 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalities at Play: Probing Alignment in AI Teammates
Feb 28, 2026Collaborative problem solving and learning are shaped by who or what is on the team. As large language models (LLMs) increasingly function as collaborators rather than tools, a key question is whether AI teammates can be aligned to express personality in predictable ways that matter for interaction and learning. We investigate AI personality alignment through a three-lens evaluation framework spanning self-perception (standardized self-report), behavioral expression (team dialogue), and reflective expression (memory construction). We first administered the Big Five Inventory (BFI-44) to LLM-based teammates across four providers (GPT-4o, Claude-3.7 Sonnet, Gemini-2.5 Pro, Grok-3), 32 high/low trait configurations, and multiple prompting strategies. LLMs produced sharply differentiated Big Five profiles, but prompt semantic richness added little beyond simple trait assignment, while provider differences and baseline "default" personalities were substantial. Role framing also mattered: several models refused the assessment without context, yet complied when framed as a collaborative teammate. We then simulated AI participation in authentic team transcripts using high-trait personas and analyzed both generated utterances and structured long-term memories with LIWC-22. Personality signals in conversation were generally subtle and most detectable for Extraversion, whereas memory representations amplified trait-specific signals, especially for Neuroticism, Conscientiousness, and Agreeableness; Openness remained difficult to elicit robustly. Together, results suggest that AI personality is measurable but multi-layered and context-dependent, and that evaluating personality-aligned AI teammates requires attention to memory and system-level design, not conversation-only behavior.
Multi-Agent Collaborative Framework For Math Problem Generation
Nov 06, 2025Automatic question generation (AQG) for mathematics education remains an elusive goal for Intelligent Tutoring Systems and educators. While pre-trained transformer-based language models have significantly advanced natural language generation, they often struggle to precisely control problem complexity and cognitive demands. In this paper, we introduce a collaborative multi-agent framework as a novel method of incorporating inference-time computation into AQG. This approach leverages multiple agents that iteratively refine generated question-answer pairs to better balance complexity and cognitive demand. We evaluate the generated questions on five meta-evaluation criteria: relevance, importance, clarity, difficulty matching, answerability, to assess the system's ability to control the required complexity and quality of the questions. Preliminary evaluations show that this collaborative multi-agent framework elevates the quality of generated educational content by fostering a more nuanced balance between cognitive challenge and clarity. These promising outcomes suggest that integrating collaborative multi-agent workflows can yield more controlled, pedagogically valuable content that can help advance automated educational content generation and adaptive learning environments.
* Published in the Proceedings of the 18th International Conference on Educational Data Mining, 6 pages, 5 figures
The AI Collaborator: Bridging Human-AI Interaction in Educational and Professional Settings
May 16, 2024

AI Collaborator, powered by OpenAI's GPT-4, is a groundbreaking tool designed for human-AI collaboration research. Its standout feature is the ability for researchers to create customized AI personas for diverse experimental setups using a user-friendly interface. This functionality is essential for simulating various interpersonal dynamics in team settings. AI Collaborator excels in mimicking different team behaviors, enabled by its advanced memory system and a sophisticated personality framework. Researchers can tailor AI personas along a spectrum from dominant to cooperative, enhancing the study of their impact on team processes. The tool's modular design facilitates integration with digital platforms like Slack, making it versatile for various research scenarios. AI Collaborator is thus a crucial resource for exploring human-AI team dynamics more profoundly.
Evaluating Sparse Interpretable Word Embeddings for Biomedical Domain
May 11, 2020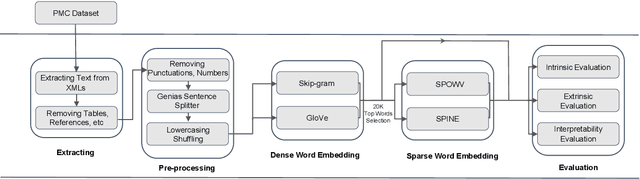
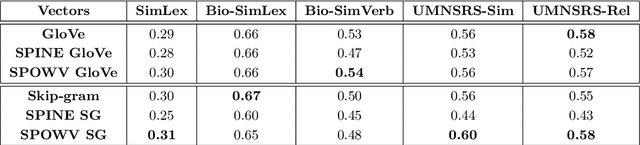
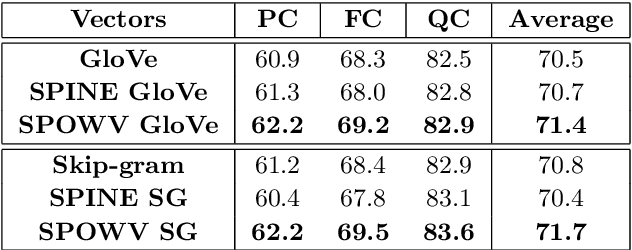
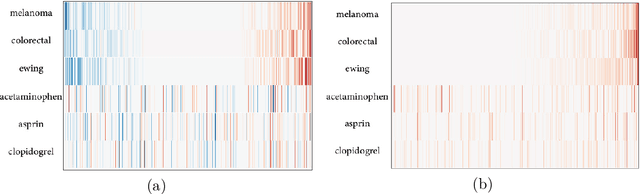
Word embeddings have found their way into a wide range of natural language processing tasks including those in the biomedical domain. While these vector representations successfully capture semantic and syntactic word relations, hidden patterns and trends in the data, they fail to offer interpretability. Interpretability is a key means to justification which is an integral part when it comes to biomedical applications. We present an inclusive study on interpretability of word embeddings in the medical domain, focusing on the role of sparse methods. Qualitative and quantitative measurements and metrics for interpretability of word vector representations are provided. For the quantitative evaluation, we introduce an extensive categorized dataset that can be used to quantify interpretability based on category theory. Intrinsic and extrinsic evaluation of the studied methods are also presented. As for the latter, we propose datasets which can be utilized for effective extrinsic evaluation of word vectors in the biomedical domain. Based on our experiments, it is seen that sparse word vectors show far more interpretability while preserving the performance of their original vectors in downstream tasks.