 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Driving Scenario Trajectories with Active Learning
Aug 06, 2021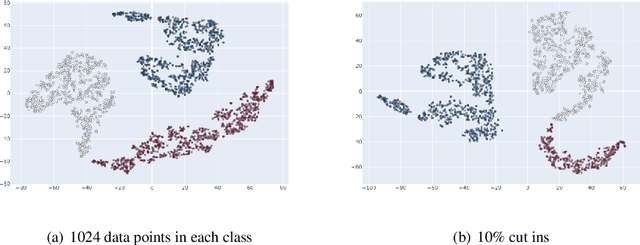
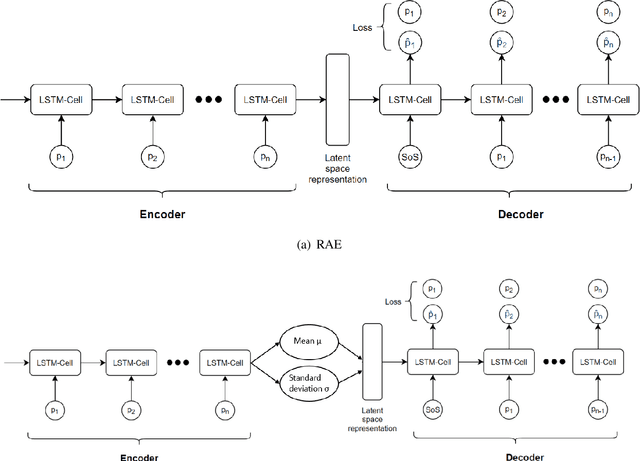
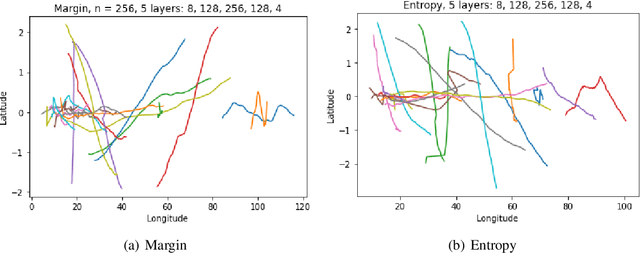
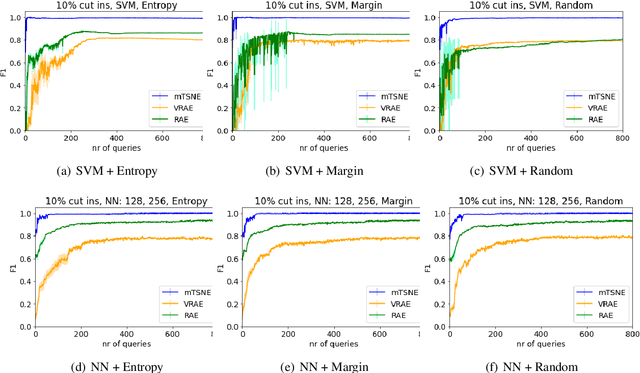
Annotating the driving scenario trajectories based only on explicit rules (i.e., knowledge-based methods) can be subject to errors, such as false positive/negative classification of scenarios that lie on the border of two scenario classes, missing unknown scenario classes, and also anomalies. On the other side, verifying the labels by the annotators is not cost-efficient. For this purpose, active learning (AL) could potentially improve the annotation procedure by inclusion of an annotator/expert in an efficient way. In this study, we develop an active learning framework to annotate driving trajectory time-series data. At the first step, we compute an embedding of the time-series trajectories into a latent space in order to extract the temporal nature. For this purpose, we study three different latent space representations: multivariate Time Series t-Distributed Stochastic Neighbor Embedding (mTSNE), Recurrent Auto-Encoder (RAE) and Variational Recurrent Auto-Encoder (VRAE). We then apply different active learning paradigms with different classification models to the embedded data. In particular, we study the two classifiers Neural Network (NN) and Support Vector Machines (SVM), with three active learning query strategies (i.e., entropy, margin and random). In the following, we explore the possibilities of the framework to discover unknown classes and demonstrate how it can be used to identify the out-of-class trajectories.
Constrained Policy Gradient Method for Safe and Fast Reinforcement Learning: a Neural Tangent Kernel Based Approach
Jul 19, 2021
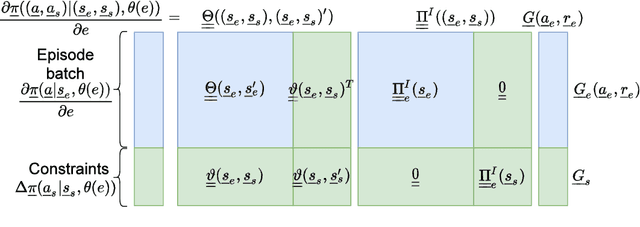

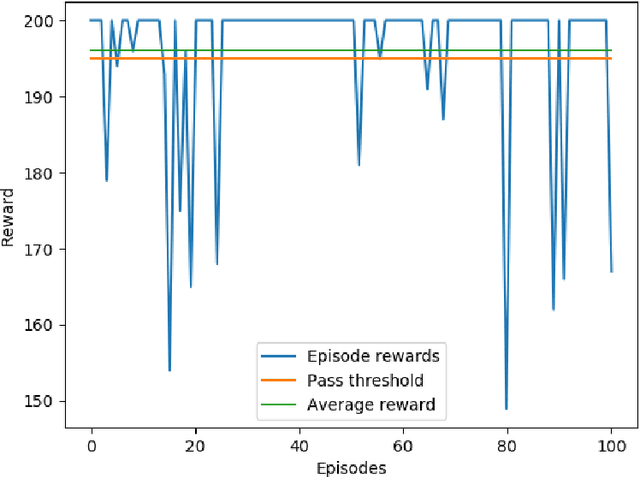
This paper presents a constrained policy gradient algorithm. We introduce constraints for safe learning with the following steps. First, learning is slowed down (lazy learning) so that the episodic policy change can be computed with the help of the policy gradient theorem and the neural tangent kernel. Then, this enables us the evaluation of the policy at arbitrary states too. In the same spirit, learning can be guided, ensuring safety via augmenting episode batches with states where the desired action probabilities are prescribed. Finally, exogenous discounted sum of future rewards (returns) can be computed at these specific state-action pairs such that the policy network satisfies constraints. Computing the returns is based on solving a system of linear equations (equality constraints) or a constrained quadratic program (inequality constraints). Simulation results suggest that adding constraints (external information) to the learning can improve learning in terms of speed and safety reasonably if constraints are appropriately selected. The efficiency of the constrained learning was demonstrated with a shallow and wide ReLU network in the Cartpole and Lunar Lander OpenAI gym environments. The main novelty of the paper is giving a practical use of the neural tangent kernel in reinforcement learning.
A Unified Framework for Online Trip Destination Prediction
Jan 12, 2021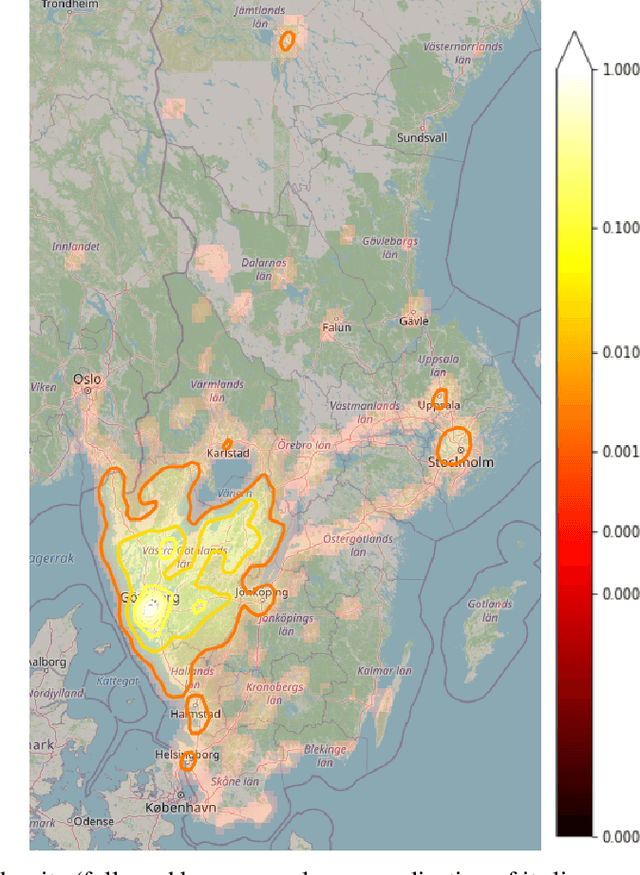
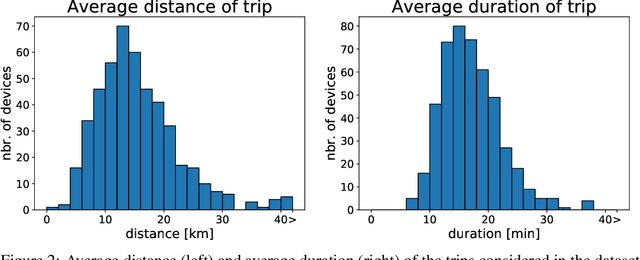
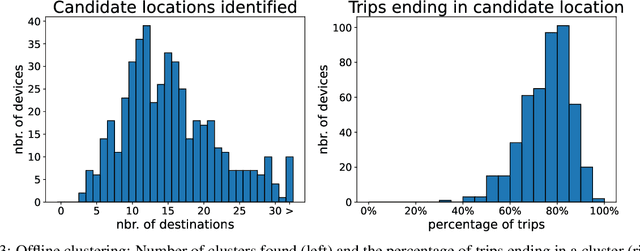
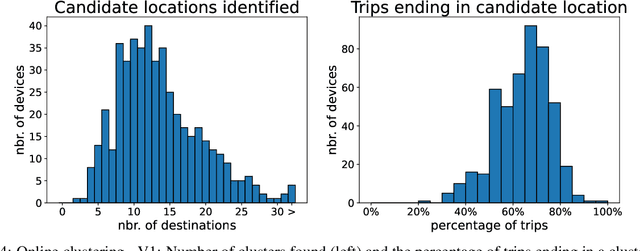
Trip destination prediction is an area of increasing importance in many applications such as trip planning, autonomous driving and electric vehicles. Even though this problem could be naturally addressed in an online learning paradigm where data is arriving in a sequential fashion, the majority of research has rather considered the offline setting. In this paper, we present a unified framework for trip destination prediction in an online setting, which is suitable for both online training and online prediction. For this purpose, we develop two clustering algorithms and integrate them within two online prediction models for this problem. We investigate the different configurations of clustering algorithms and prediction models on a real-world dataset. By using traditional clustering metrics and accuracy, we demonstrate that both the clustering and the entire framework yield consistent results compared to the offline setting. Finally, we propose a novel regret metric for evaluating the entire online framework in comparison to its offline counterpart. This metric makes it possible to relate the source of erroneous predictions to either the clustering or the prediction model. Using this metric, we show that the proposed methods converge to a probability distribution resembling the true underlying distribution and enjoy a lower regret than all of the baselines.
Model-Centric and Data-Centric Aspects of Active Learning for Neural Network Models
Oct 08, 2020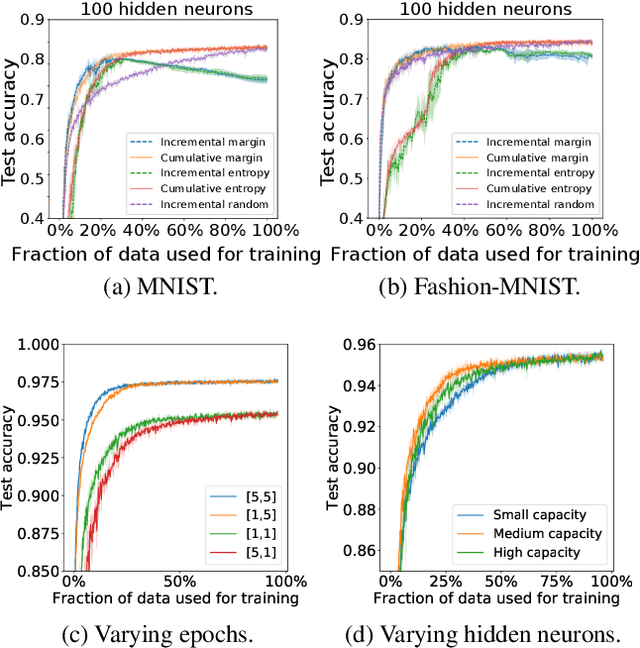
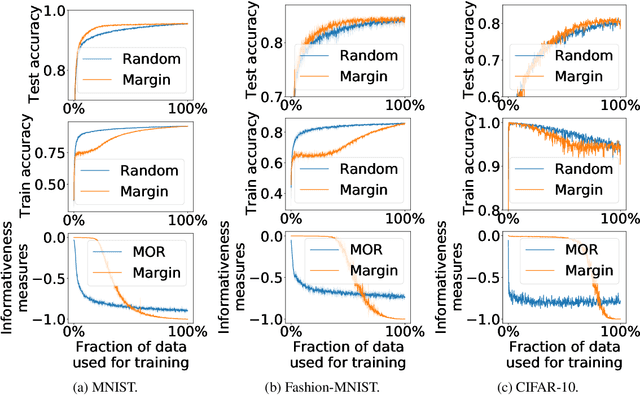
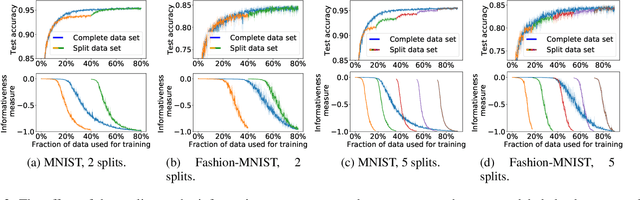
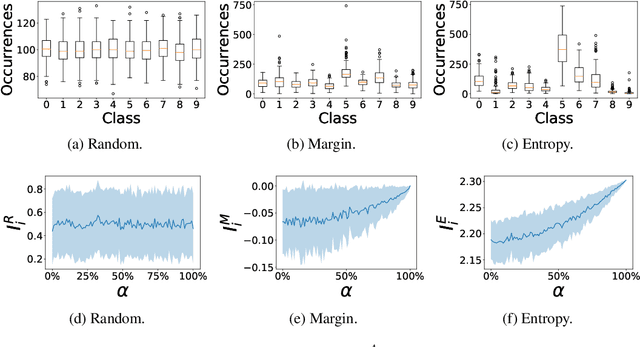
We study different data-centric and model-centric aspects of active learning with neural network models. i) We investigate incremental and cumulative training modes that specify how the currently labeled data are used for training. ii) Neural networks are models with a large capacity. Thus, we study how active learning depends on the number of epochs and neurons as well as the choice of batch size. iii) We analyze in detail the behavior of query strategies and their corresponding informativeness measures and accordingly propose more efficient querying and active learning paradigms. iv) We perform statistical analyses, e.g., on actively learned classes and test error estimation, that reveal several insights about active learning.
A Generic Framework for Clustering Vehicle Motion Trajectories
Sep 25, 2020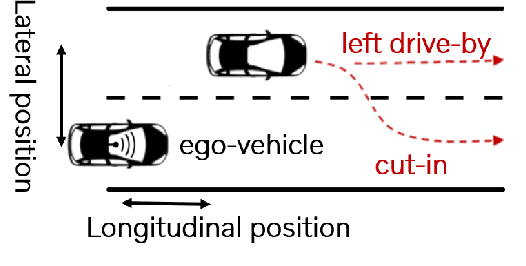
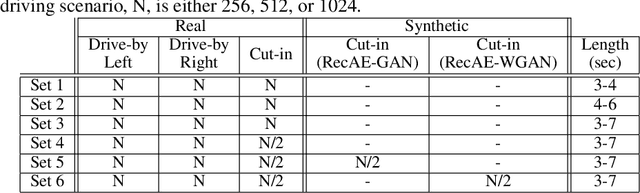
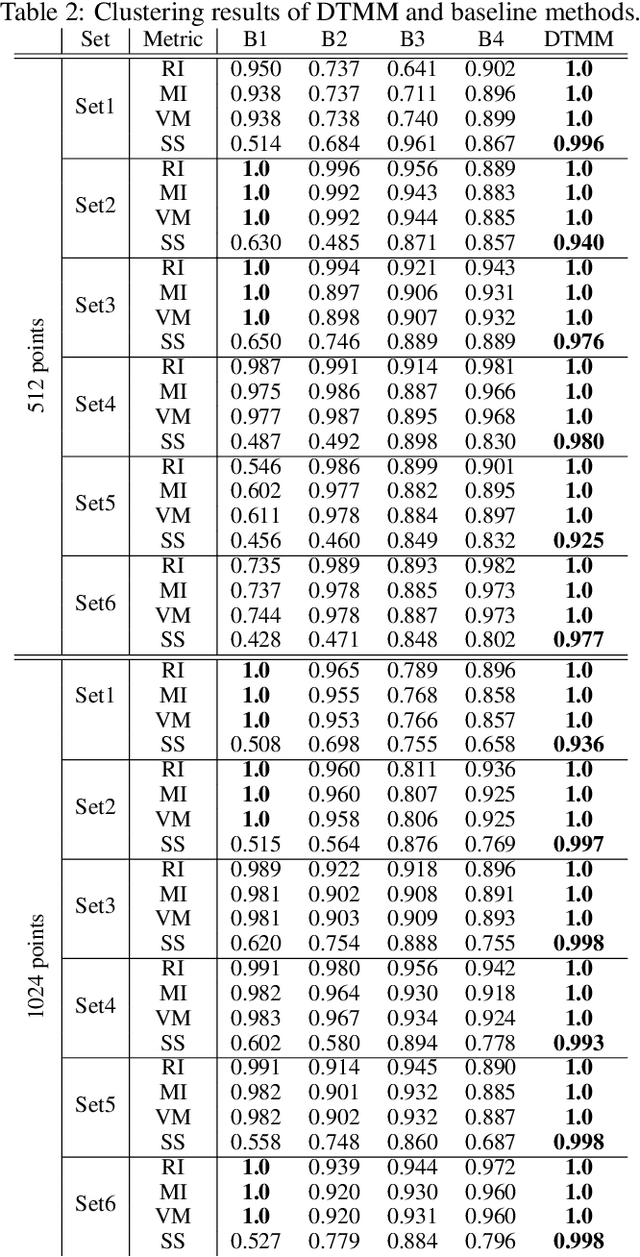
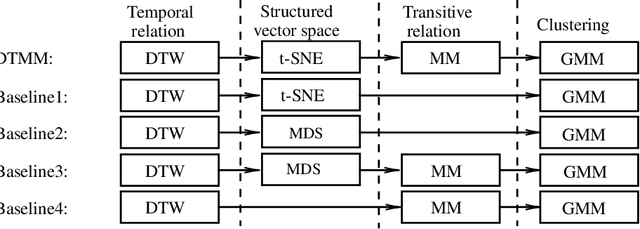
The development of autonomous vehicles requires having access to a large amount of data in the concerning driving scenarios. However, manual annotation of such driving scenarios is costly and subject to the errors in the rule-based trajectory labeling systems. To address this issue, we propose an effective non-parametric trajectory clustering framework consisting of five stages: (1) aligning trajectories and quantifying their pairwise temporal dissimilarities, (2) embedding the trajectory-based dissimilarities into a vector space, (3) extracting transitive relations, (4) embedding the transitive relations into a new vector space, and (5) clustering the trajectories with an optimal number of clusters. We investigate and evaluate the proposed framework on a challenging real-world dataset consisting of annotated trajectories. We observe that the proposed framework achieves promising results, despite the complexity caused by having trajectories of varying length. Furthermore, we extend the framework to validate the augmentation of the real dataset with synthetic data generated by a Generative Adversarial Network (GAN) where we examine whether the generated trajectories are consistent with the true underlying clusters.
Efficient Optimization of Dominant Set Clustering with Frank-Wolfe Algorithms
Aug 05, 2020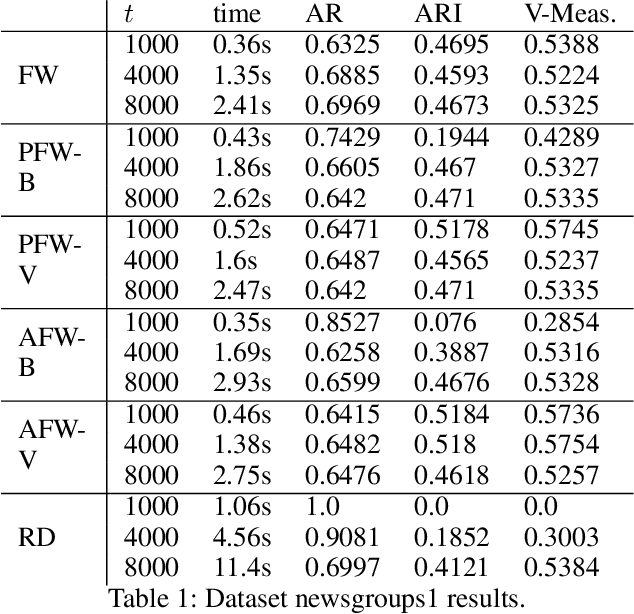
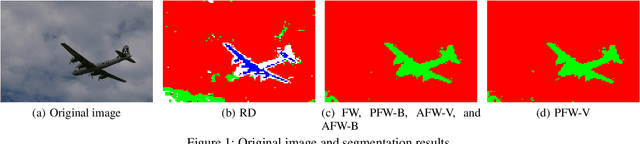
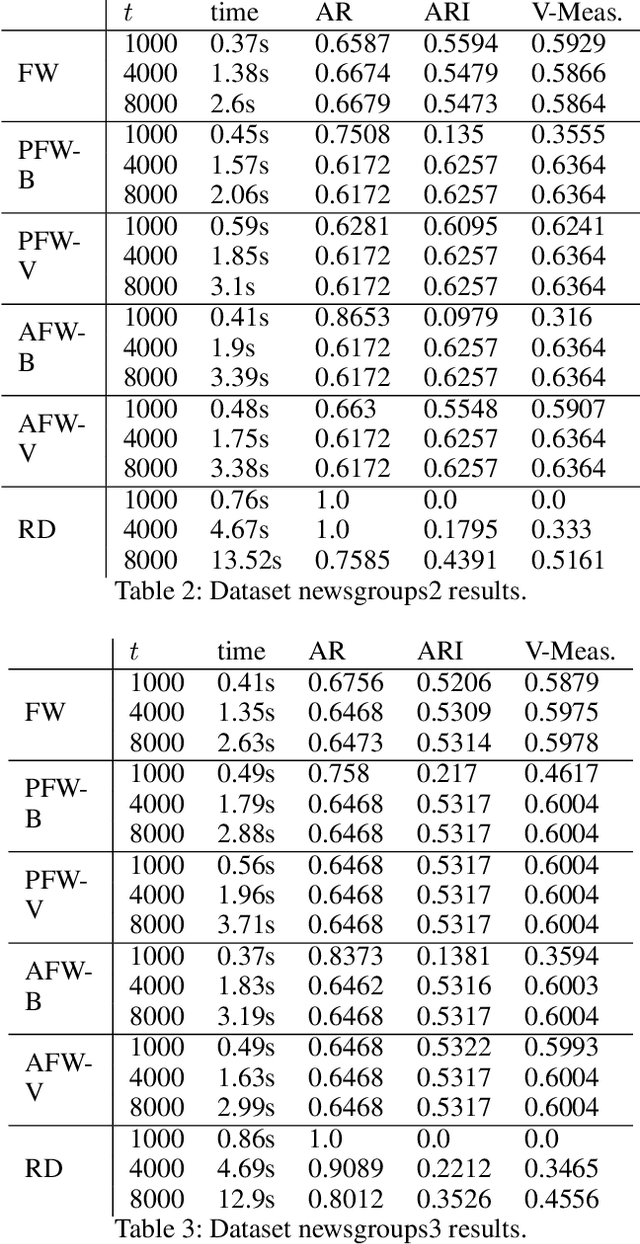
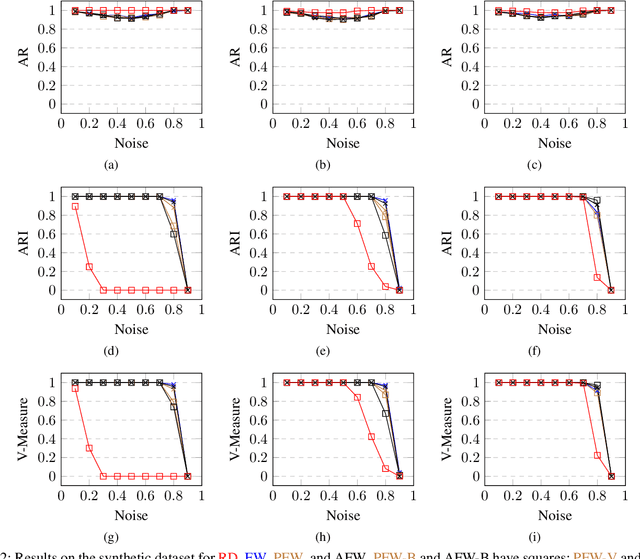
We study Frank-Wolfe algorithms -- standard, pairwise, and away-steps -- for efficient optimization of Dominant Set Clustering. We present a unified and computationally efficient framework to employ the different variants of Frank-Wolfe methods, and we investigate its effectiveness via several experimental studies. In addition, we provide explicit convergence rates for the algorithms in terms of the so-called Frank-Wolfe gap. The theoretical analysis has been specialized to the problem of Dominant Set Clustering and is thus more easily accessible compared to prior work.
A Deep Learning Framework for Generation and Analysis of Driving Scenario Trajectories
Jul 28, 2020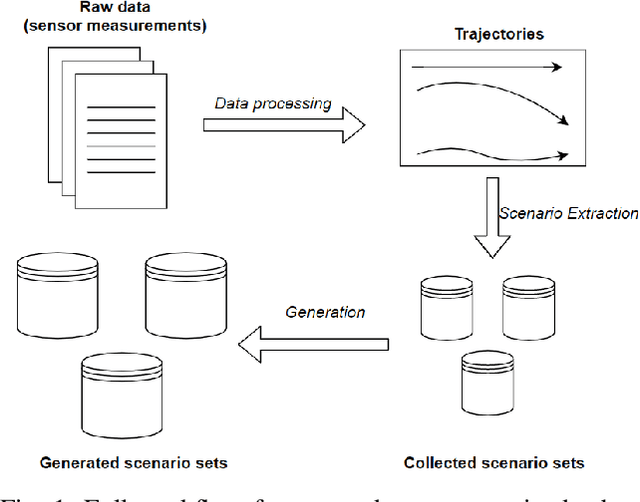
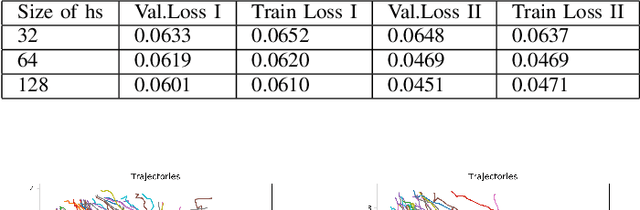
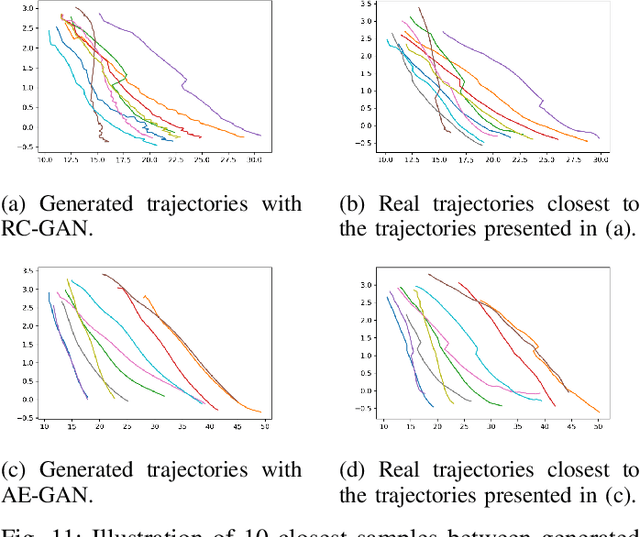
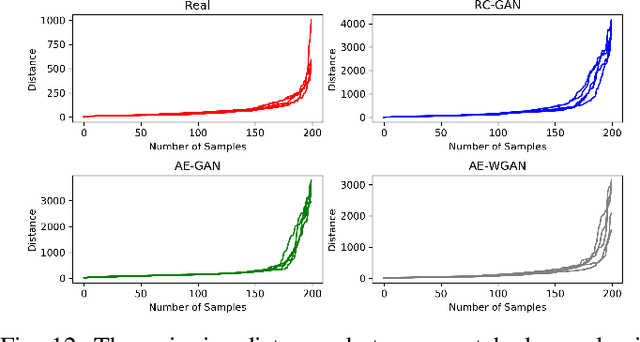
We propose a unified deep learning framework for generation and analysis of driving scenario trajectories, and validate its effectiveness in a principled way. In order to model and generate scenarios of trajectories with different length, we develop two approaches. First, we adapt the Recurrent Conditional Generative Adversarial Networks (RC-GAN) by conditioning on the length of the trajectories. This provides us flexibility to generate variable-length driving trajectories, a desirable feature for scenario test case generation in the verification of self-driving cars. Second, we develop an architecture based on Recurrent Autoencoder with GANs in order to obviate the variable length issue, wherein we train a GAN to learn/generate the latent representations of original trajectories. In this approach, we train an integrated feed-forward neural network to estimate the length of the trajectories to be able to bring them back from the latent space representation. In addition to trajectory generation, we employ the trained autoencoder as a feature extractor, for the purpose of clustering and anomaly detection, in order to obtain further insights on the collected scenario dataset. We experimentally investigate the performance of the proposed framework on real-world scenario trajectories obtained from in-field data collection.
Memory-Efficient Sampling for Minimax Distance Measures
May 26, 2020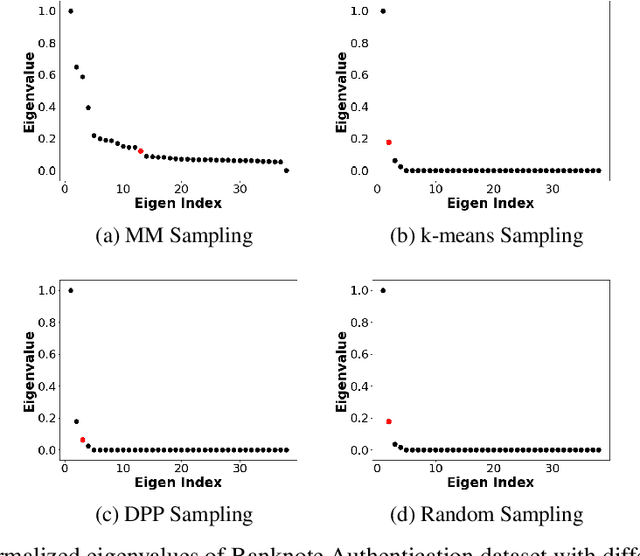
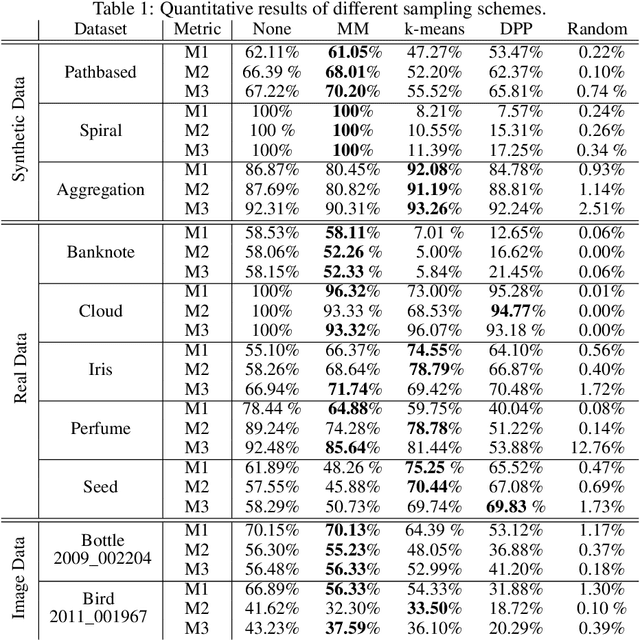
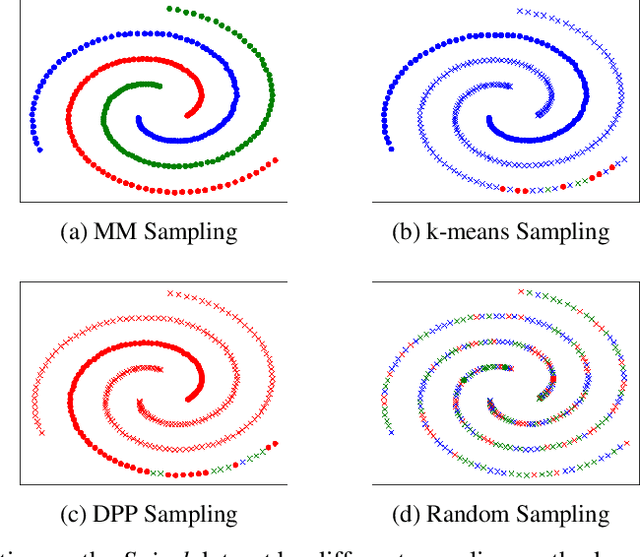
Minimax distance measure extracts the underlying patterns and manifolds in an unsupervised manner. The existing methods require a quadratic memory with respect to the number of objects. In this paper, we investigate efficient sampling schemes in order to reduce the memory requirement and provide a linear space complexity. In particular, we propose a novel sampling technique that adapts well with Minimax distances. We evaluate the methods on real-world datasets from different domains and analyze the results.
On the Unreasonable Effectiveness of Knowledge Distillation: Analysis in the Kernel Regime
Mar 30, 2020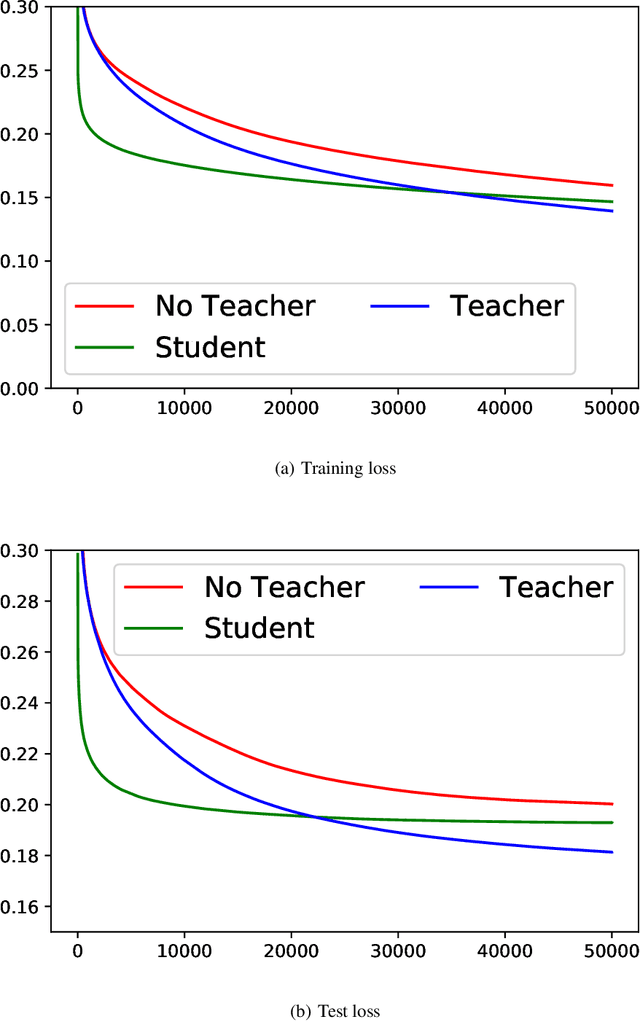
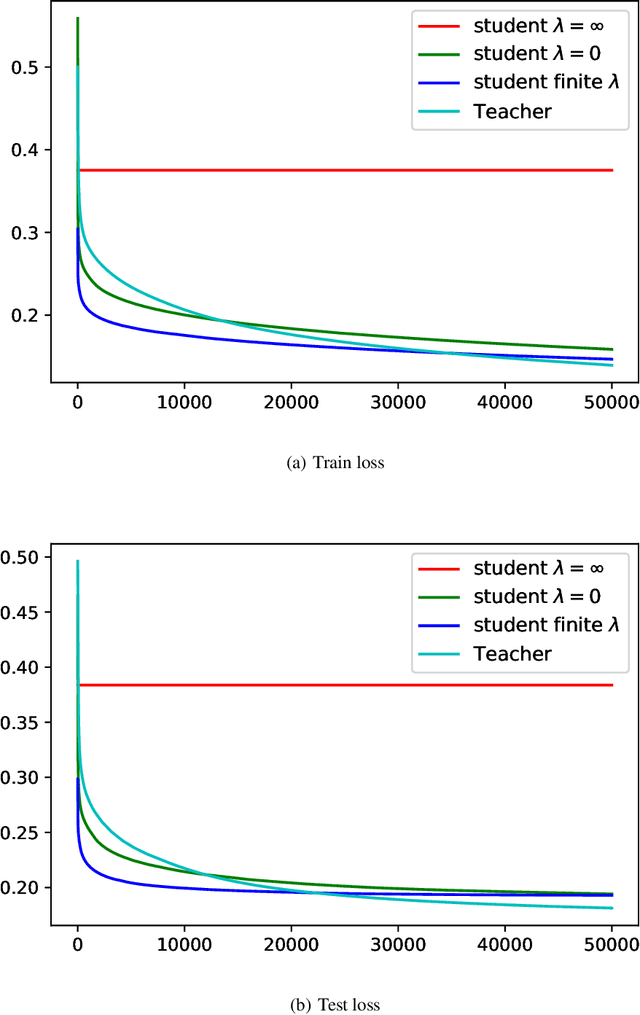
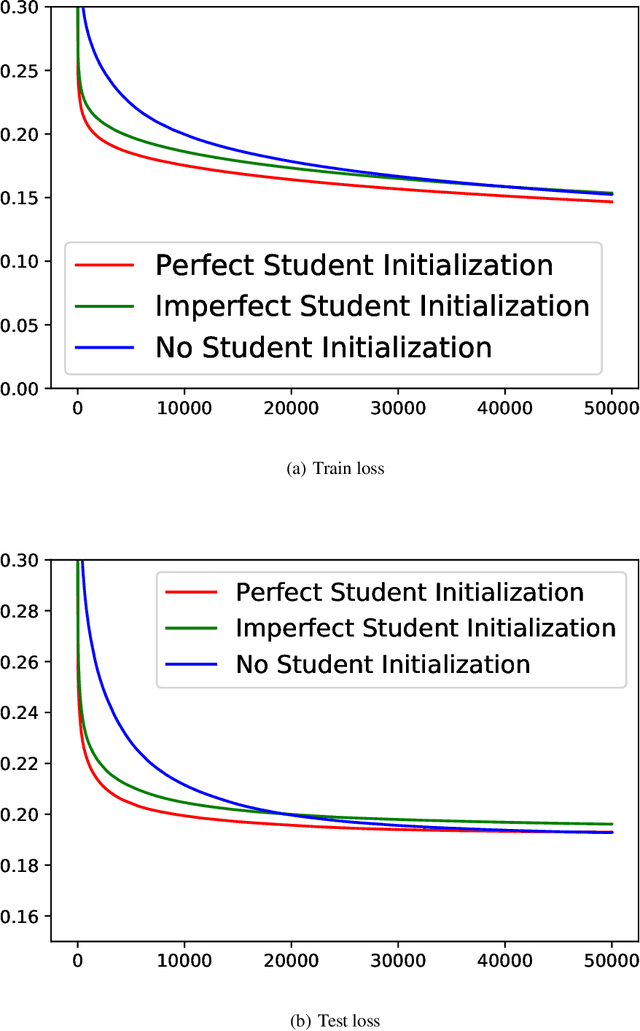
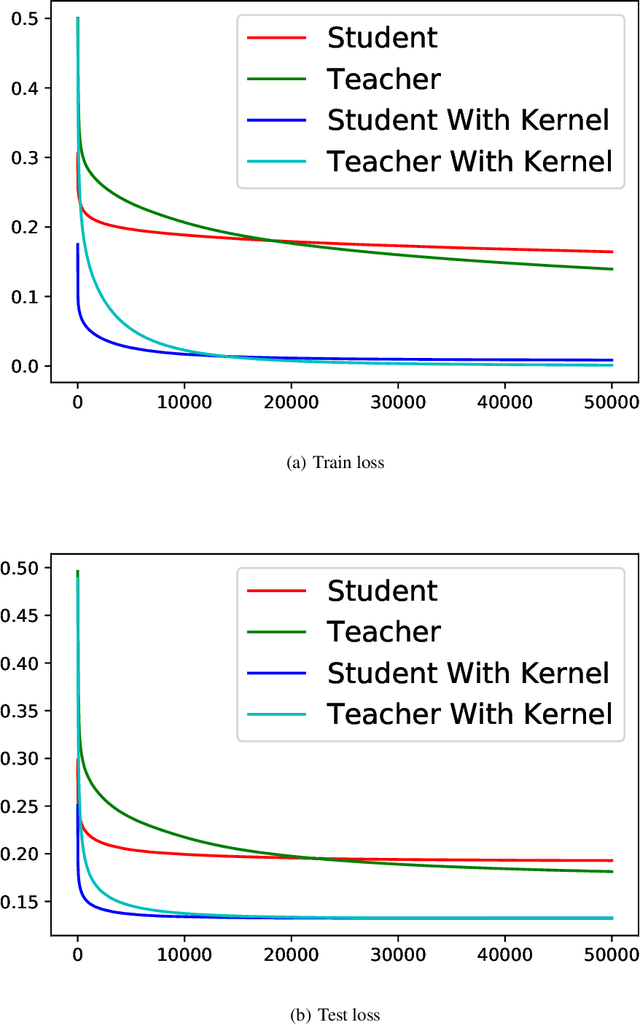
Knowledge distillation (KD), i.e. one classifier being trained on the outputs of another classifier, is an empirically very successful technique for knowledge transfer between classifiers. It has even been observed that classifiers learn much faster and more reliably if trained with the outputs of another classifier as soft labels, instead of from ground truth data. However, there has been little or no theoretical analysis of this phenomenon. We provide the first theoretical analysis of KD in the setting of extremely wide two layer non-linear networks in model and regime in (Arora et al., 2019; Du & Hu, 2019; Cao & Gu, 2019). We prove results on what the student network learns and on the rate of convergence for the student network. Intriguingly, we also confirm the lottery ticket hypothesis (Frankle & Carbin, 2019) in this model. To prove our results, we extend the repertoire of techniques from linear systems dynamics. We give corresponding experimental analysis that validates the theoretical results and yields additional insights.
Convolutional Spiking Neural Networks for Spatio-Temporal Feature Extraction
Mar 27, 2020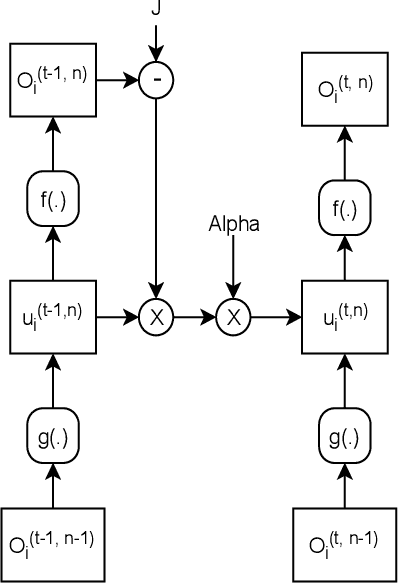
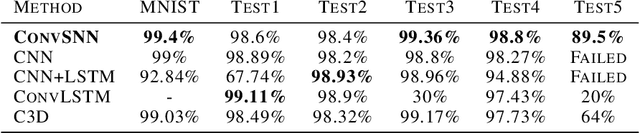


Spiking neural networks (SNNs) can be used in low-power and embedded systems (such as emerging neuromorphic chips) due to their event-based nature. Also, they have the advantage of low computation cost in contrast to conventional artificial neural networks (ANNs), while preserving ANN's properties. However, temporal coding in layers of convolutional spiking neural networks and other types of SNNs has yet to be studied. In this paper, we provide insight into spatio-temporal feature extraction of convolutional SNNs in experiments designed to exploit this property. Our proposed shallow convolutional SNN outperforms state-of-the-art spatio-temporal feature extractor methods such as C3D, ConvLstm, and similar networks. Furthermore, we present a new deep spiking architecture to tackle real-world problems (in particular classification tasks), and the model achieved superior performance compared to other SNN methods on CIFAR10-DVS. It is also worth noting that the training process is implemented based on spatio-temporal backpropagation, and ANN to SNN conversion methods will serve no use.