 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Combinatorial Semi-Bandit Approach to Charging Station Selection for Electric Vehicles
Jan 17, 2023



In this work, we address the problem of long-distance navigation for battery electric vehicles (BEVs), where one or more charging sessions are required to reach the intended destination. We consider the availability and performance of the charging stations to be unknown and stochastic, and develop a combinatorial semi-bandit framework for exploring the road network to learn the parameters of the queue time and charging power distributions. Within this framework, we first outline a pre-processing for the road network graph to handle the constrained combinatorial optimization problem in an efficient way. Then, for the pre-processed graph, we use a Bayesian approach to model the stochastic edge weights, utilizing conjugate priors for the one-parameter exponential and two-parameter gamma distributions, the latter of which is novel to multi-armed bandit literature. Finally, we apply combinatorial versions of Thompson Sampling, BayesUCB and Epsilon-greedy to the problem. We demonstrate the performance of our framework on long-distance navigation problem instances in country-sized road networks, with simulation experiments in Norway, Sweden and Finland.
An Online Learning Approach for Vehicle Usage Prediction During COVID-19
Oct 28, 2022



Today, there is an ongoing transition to more sustainable transportation, and an essential part of this transition is the switch from combustion engine vehicles to battery electric vehicles (BEVs). BEVs have many advantages from a sustainability perspective, but issues such as limited driving range and long recharge times slow down the transition from combustion engines. One way to mitigate these issues is by performing battery thermal preconditioning, which increases the energy efficiency of the battery. However, to optimally perform battery thermal preconditioning, the vehicle usage pattern needs to be known, i.e., how and when the vehicle will be used. This study attempts to predict the departure time and distance of the first drive each day using different online machine learning models. The online machine learning models are trained and evaluated on historical driving data collected from a fleet of BEVs during the COVID-19 pandemic. Additionally, the prediction models are extended to quantify the uncertainty of their predictions, which can be used as guidance to whether the prediction should be used or dismissed. We show that the best-performing prediction models yield an aggregated mean absolute error of 2.75 hours when predicting departure time and 13.37 km when predicting trip distance.
TEP-GNN: Accurate Execution Time Prediction of Functional Tests using Graph Neural Networks
Aug 25, 2022
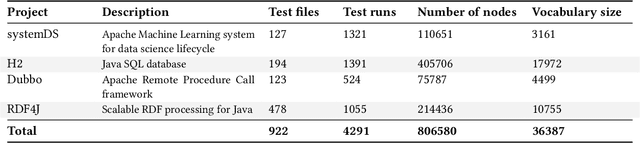
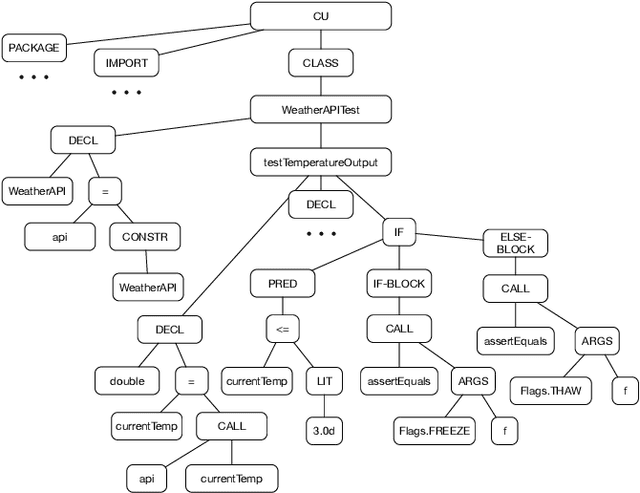
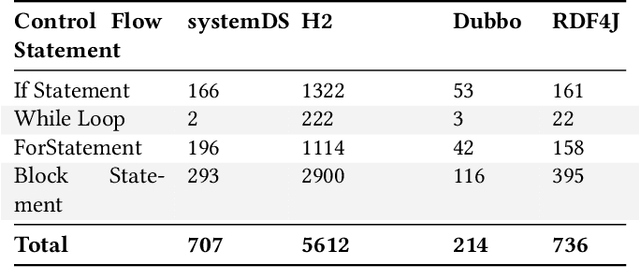
Predicting the performance of production code prior to actually executing or benchmarking it is known to be highly challenging. In this paper, we propose a predictive model, dubbed TEP-GNN, which demonstrates that high-accuracy performance prediction is possible for the special case of predicting unit test execution times. TEP-GNN uses FA-ASTs, or flow-augmented ASTs, as a graph-based code representation approach, and predicts test execution times using a powerful graph neural network (GNN) deep learning model. We evaluate TEP-GNN using four real-life Java open source programs, based on 922 test files mined from the projects' public repositories. We find that our approach achieves a high Pearson correlation of 0.789, considerable outperforming a baseline deep learning model. However, we also find that more work is needed for trained models to generalize to unseen projects. Our work demonstrates that FA-ASTs and GNNs are a feasible approach for predicting absolute performance values, and serves as an important intermediary step towards being able to predict the performance of arbitrary code prior to execution.
Autonomous Drug Design with Multi-armed Bandits
Jul 04, 2022
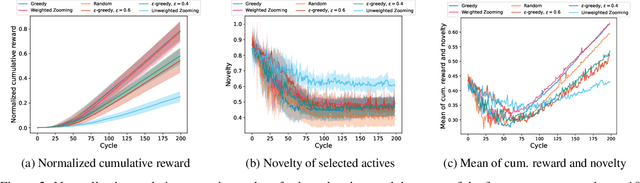
Recent developments in artificial intelligence and automation could potentially enable a new drug design paradigm: autonomous drug design. Under this paradigm, generative models provide suggestions on thousands of molecules with specific properties. However, since only a limited number of molecules can be synthesized and tested, an obvious challenge is how to efficiently select these. We formulate this task as a contextual stochastic multi-armed bandit problem with multiple plays and volatile arms. Then, to solve it, we extend previous work on multi-armed bandits to reflect this setting, and compare our solution with random sampling, greedy selection and decaying-epsilon-greedy selection. To investigate how the different selection strategies affect the cumulative reward and the diversity of the selections, we simulate the drug design process. According to the simulation results, our approach has the potential for better exploring and exploiting the chemical space for autonomous drug design.
A Contextual Combinatorial Semi-Bandit Approach to Network Bottleneck Identification
Jun 16, 2022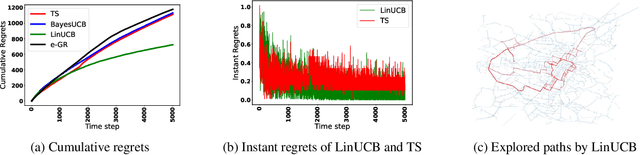
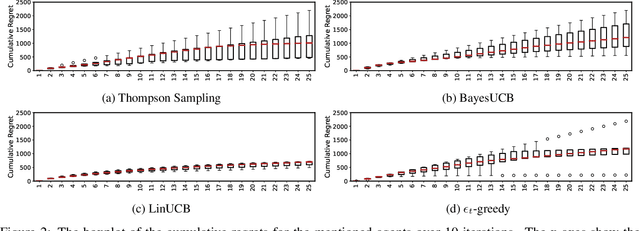
Bottleneck identification is a challenging task in network analysis, especially when the network is not fully specified. To address this task, we develop a unified online learning framework based on combinatorial semi-bandits that performs bottleneck identification alongside learning the specifications of the underlying network. Within this framework, we adapt and investigate several combinatorial semi-bandit methods such as epsilon-greedy, LinUCB, BayesUCB, and Thompson Sampling. Our framework is able to employ contextual information in the form of contextual bandits. We evaluate our framework on the real-world application of road networks and demonstrate its effectiveness in different settings.
Passive and Active Learning of Driver Behavior from Electric Vehicles
Mar 04, 2022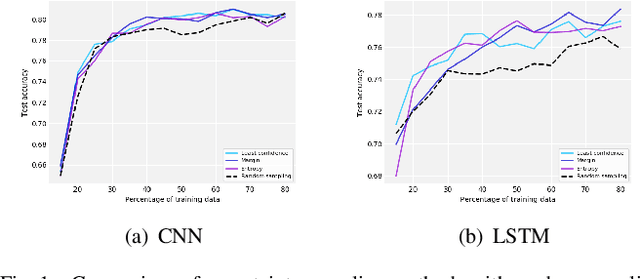
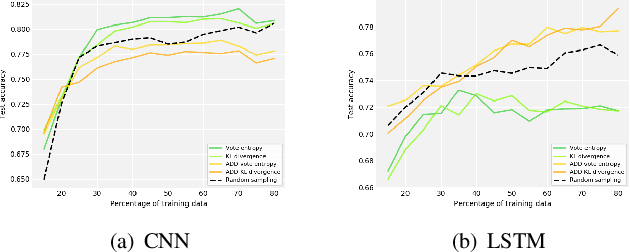
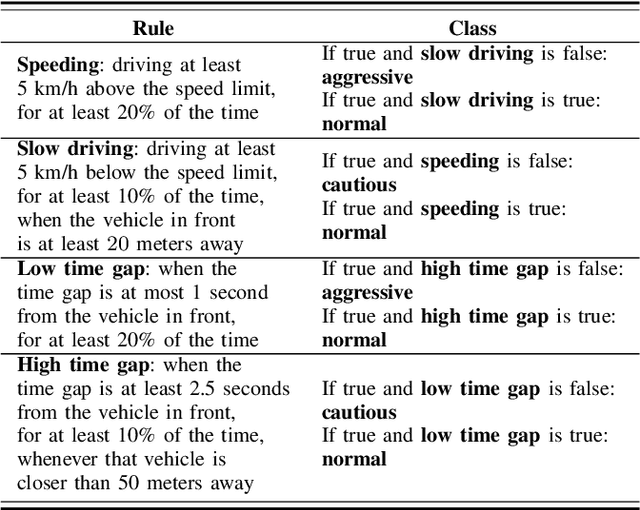
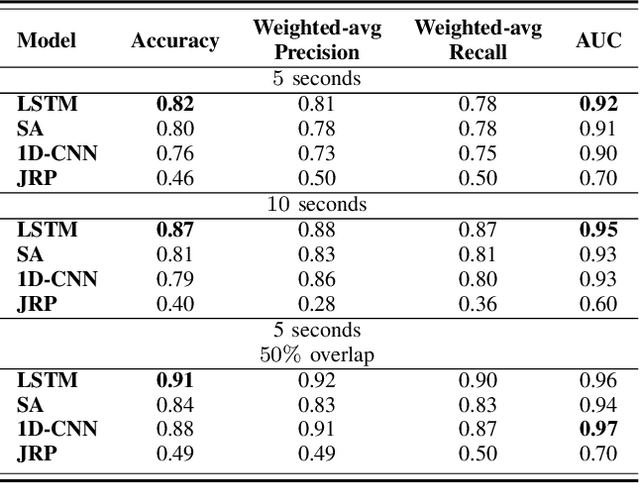
Modeling driver behavior provides several advantages in the automotive industry, including prediction of electric vehicle energy consumption. Studies have shown that aggressive driving can consume up to 30% more energy than moderate driving, in certain driving scenarios. Machine learning methods are widely used for driver behavior classification, which, however, may yield some challenges such as sequence modeling on long time windows and lack of labeled data due to expensive annotation. To address the first challenge, passive learning of driver behavior, we investigate non-recurrent architectures such as self-attention models and convolutional neural networks with joint recurrence plots (JRP), and compare them with recurrent models. We find that self-attention models yield good performance, while JRP does not exhibit any significant improvement. However, with the window lengths of 5 and 10 seconds used in our study, none of the non-recurrent models outperform the recurrent models. To address the second challenge, we investigate several active learning methods with different informativeness measures. We evaluate uncertainty sampling, as well as more advanced methods, such as query by committee and active deep dropout. Our experiments demonstrate that some active sampling techniques can outperform random sampling, and therefore decrease the effort needed for annotation.
Deep Q-learning: a robust control approach
Jan 21, 2022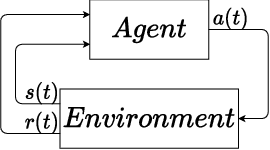

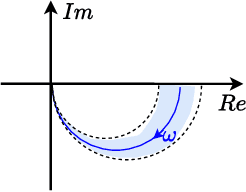
In this paper, we place deep Q-learning into a control-oriented perspective and study its learning dynamics with well-established techniques from robust control. We formulate an uncertain linear time-invariant model by means of the neural tangent kernel to describe learning. We show the instability of learning and analyze the agent's behavior in frequency-domain. Then, we ensure convergence via robust controllers acting as dynamical rewards in the loss function. We synthesize three controllers: state-feedback gain scheduling $\mathcal{H}_2$, dynamic $\mathcal{H}_\infty$, and constant gain $\mathcal{H}_\infty$ controllers. Setting up the learning agent with a control-oriented tuning methodology is more transparent and has well-established literature compared to the heuristics in reinforcement learning. In addition, our approach does not use a target network and randomized replay memory. The role of the target network is overtaken by the control input, which also exploits the temporal dependency of samples (opposed to a randomized memory buffer). Numerical simulations in different OpenAI Gym environments suggest that the $\mathcal{H}_\infty$ controlled learning performs slightly better than Double deep Q-learning.
Online Learning of Energy Consumption for Navigation of Electric Vehicles
Nov 03, 2021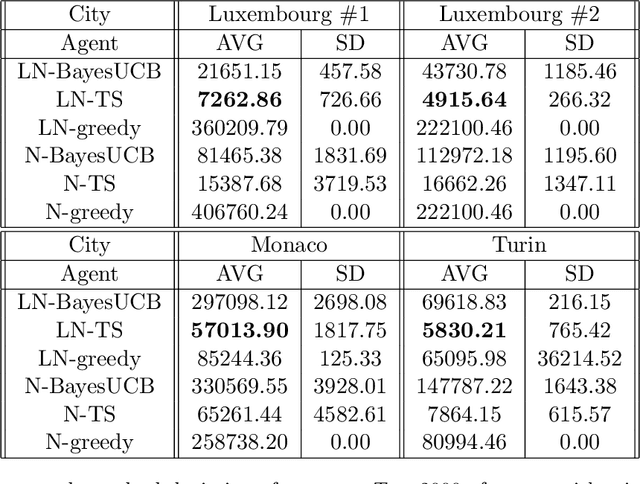
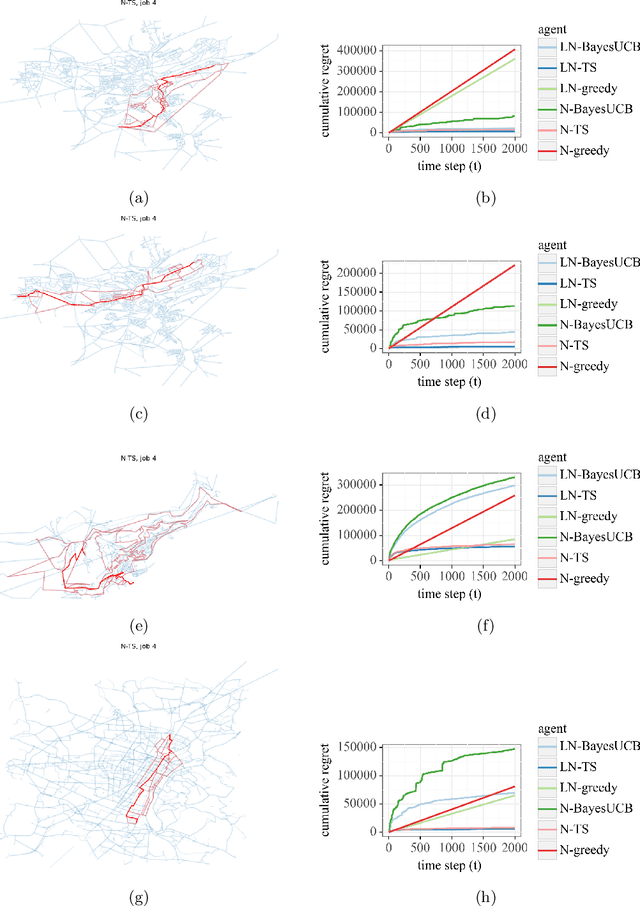
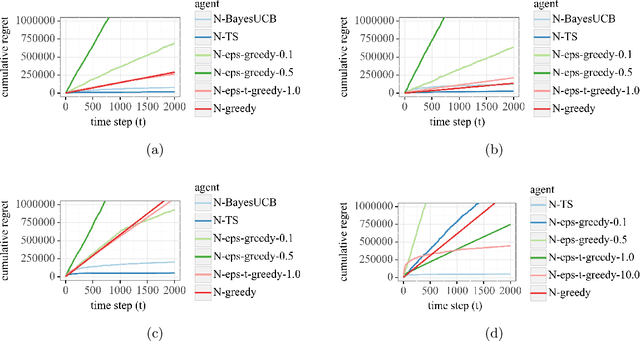
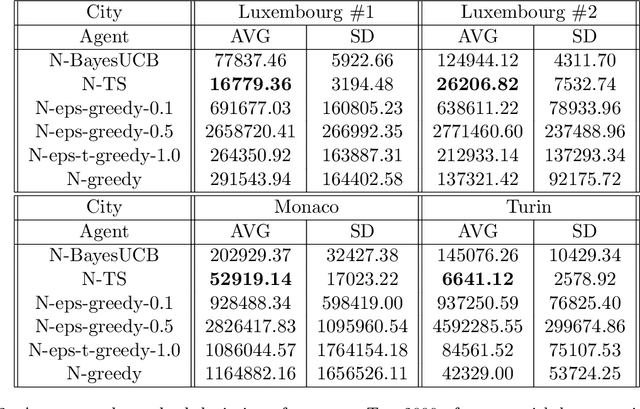
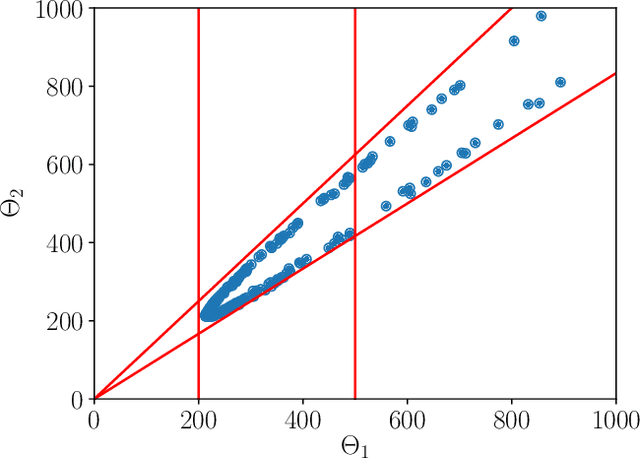
Energy-efficient navigation constitutes an important challenge in electric vehicles, due to their limited battery capacity. We employ a Bayesian approach to model the energy consumption at road segments for efficient navigation. In order to learn the model parameters, we develop an online learning framework and investigate several exploration strategies such as Thompson Sampling and Upper Confidence Bound. We then extend our online learning framework to multi-agent setting, where multiple vehicles adaptively navigate and learn the parameters of the energy model. We analyze Thompson Sampling and establish rigorous regret bounds on its performance in the single-agent and multi-agent settings, through an analysis of the algorithm under batched feedback. Finally, we demonstrate the performance of our methods via experiments on several real-world city road networks.
Shift of Pairwise Similarities for Data Clustering
Oct 25, 2021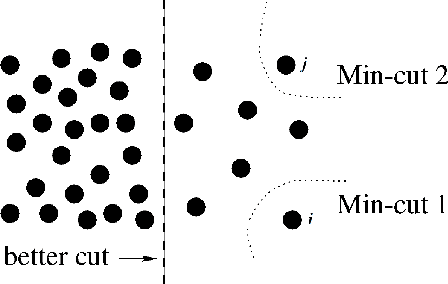
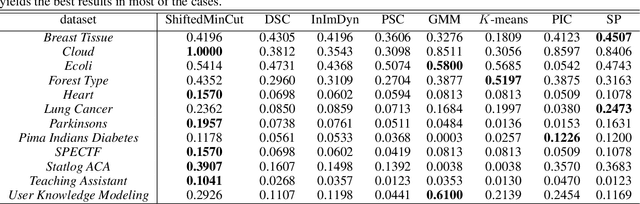

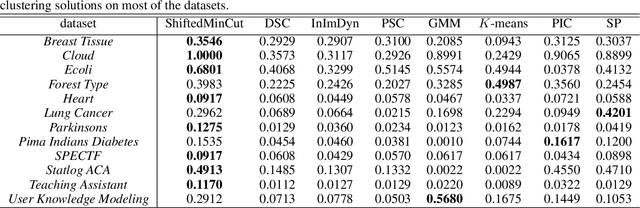
Several clustering methods (e.g., Normalized Cut and Ratio Cut) divide the Min Cut cost function by a cluster-dependent factor (e.g., the size or the degree of the clusters), in order to yield a more balanced partitioning. We, instead, investigate adding such regularizations to the original cost function. We first consider the case where the regularization term is the sum of the squared size of the clusters, and then generalize it to adaptive regularization of the pairwise similarities. This leads to shifting (adaptively) the pairwise similarities which might make some of them negative. We then study the connection of this method to Correlation Clustering and then propose an efficient local search optimization algorithm with fast theoretical convergence rate to solve the new clustering problem. In the following, we investigate the shift of pairwise similarities on some common clustering methods, and finally, we demonstrate the superior performance of the method by extensive experiments on different datasets.
Online Learning of Network Bottlenecks via Minimax Paths
Sep 17, 2021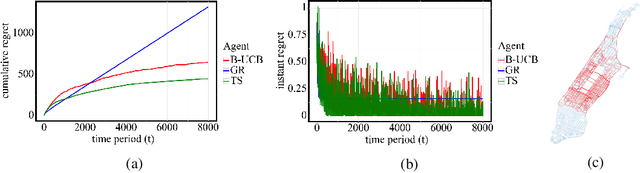
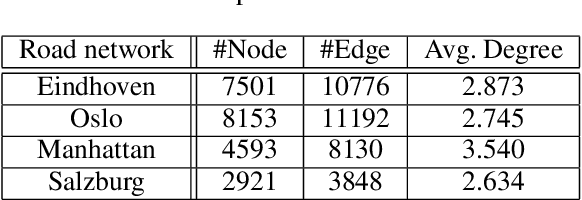
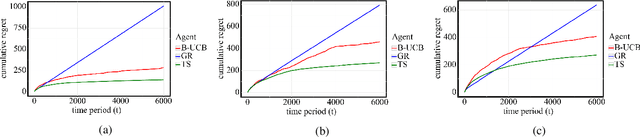
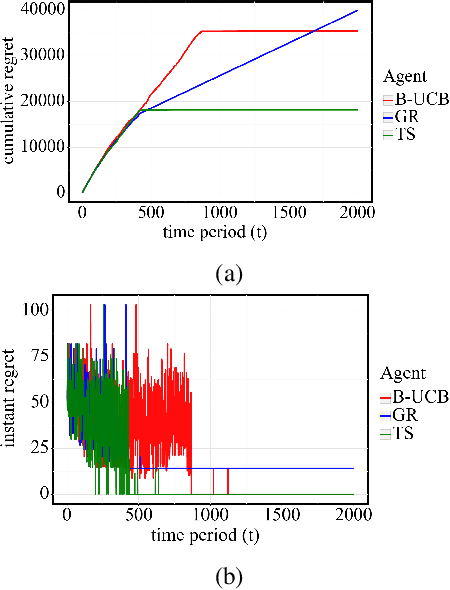
In this paper, we study bottleneck identification in networks via extracting minimax paths. Many real-world networks have stochastic weights for which full knowledge is not available in advance. Therefore, we model this task as a combinatorial semi-bandit problem to which we apply a combinatorial version of Thompson Sampling and establish an upper bound on the corresponding Bayesian regret. Due to the computational intractability of the problem, we then devise an alternative problem formulation which approximates the original objective. Finally, we experimentally evaluate the performance of Thompson Sampling with the approximate formulation on real-world directed and undirected networks.