 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Attention and Gaussian Processes for Personalized Video Gaze Estimation
Apr 10, 2024



Gaze is an essential prompt for analyzing human behavior and attention. Recently, there has been an increasing interest in determining gaze direction from facial videos. However, video gaze estimation faces significant challenges, such as understanding the dynamic evolution of gaze in video sequences, dealing with static backgrounds, and adapting to variations in illumination. To address these challenges, we propose a simple and novel deep learning model designed to estimate gaze from videos, incorporating a specialized attention module. Our method employs a spatial attention mechanism that tracks spatial dynamics within videos. This technique enables accurate gaze direction prediction through a temporal sequence model, adeptly transforming spatial observations into temporal insights, thereby significantly improving gaze estimation accuracy. Additionally, our approach integrates Gaussian processes to include individual-specific traits, facilitating the personalization of our model with just a few labeled samples. Experimental results confirm the efficacy of the proposed approach, demonstrating its success in both within-dataset and cross-dataset settings. Specifically, our proposed approach achieves state-of-the-art performance on the Gaze360 dataset, improving by $2.5^\circ$ without personalization. Further, by personalizing the model with just three samples, we achieved an additional improvement of $0.8^\circ$. The code and pre-trained models are available at \url{https://github.com/jswati31/stage}.
Kernel Interpolation with Sparse Grids
May 23, 2023Structured kernel interpolation (SKI) accelerates Gaussian process (GP) inference by interpolating the kernel covariance function using a dense grid of inducing points, whose corresponding kernel matrix is highly structured and thus amenable to fast linear algebra. Unfortunately, SKI scales poorly in the dimension of the input points, since the dense grid size grows exponentially with the dimension. To mitigate this issue, we propose the use of sparse grids within the SKI framework. These grids enable accurate interpolation, but with a number of points growing more slowly with dimension. We contribute a novel nearly linear time matrix-vector multiplication algorithm for the sparse grid kernel matrix. Next, we describe how sparse grids can be combined with an efficient interpolation scheme based on simplices. With these changes, we demonstrate that SKI can be scaled to higher dimensions while maintaining accuracy.
Faster Kernel Interpolation for Gaussian Processes
Jan 28, 2021
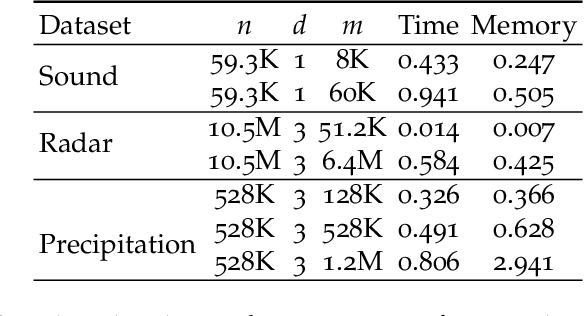

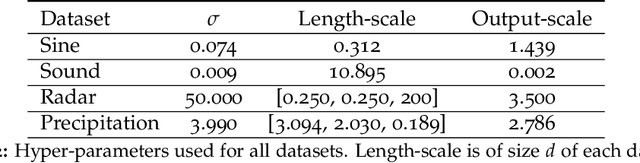
A key challenge in scaling Gaussian Process (GP) regression to massive datasets is that exact inference requires computation with a dense n x n kernel matrix, where n is the number of data points. Significant work focuses on approximating the kernel matrix via interpolation using a smaller set of m inducing points. Structured kernel interpolation (SKI) is among the most scalable methods: by placing inducing points on a dense grid and using structured matrix algebra, SKI achieves per-iteration time of O(n + m log m) for approximate inference. This linear scaling in n enables inference for very large data sets; however the cost is per-iteration, which remains a limitation for extremely large n. We show that the SKI per-iteration time can be reduced to O(m log m) after a single O(n) time precomputation step by reframing SKI as solving a natural Bayesian linear regression problem with a fixed set of m compact basis functions. With per-iteration complexity independent of the dataset size n for a fixed grid, our method scales to truly massive data sets. We demonstrate speedups in practice for a wide range of m and n and apply the method to GP inference on a three-dimensional weather radar dataset with over 100 million points.
Unsupervised Latent Tree Induction with Deep Inside-Outside Recursive Autoencoders
Apr 04, 2019
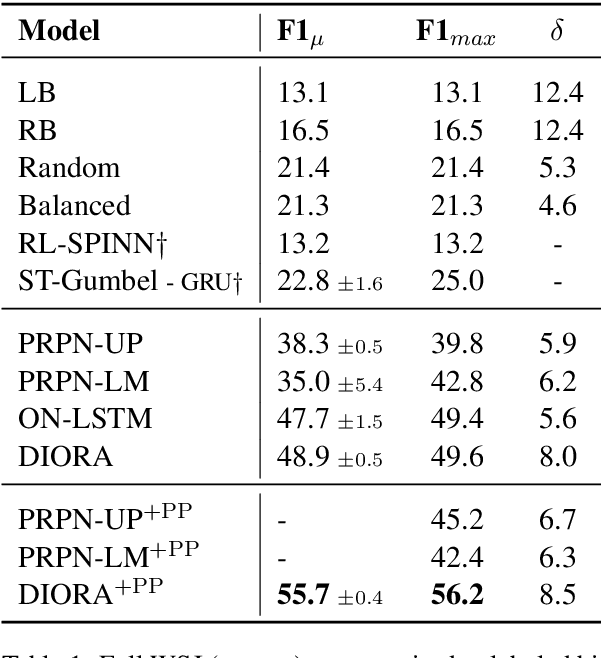
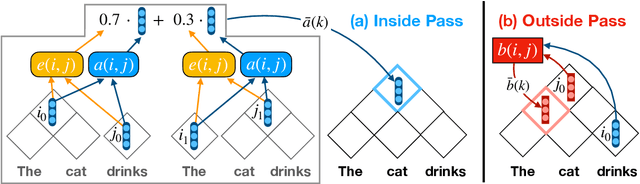
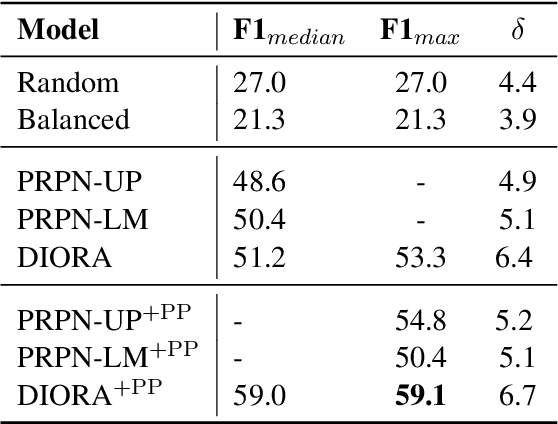
We introduce deep inside-outside recursive autoencoders (DIORA), a fully-unsupervised method for discovering syntax that simultaneously learns representations for constituents within the induced tree. Our approach predicts each word in an input sentence conditioned on the rest of the sentence and uses inside-outside dynamic programming to consider all possible binary trees over the sentence. At test time the CKY algorithm extracts the highest scoring parse. DIORA achieves a new state-of-the-art F1 in unsupervised binary constituency parsing (unlabeled) in two benchmark datasets, WSJ and MultiNLI.
Deep Triphone Embedding Improves Phoneme Recognition
Oct 24, 2017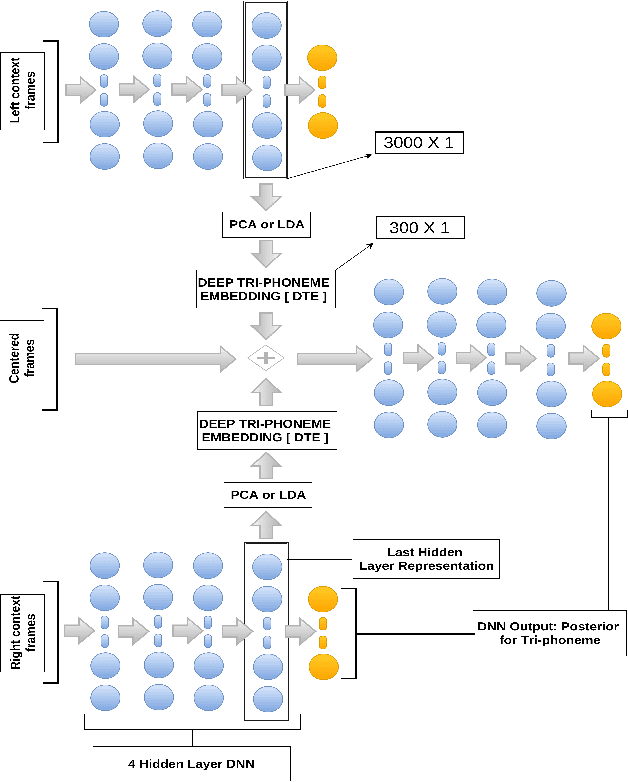
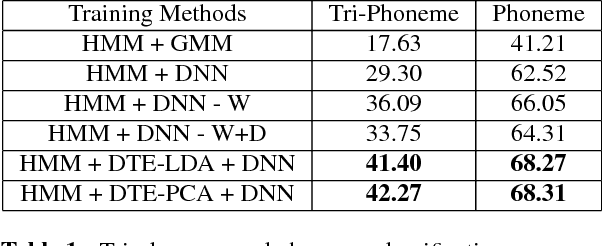
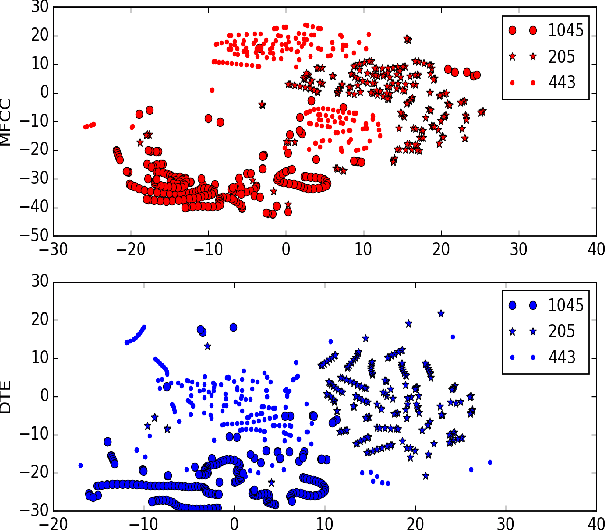
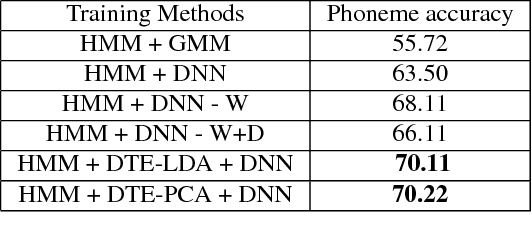
In this paper, we present a novel Deep Triphone Embedding (DTE) representation derived from Deep Neural Network (DNN) to encapsulate the discriminative information present in the adjoining speech frames. DTEs are generated using a four hidden layer DNN with 3000 nodes in each hidden layer at the first-stage. This DNN is trained with the tied-triphone classification accuracy as an optimization criterion. Thereafter, we retain the activation vectors (3000) of the last hidden layer, for each speech MFCC frame, and perform dimension reduction to further obtain a 300 dimensional representation, which we termed as DTE. DTEs along with MFCC features are fed into a second-stage four hidden layer DNN, which is subsequently trained for the task of tied-triphone classification. Both DNNs are trained using tri-phone labels generated from a tied-state triphone HMM-GMM system, by performing a forced-alignment between the transcriptions and MFCC feature frames. We conduct the experiments on publicly available TED-LIUM speech corpus. The results show that the proposed DTE method provides an improvement of absolute 2.11% in phoneme recognition, when compared with a competitive hybrid tied-state triphone HMM-DNN system.
ODE - Augmented Training Improves Anomaly Detection in Sensor Data from Machines
May 05, 2016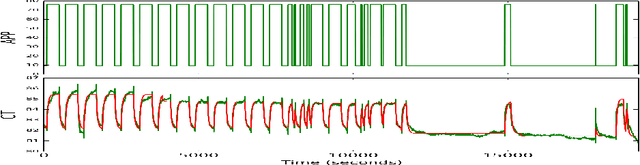
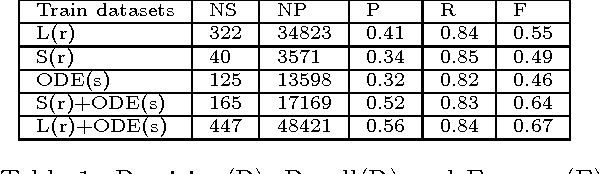
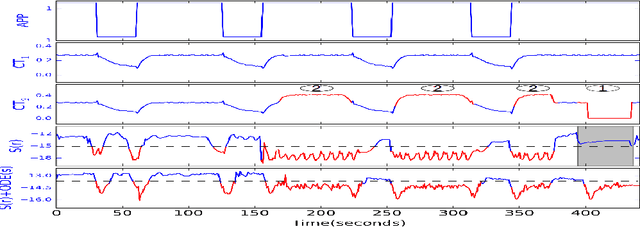

Machines of all kinds from vehicles to industrial equipment are increasingly instrumented with hundreds of sensors. Using such data to detect anomalous behaviour is critical for safety and efficient maintenance. However, anomalies occur rarely and with great variety in such systems, so there is often insufficient anomalous data to build reliable detectors. A standard approach to mitigate this problem is to use one class methods relying only on data from normal behaviour. Unfortunately, even these approaches are more likely to fail in the scenario of a dynamical system with manual control input(s). Normal behaviour in response to novel control input(s) might look very different to the learned detector which may be incorrectly detected as anomalous. In this paper, we address this issue by modelling time-series via Ordinary Differential Equations (ODE) and utilising such an ODE model to simulate the behaviour of dynamical systems under varying control inputs. The available data is then augmented with data generated from the ODE, and the anomaly detector is retrained on this augmented dataset. Experiments demonstrate that ODE-augmented training data allows better coverage of possible control input(s) and results in learning more accurate distinctions between normal and anomalous behaviour in time-series.