 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity-Led AI Integration for Wildfire Risk Assessment: A Participatory AI Literacy and Explainability Integration (PALEI) Framework in Los Angeles, CA
Apr 20, 2026Climate-driven wildfires are intensifying, particularly in urban regions such as Southern California. Yet, traditional fire risk communication tools often fail to gain public trust due to inaccessible design, non-transparent outputs, and limited contextual relevance. These challenges are especially critical in high-risk communities, where trust depends on how clearly and locally information is presented. Neighborhoods such as Pacific Palisades, Pasadena, and Altadena in Los Angeles exemplify these conditions. This study introduces a community-led approach for integrating AI into wildfire risk assessment using the Participatory AI Literacy and Explainability Integration (PALEI) framework. PALEI emphasizes early literacy building, value alignment, and participatory evaluation before deploying predictive models, prioritizing clarity, accessibility, and mutual learning between developers and residents. Early engagement findings show strong acceptance of visual, context-specific risk communication, positive fairness perceptions, and clear adoption interest, alongside privacy and data security concerns that influence trust. Participants emphasized localized imagery, accessible explanations, neighborhood-specific mitigation guidance, and transparent communication of uncertainty. The outcome is a mobile application co-designed with users and stakeholders, enabling residents to scan visible property features and receive interpretable fire risk scores with tailored recommendations. By embedding local context into design, the tool becomes an everyday resource for risk awareness and preparedness. This study argues that user experience is central to ethical and effective AI deployment and provides a replicable, literacy-first pathway for applying the PALEI framework to climate-related hazards.
Bioacoustical Periodic Pulse Train Signal Detection and Classification using Spectrogram Intensity Binarization and Energy Projection
Jun 28, 2013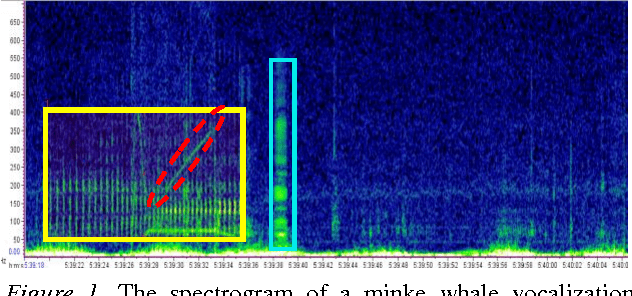
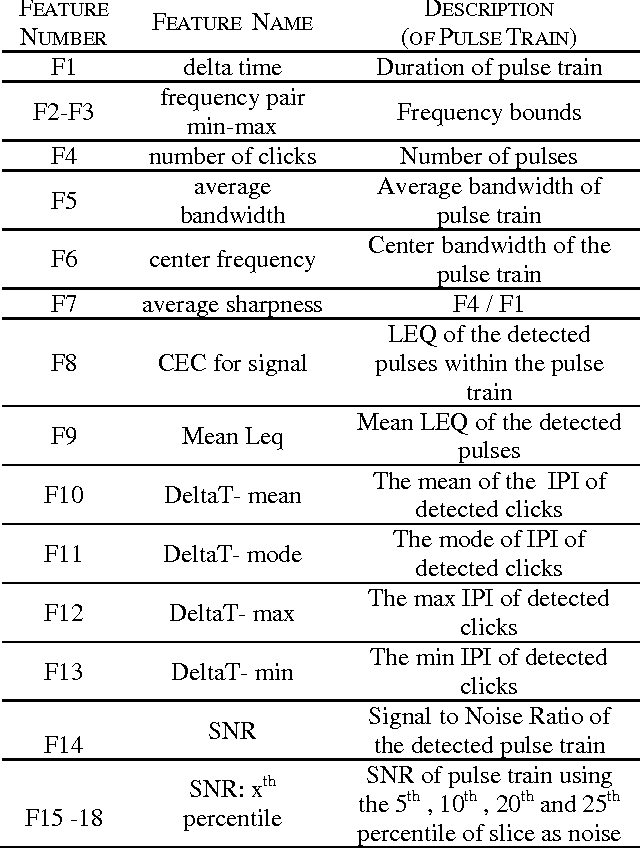
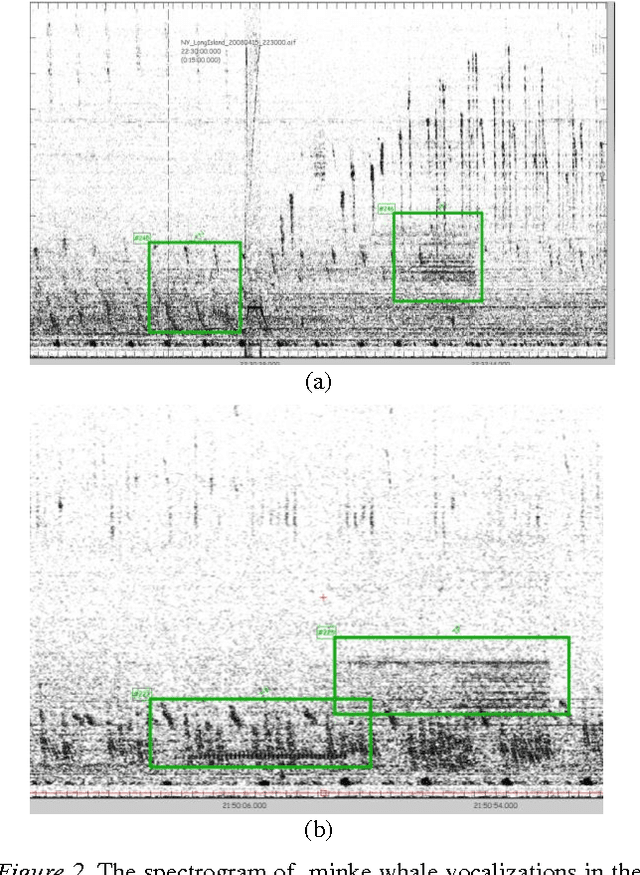
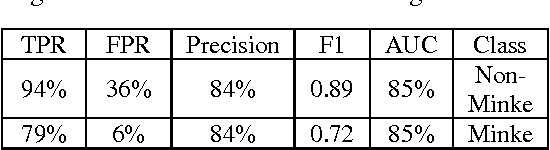
The following work outlines an approach for automatic detection and recognition of periodic pulse train signals using a multi-stage process based on spectrogram edge detection, energy projection and classification. The method has been implemented to automatically detect and recognize pulse train songs of minke whales. While the long term goal of this work is to properly identify and detect minke songs from large multi-year datasets, this effort was developed using sounds off the coast of Massachusetts, in the Stellwagen Bank National Marine Sanctuary. The detection methodology is presented and evaluated on 232 continuous hours of acoustic recordings and a qualitative analysis of machine learning classifiers and their performance is described. The trained automatic detection and classification system is applied to 120 continuous hours, comprised of various challenges such as broadband and narrowband noises, low SNR, and other pulse train signatures. This automatic system achieves a TPR of 63% for FPR of 0.6% (or 0.87 FP/h), at a Precision (PPV) of 84% and an F1 score of 71%.
Classification for Big Dataset of Bioacoustic Signals Based on Human Scoring System and Artificial Neural Network
Jun 17, 2013
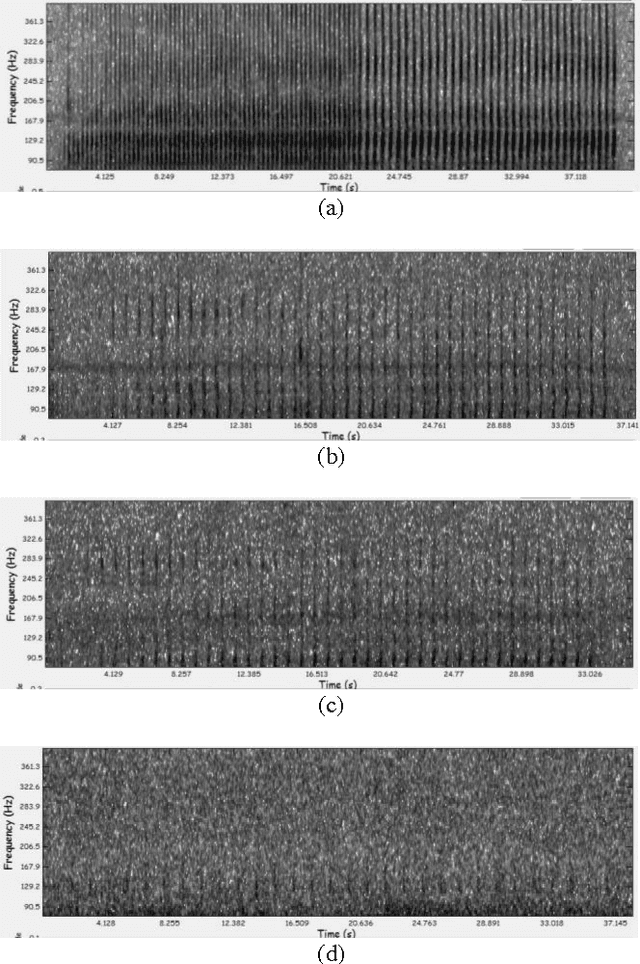
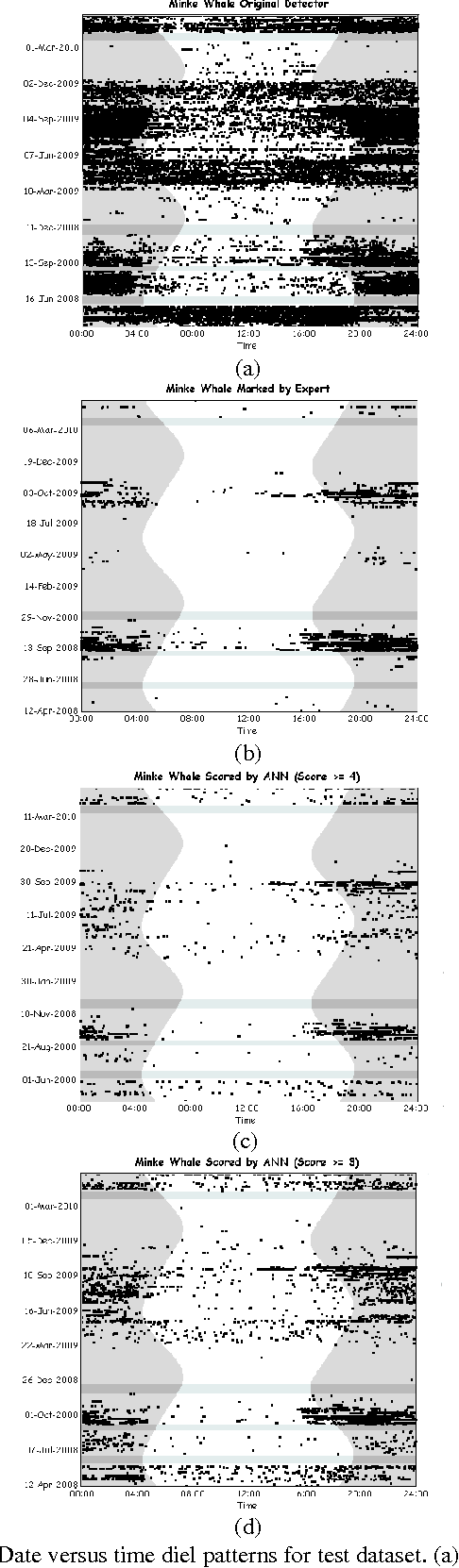
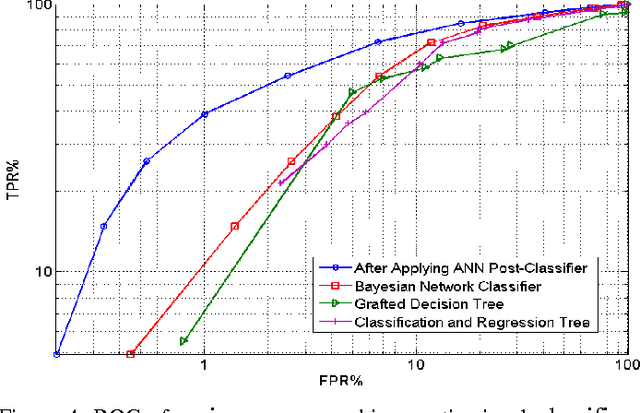
In this paper, we propose a method to improve sound classification performance by combining signal features, derived from the time-frequency spectrogram, with human perception. The method presented herein exploits an artificial neural network (ANN) and learns the signal features based on the human perception knowledge. The proposed method is applied to a large acoustic dataset containing 24 months of nearly continuous recordings. The results show a significant improvement in performance of the detection-classification system; yielding as much as 20% improvement in true positive rate for a given false positive rate.
Bioacoustic Signal Classification Based on Continuous Region Processing, Grid Masking and Artificial Neural Network
Jun 17, 2013
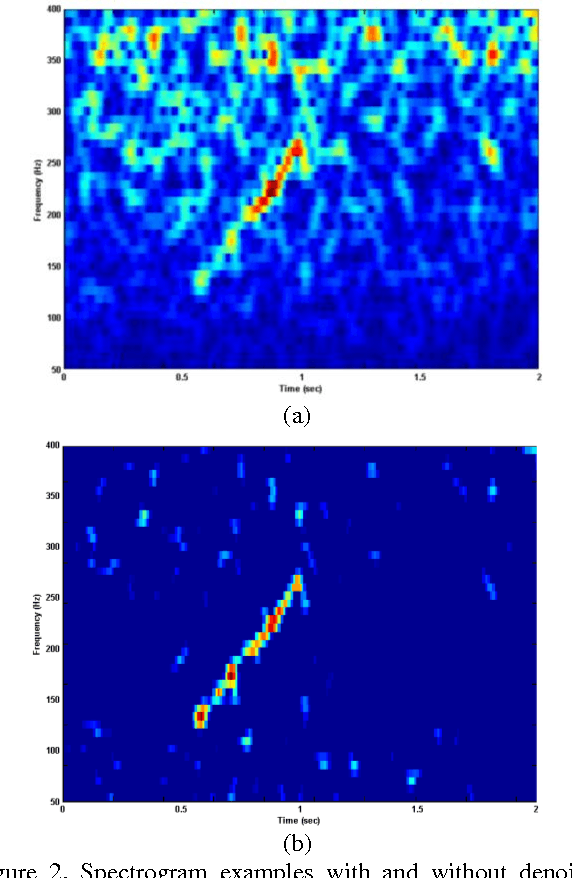

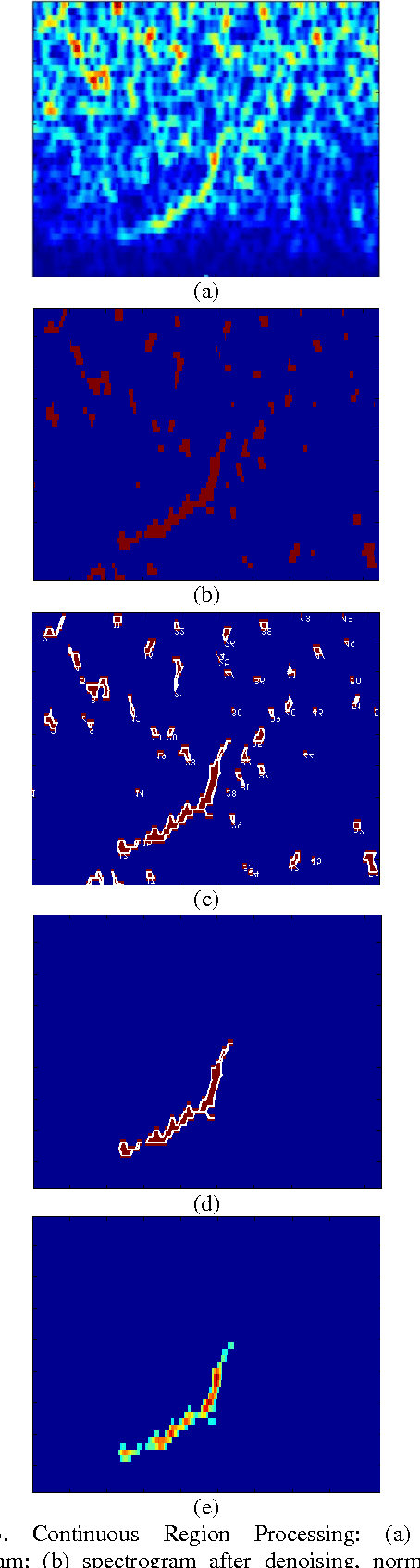
In this paper, we develop a novel method based on machine-learning and image processing to identify North Atlantic right whale (NARW) up-calls in the presence of high levels of ambient and interfering noise. We apply a continuous region algorithm on the spectrogram to extract the regions of interest, and then use grid masking techniques to generate a small feature set that is then used in an artificial neural network classifier to identify the NARW up-calls. It is shown that the proposed technique is effective in detecting and capturing even very faint up-calls, in the presence of ambient and interfering noises. The method is evaluated on a dataset recorded in Massachusetts Bay, United States. The dataset includes 20000 sound clips for training, and 10000 sound clips for testing. The results show that the proposed technique can achieve an error rate of less than FPR = 4.5% for a 90% true positive rate.