 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Effects of Deep Brain Stimulation and Medication on the Dynamics of STN-LFP Signals for Human Behavior Analysis
Apr 09, 2018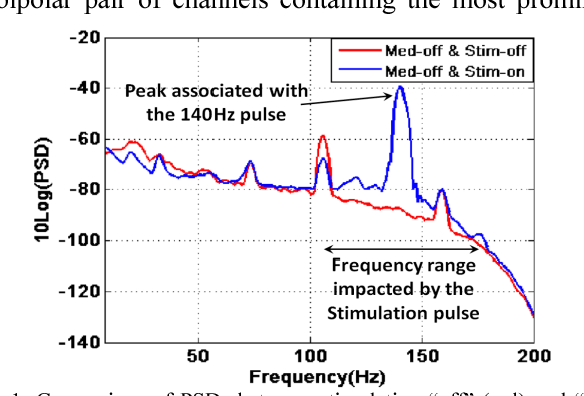
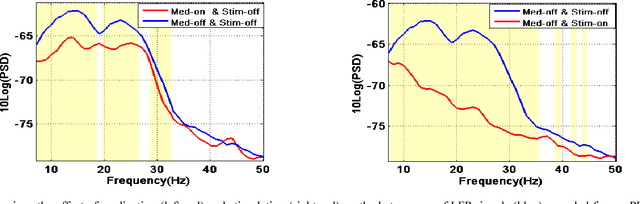
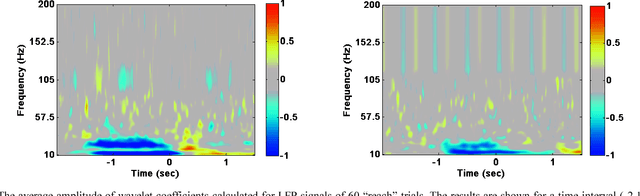
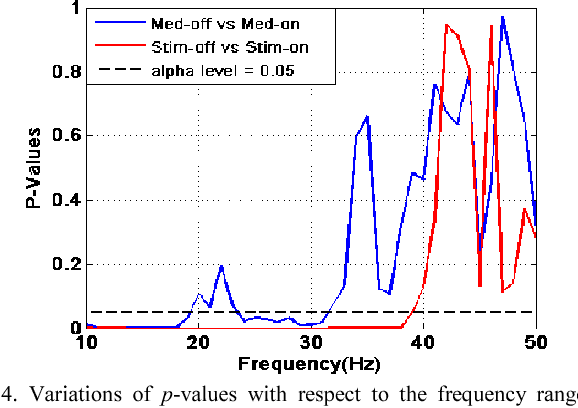
This paper presents the results of our recent work on studying the effects of deep brain stimulation (DBS) and medication on the dynamics of brain local field potential (LFP) signals used for behavior analysis of patients with Parkinson s disease (PD). DBS is a technique used to alleviate the severe symptoms of PD when pharmacotherapy is not very effective. Behavior recognition from the LFP signals recorded from the subthalamic nucleus (STN) has application in developing closed-loop DBS systems, where the stimulation pulse is adaptively generated according to subjects performing behavior. Most of the existing studies on behavior recognition that use STN-LFPs are based on the DBS being off. This paper discovers how the performance and accuracy of automated behavior recognition from the LFP signals are affected under different paradigms of stimulation on/off. We first study the notion of beta power suppression in LFP signals under different scenarios (stimulation on/off and medication on/off). Afterward, we explore the accuracy of support vector machines in predicting human actions (button press and reach) using the spectrogram of STN-LFP signals. Our experiments on the recorded LFP signals of three subjects confirm that the beta power is suppressed significantly when the patients take medication (p-value<0.002) or stimulation (p-value<0.0003). The results also show that we can classify different behaviors with a reasonable accuracy of 85% even when the high-amplitude stimulation is applied.
A Pilot Study on Using an Intelligent Life-like Robot as a Companion for Elderly Individuals with Dementia and Depression
Dec 07, 2017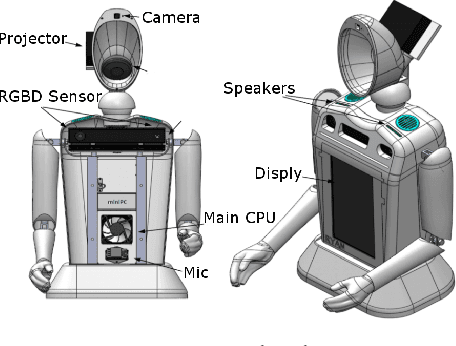
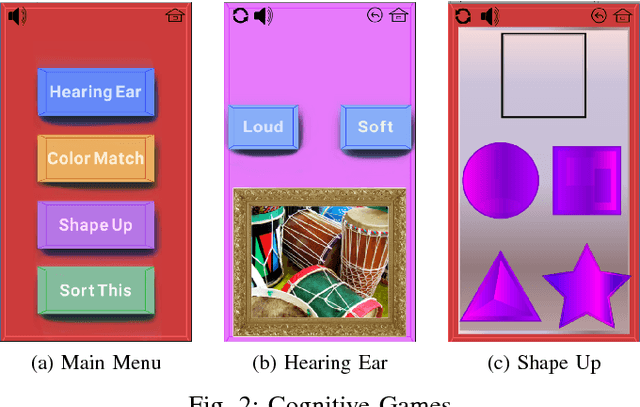

This paper presents the design, development, methodology, and the results of a pilot study on using an intelligent, emotive and perceptive social robot (aka Companionbot) for improving the quality of life of elderly people with dementia and/or depression. Ryan Companionbot prototyped in this project, is a rear-projected life-like conversational robot. Ryan is equipped with features that can (1) interpret and respond to users' emotions through facial expressions and spoken language, (2) proactively engage in conversations with users, and (3) remind them about their daily life schedules (e.g. taking their medicine on time). Ryan engages users in cognitive games and reminiscence activities. We conducted a pilot study with six elderly individuals with moderate dementia and/or depression living in a senior living facility in Denver. Each individual had 24/7 access to a Ryan in his/her room for a period of 4-6 weeks. Our observations of these individuals, interviews with them and their caregivers, and analyses of their interactions during this period revealed that they established rapport with the robot and greatly valued and enjoyed having a Companionbot in their room.
AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild
Oct 09, 2017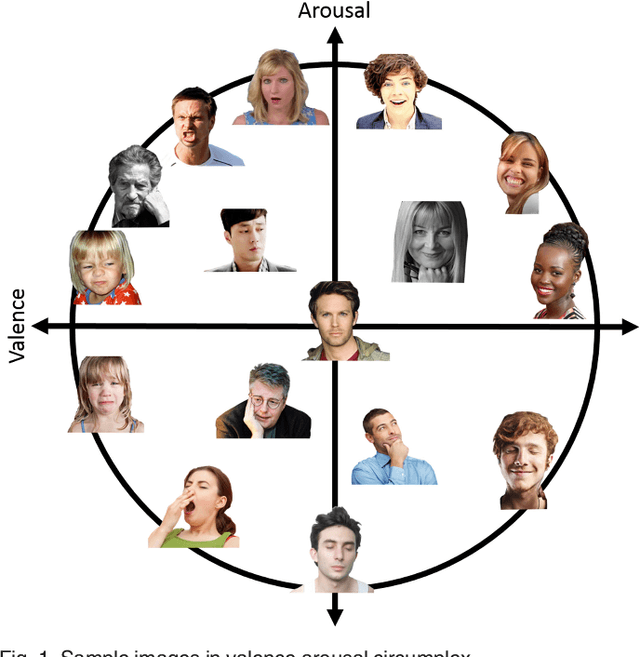
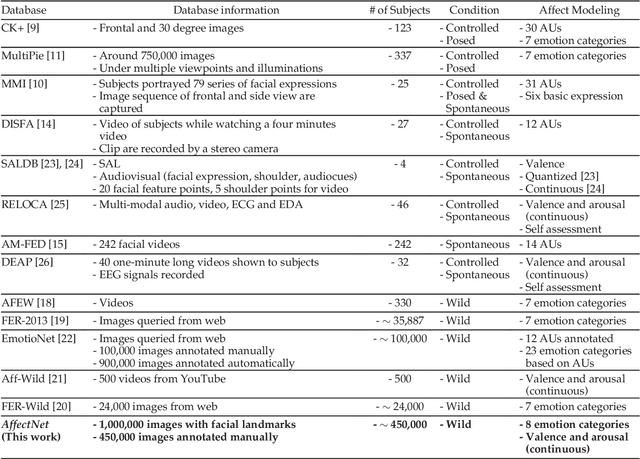
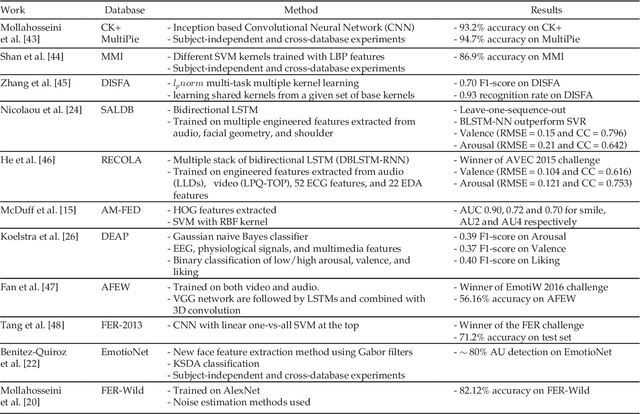
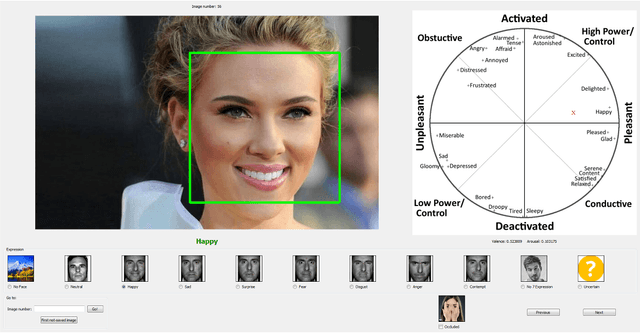
Automated affective computing in the wild setting is a challenging problem in computer vision. Existing annotated databases of facial expressions in the wild are small and mostly cover discrete emotions (aka the categorical model). There are very limited annotated facial databases for affective computing in the continuous dimensional model (e.g., valence and arousal). To meet this need, we collected, annotated, and prepared for public distribution a new database of facial emotions in the wild (called AffectNet). AffectNet contains more than 1,000,000 facial images from the Internet by querying three major search engines using 1250 emotion related keywords in six different languages. About half of the retrieved images were manually annotated for the presence of seven discrete facial expressions and the intensity of valence and arousal. AffectNet is by far the largest database of facial expression, valence, and arousal in the wild enabling research in automated facial expression recognition in two different emotion models. Two baseline deep neural networks are used to classify images in the categorical model and predict the intensity of valence and arousal. Various evaluation metrics show that our deep neural network baselines can perform better than conventional machine learning methods and off-the-shelf facial expression recognition systems.
Facial Affect Estimation in the Wild Using Deep Residual and Convolutional Networks
May 22, 2017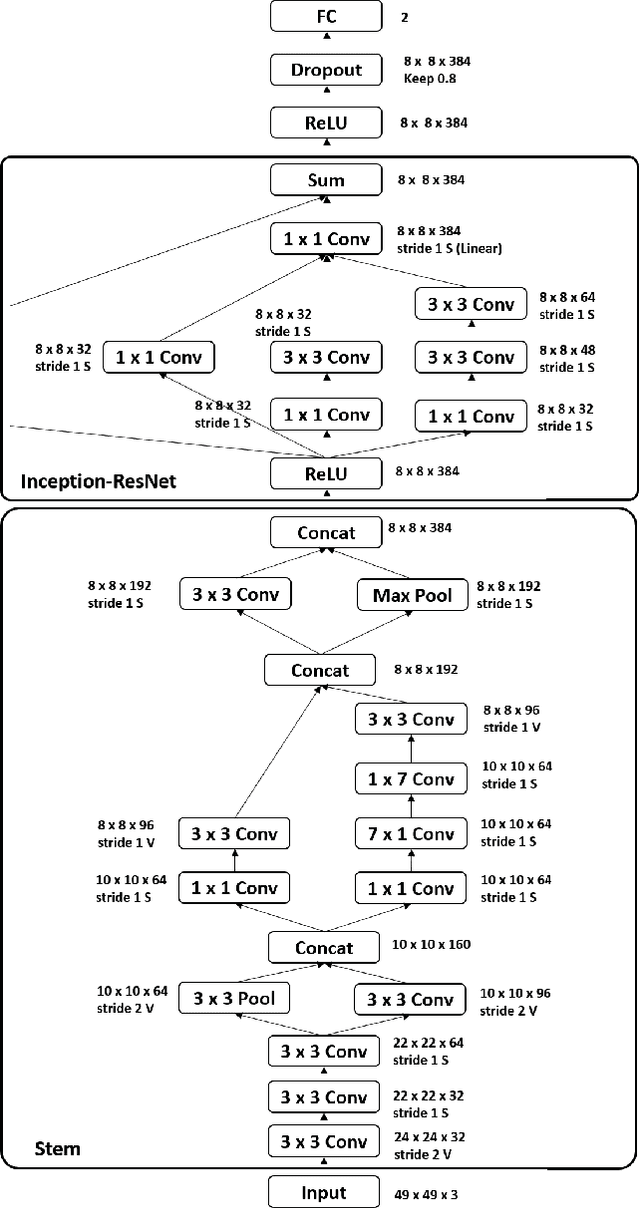

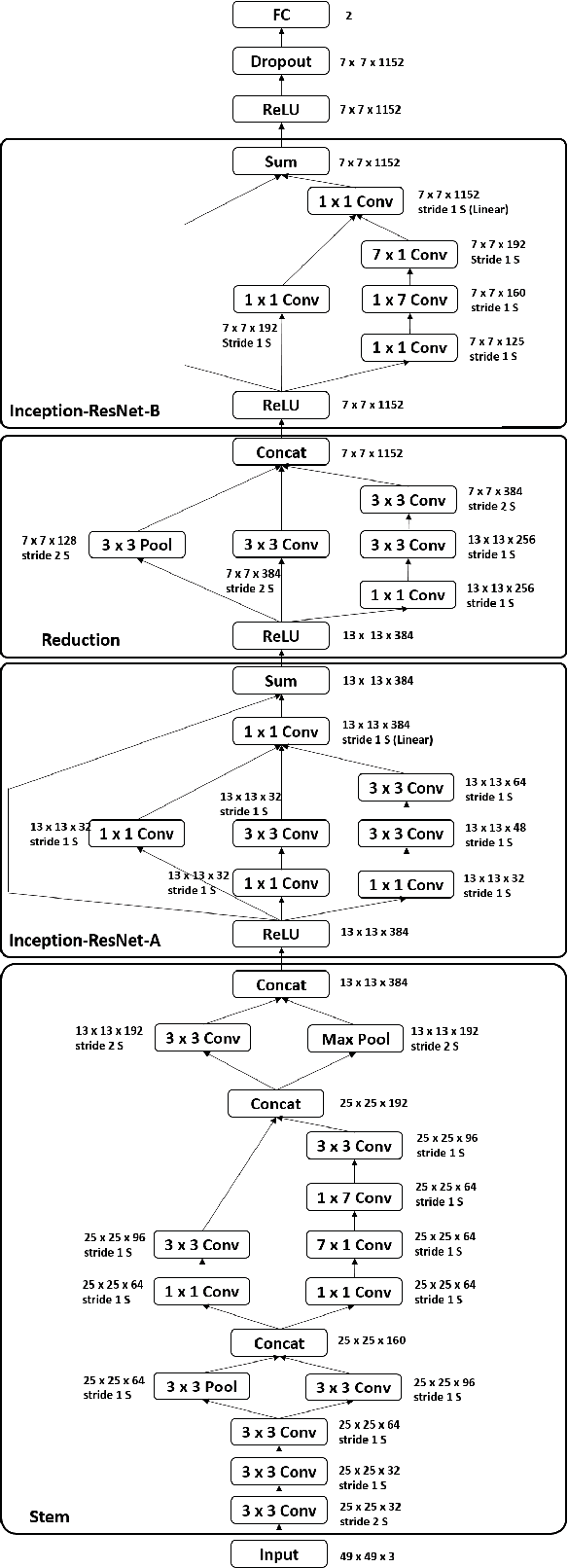
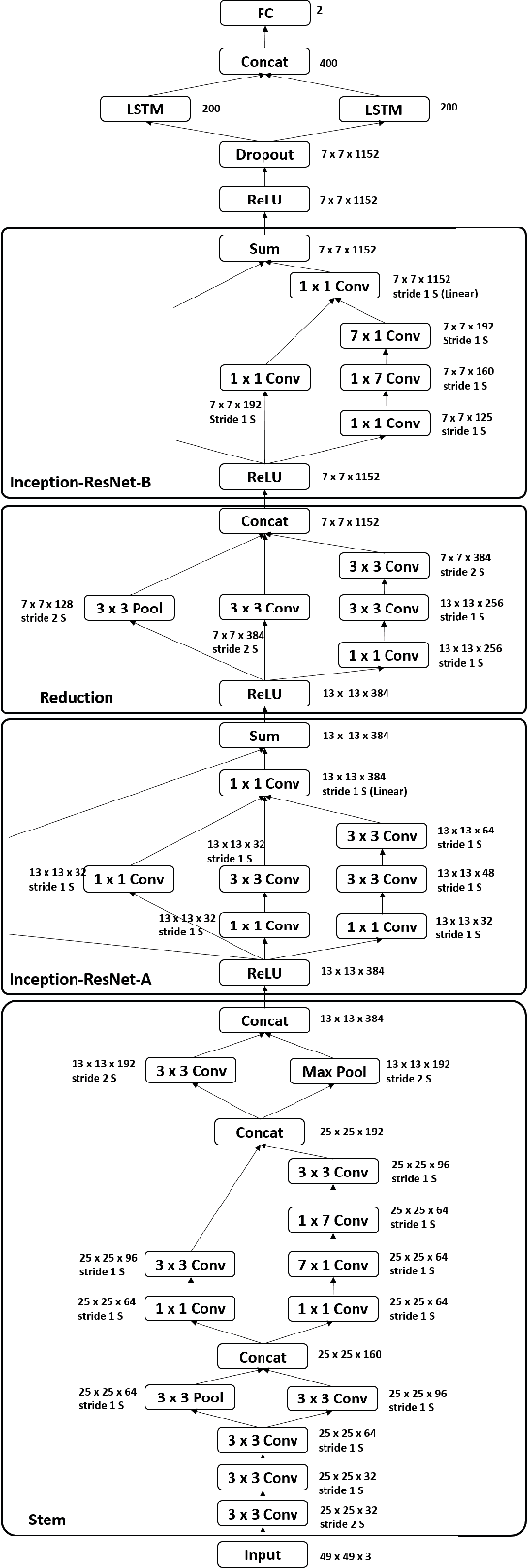
Automated affective computing in the wild is a challenging task in the field of computer vision. This paper presents three neural network-based methods proposed for the task of facial affect estimation submitted to the First Affect-in-the-Wild challenge. These methods are based on Inception-ResNet modules redesigned specifically for the task of facial affect estimation. These methods are: Shallow Inception-ResNet, Deep Inception-ResNet, and Inception-ResNet with LSTMs. These networks extract facial features in different scales and simultaneously estimate both the valence and arousal in each frame. Root Mean Square Error (RMSE) rates of 0.4 and 0.3 are achieved for the valence and arousal respectively with corresponding Concordance Correlation Coefficient (CCC) rates of 0.04 and 0.29 using Deep Inception-ResNet method.
Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks
May 22, 2017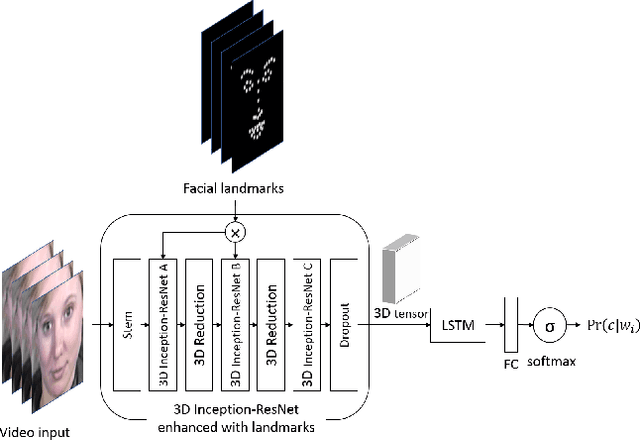
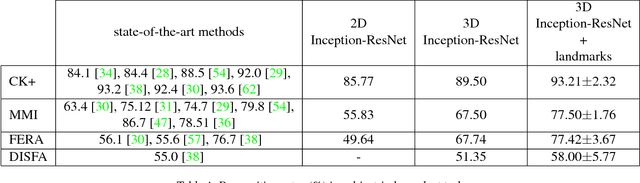
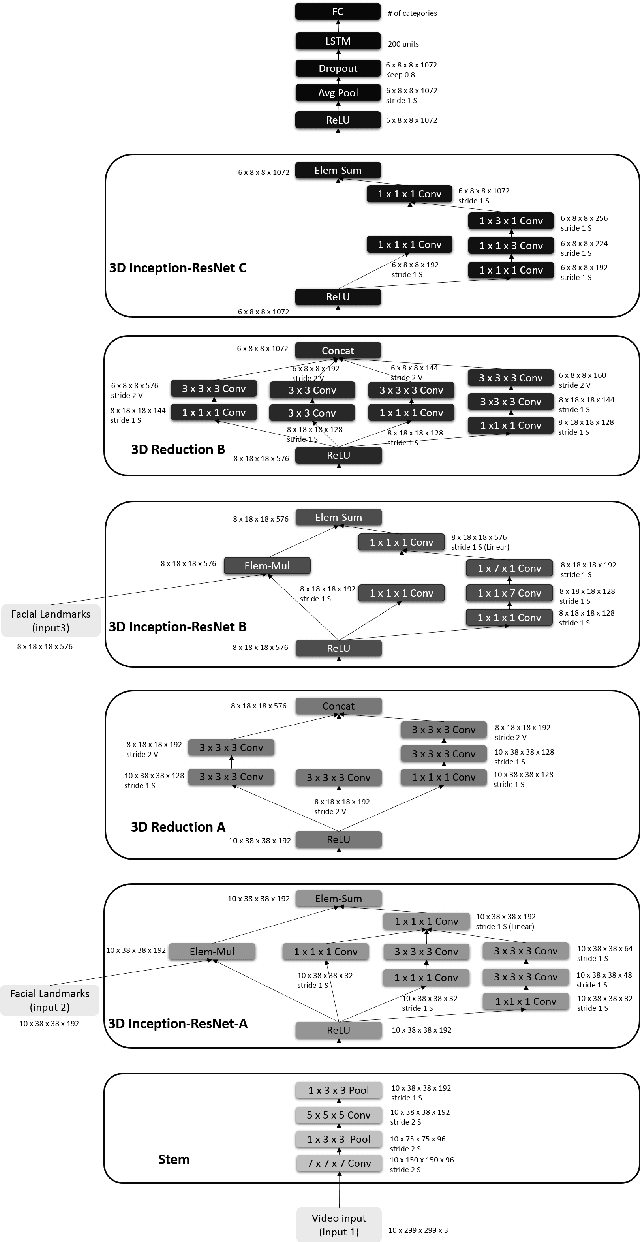
Deep Neural Networks (DNNs) have shown to outperform traditional methods in various visual recognition tasks including Facial Expression Recognition (FER). In spite of efforts made to improve the accuracy of FER systems using DNN, existing methods still are not generalizable enough in practical applications. This paper proposes a 3D Convolutional Neural Network method for FER in videos. This new network architecture consists of 3D Inception-ResNet layers followed by an LSTM unit that together extracts the spatial relations within facial images as well as the temporal relations between different frames in the video. Facial landmark points are also used as inputs to our network which emphasize on the importance of facial components rather than the facial regions that may not contribute significantly to generating facial expressions. Our proposed method is evaluated using four publicly available databases in subject-independent and cross-database tasks and outperforms state-of-the-art methods.
Spatio-Temporal Facial Expression Recognition Using Convolutional Neural Networks and Conditional Random Fields
Apr 24, 2017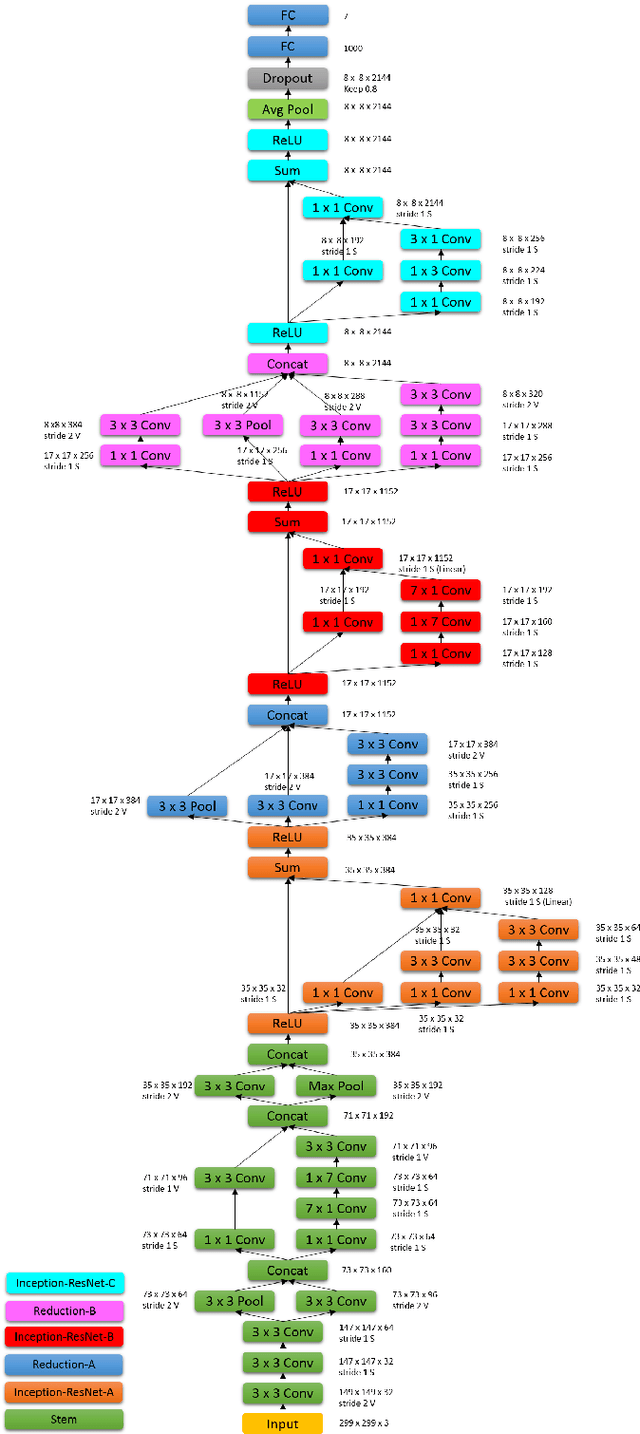
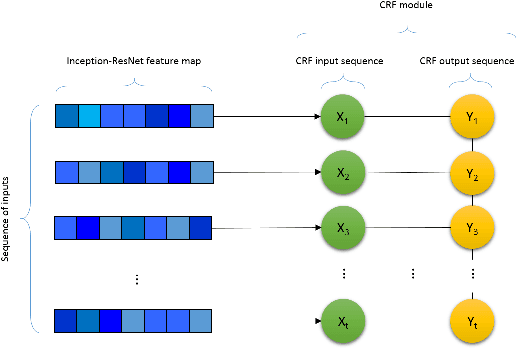
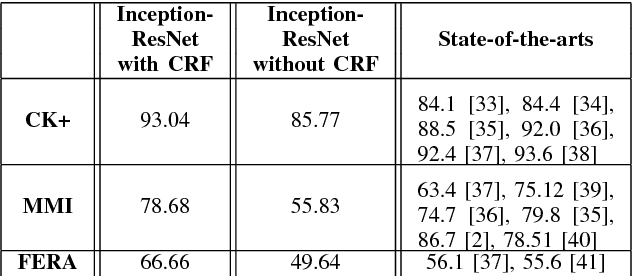
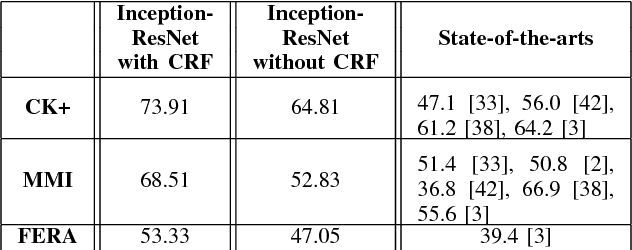
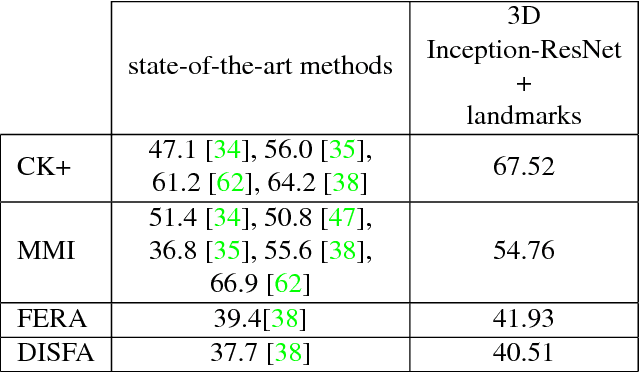
Automated Facial Expression Recognition (FER) has been a challenging task for decades. Many of the existing works use hand-crafted features such as LBP, HOG, LPQ, and Histogram of Optical Flow (HOF) combined with classifiers such as Support Vector Machines for expression recognition. These methods often require rigorous hyperparameter tuning to achieve good results. Recently Deep Neural Networks (DNN) have shown to outperform traditional methods in visual object recognition. In this paper, we propose a two-part network consisting of a DNN-based architecture followed by a Conditional Random Field (CRF) module for facial expression recognition in videos. The first part captures the spatial relation within facial images using convolutional layers followed by three Inception-ResNet modules and two fully-connected layers. To capture the temporal relation between the image frames, we use linear chain CRF in the second part of our network. We evaluate our proposed network on three publicly available databases, viz. CK+, MMI, and FERA. Experiments are performed in subject-independent and cross-database manners. Our experimental results show that cascading the deep network architecture with the CRF module considerably increases the recognition of facial expressions in videos and in particular it outperforms the state-of-the-art methods in the cross-database experiments and yields comparable results in the subject-independent experiments.
Facial Expression Recognition from World Wild Web
Jan 05, 2017


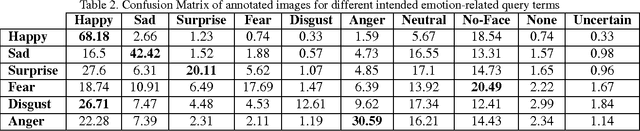
Recognizing facial expression in a wild setting has remained a challenging task in computer vision. The World Wide Web is a good source of facial images which most of them are captured in uncontrolled conditions. In fact, the Internet is a Word Wild Web of facial images with expressions. This paper presents the results of a new study on collecting, annotating, and analyzing wild facial expressions from the web. Three search engines were queried using 1250 emotion related keywords in six different languages and the retrieved images were mapped by two annotators to six basic expressions and neutral. Deep neural networks and noise modeling were used in three different training scenarios to find how accurately facial expressions can be recognized when trained on noisy images collected from the web using query terms (e.g. happy face, laughing man, etc)? The results of our experiments show that deep neural networks can recognize wild facial expressions with an accuracy of 82.12%.
An FFT-based Synchronization Approach to Recognize Human Behaviors using STN-LFP Signal
Dec 28, 2016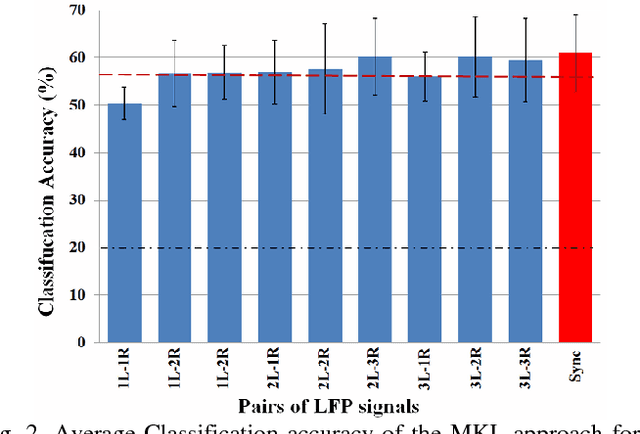
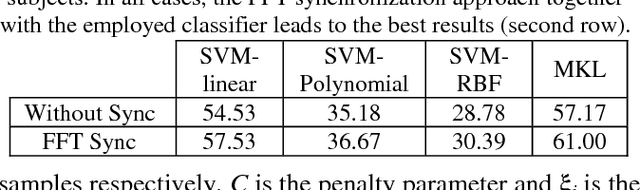
Classification of human behavior is key to developing closed-loop Deep Brain Stimulation (DBS) systems, which may be able to decrease the power consumption and side effects of the existing systems. Recent studies have shown that the Local Field Potential (LFP) signals from both Subthalamic Nuclei (STN) of the brain can be used to recognize human behavior. Since the DBS leads implanted in each STN can collect three bipolar signals, the selection of a suitable pair of LFPs that achieves optimal recognition performance is still an open problem to address. Considering the presence of synchronized aggregate activity in the basal ganglia, this paper presents an FFT-based synchronization approach to automatically select a relevant pair of LFPs and use the pair together with an SVM-based MKL classifier for behavior recognition purposes. Our experiments on five subjects show the superiority of the proposed approach compared to other methods used for behavior classification.
A Multiple Kernel Learning Approach for Human Behavioral Task Classification using STN-LFP Signal
Jul 27, 2016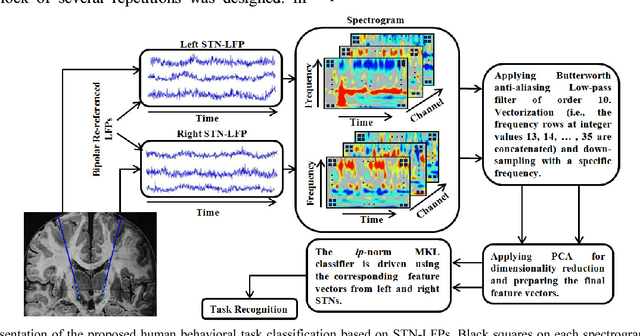
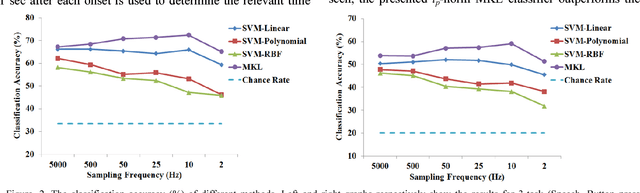
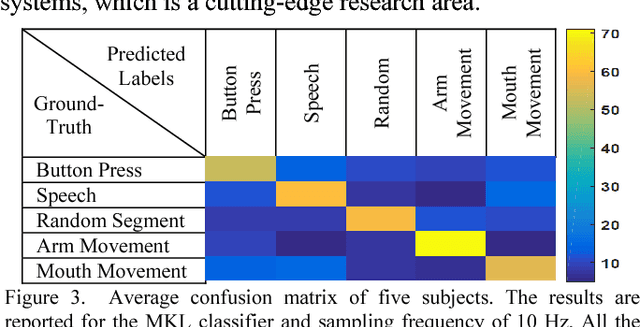
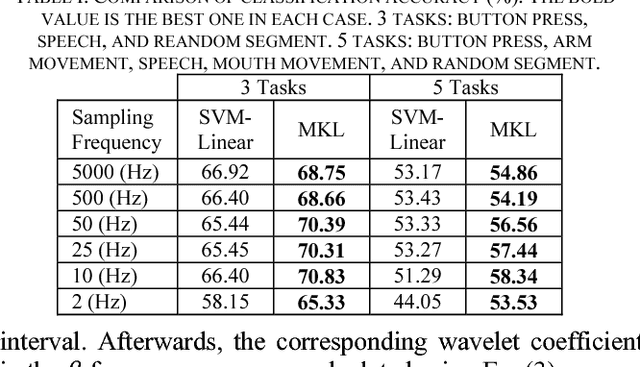
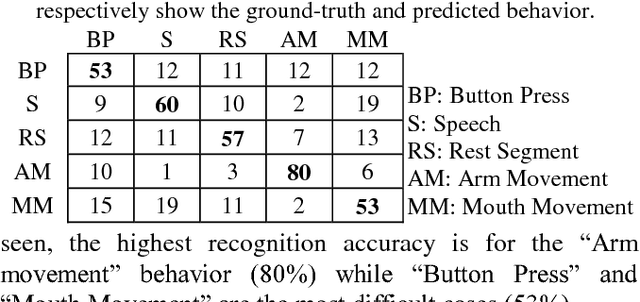
Deep Brain Stimulation (DBS) has gained increasing attention as an effective method to mitigate Parkinsons disease (PD) disorders. Existing DBS systems are open-loop such that the system parameters are not adjusted automatically based on patients behavior. Classification of human behavior is an important step in the design of the next generation of DBS systems that are closed-loop. This paper presents a classification approach to recognize such behavioral tasks using the subthalamic nucleus (STN) Local Field Potential (LFP) signals. In our approach, we use the time-frequency representation (spectrogram) of the raw LFP signals recorded from left and right STNs as the feature vectors. Then these features are combined together via Support Vector Machines (SVM) with Multiple Kernel Learning (MKL) formulation. The MKL-based classification method is utilized to classify different tasks: button press, mouth movement, speech, and arm movement. Our experiments show that the lp-norm MKL significantly outperforms single kernel SVM-based classifiers in classifying behavioral tasks of five subjects even using signals acquired with a low sampling rate of 10 Hz. This leads to a lower computational cost.
ExpressionBot: An Emotive Lifelike Robotic Face for Face-to-Face Communication
Nov 20, 2015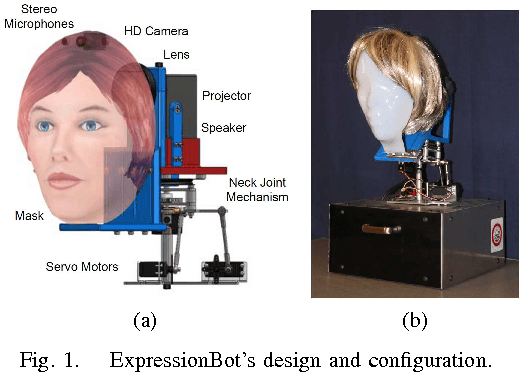
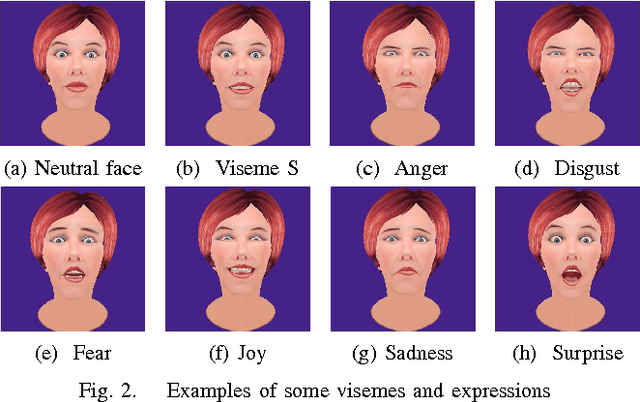
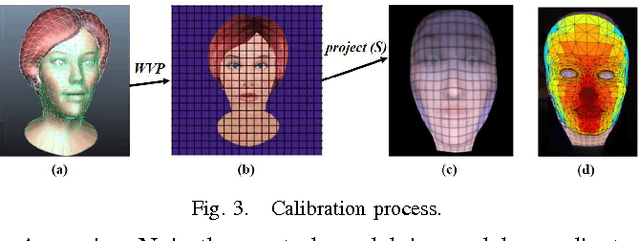

This article proposes an emotive lifelike robotic face, called ExpressionBot, that is designed to support verbal and non-verbal communication between the robot and humans, with the goal of closely modeling the dynamics of natural face-to-face communication. The proposed robotic head consists of two major components: 1) a hardware component that contains a small projector, a fish-eye lens, a custom-designed mask and a neck system with 3 degrees of freedom; 2) a facial animation system, projected onto the robotic mask, that is capable of presenting facial expressions, realistic eye movement, and accurate visual speech. We present three studies that compare Human-Robot Interaction with Human-Computer Interaction with a screen-based model of the avatar. The studies indicate that the robotic face is well accepted by users, with some advantages in recognition of facial expression and mutual eye gaze contact.