate the strengths and limitations of this method, highlighting the potential of alignment techniques for improving subject tagging in digital libraries.
Jointly Modeling Aspect and Polarity for Aspect-based Sentiment Analysis in Persian Reviews
Sep 19, 2021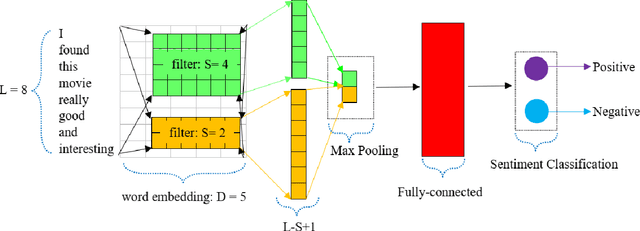
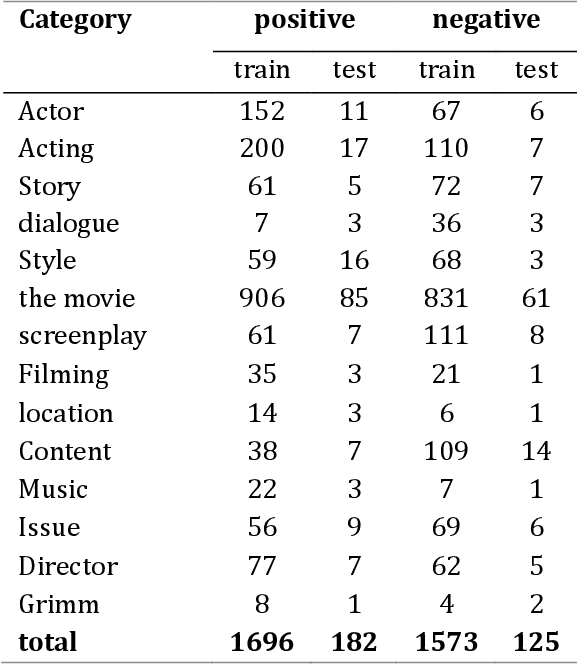
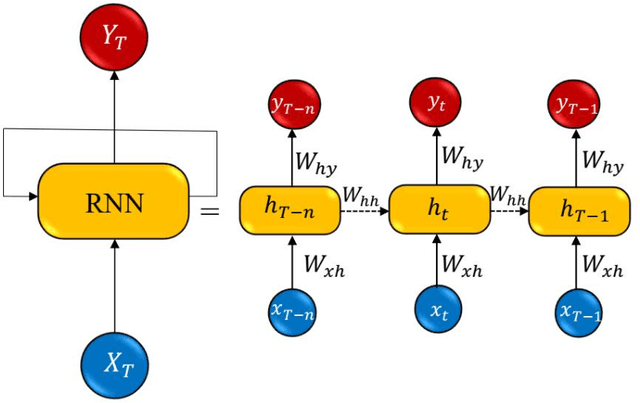
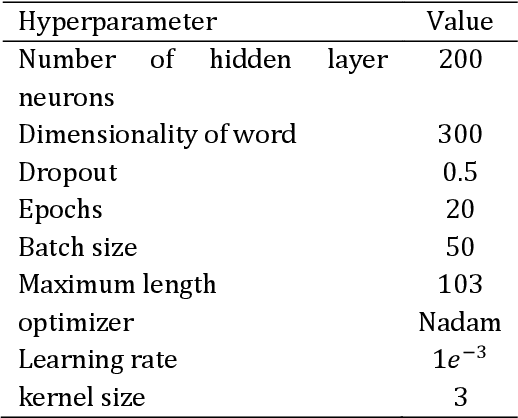
Identification of user's opinions from natural language text has become an exciting field of research due to its growing applications in the real world. The research field is known as sentiment analysis and classification, where aspect category detection (ACD) and aspect category polarity (ACP) are two important sub-tasks of aspect-based sentiment analysis. The goal in ACD is to specify which aspect of the entity comes up in opinion while ACP aims to specify the polarity of each aspect category from the ACD task. The previous works mostly propose separate solutions for these two sub-tasks. This paper focuses on the ACD and ACP sub-tasks to solve both problems simultaneously. The proposed method carries out multi-label classification where four different deep models were employed and comparatively evaluated to examine their performance. A dataset of Persian reviews was collected from CinemaTicket website including 2200 samples from 14 categories. The developed models were evaluated using the collected dataset in terms of example-based and label-based metrics. The results indicate the high applicability and preference of the CNN and GRU models in comparison to LSTM and Bi-LSTM.
UoT-UWF-PartAI at SemEval-2021 Task 5: Self Attention Based Bi-GRU with Multi-Embedding Representation for Toxicity Highlighter
Apr 27, 2021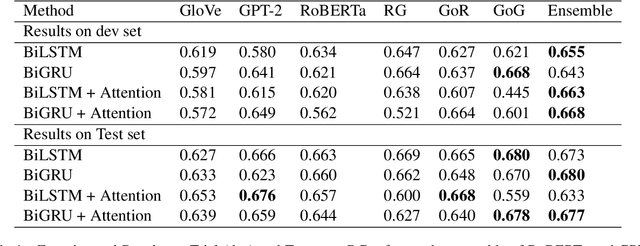
Toxic Spans Detection(TSD) task is defined as highlighting spans that make a text toxic. Many works have been done to classify a given comment or document as toxic or non-toxic. However, none of those proposed models work at the token level. In this paper, we propose a self-attention-based bidirectional gated recurrent unit(BiGRU) with a multi-embedding representation of the tokens. Our proposed model enriches the representation by a combination of GPT-2, GloVe, and RoBERTa embeddings, which led to promising results. Experimental results show that our proposed approach is very effective in detecting span tokens.