 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Neural Code Intelligence Through Program Simplification
Jun 07, 2021

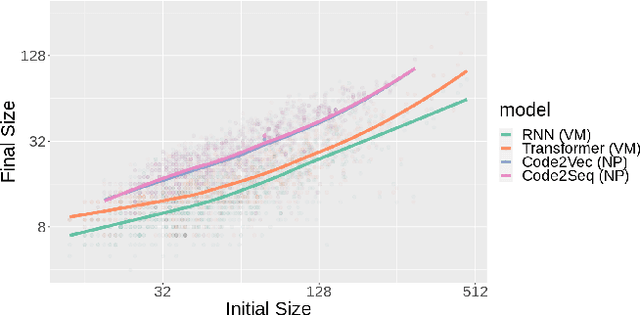
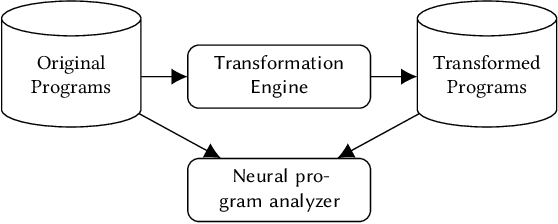
A wide range of code intelligence (CI) tools, powered by deep neural networks, have been developed recently to improve programming productivity and perform program analysis. To reliably use such tools, developers often need to reason about the behavior of the underlying models and the factors that affect them. This is especially challenging for tools backed by deep neural networks. Various methods have tried to reduce this opacity in the vein of "transparent/interpretable-AI". However, these approaches are often specific to a particular set of network architectures, even requiring access to the network's parameters. This makes them difficult to use for the average programmer, which hinders the reliable adoption of neural CI systems. In this paper, we propose a simple, model-agnostic approach to identify critical input features for models in CI systems, by drawing on software debugging research, specifically delta debugging. Our approach, SIVAND, uses simplification techniques that reduce the size of input programs of a CI model while preserving the predictions of the model. We show that this approach yields remarkably small outputs and is broadly applicable across many model architectures and problem domains. We find that the models in our experiments often rely heavily on just a few syntactic features in input programs. We believe that SIVAND's extracted features may help understand neural CI systems' predictions and learned behavior.
Towards Demystifying Dimensions of Source Code Embeddings
Sep 29, 2020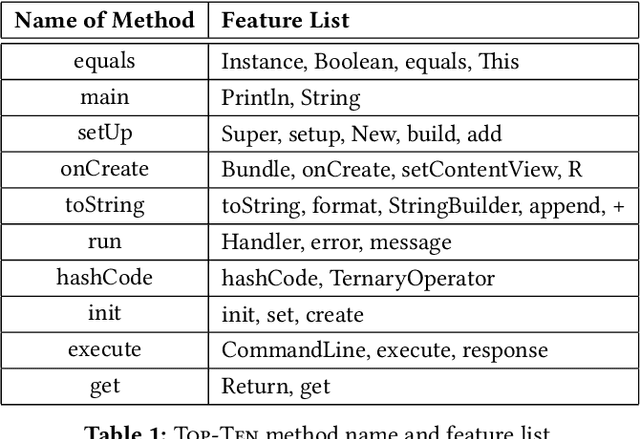

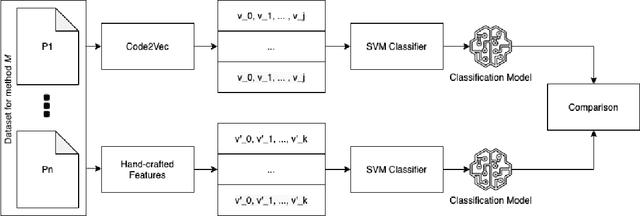
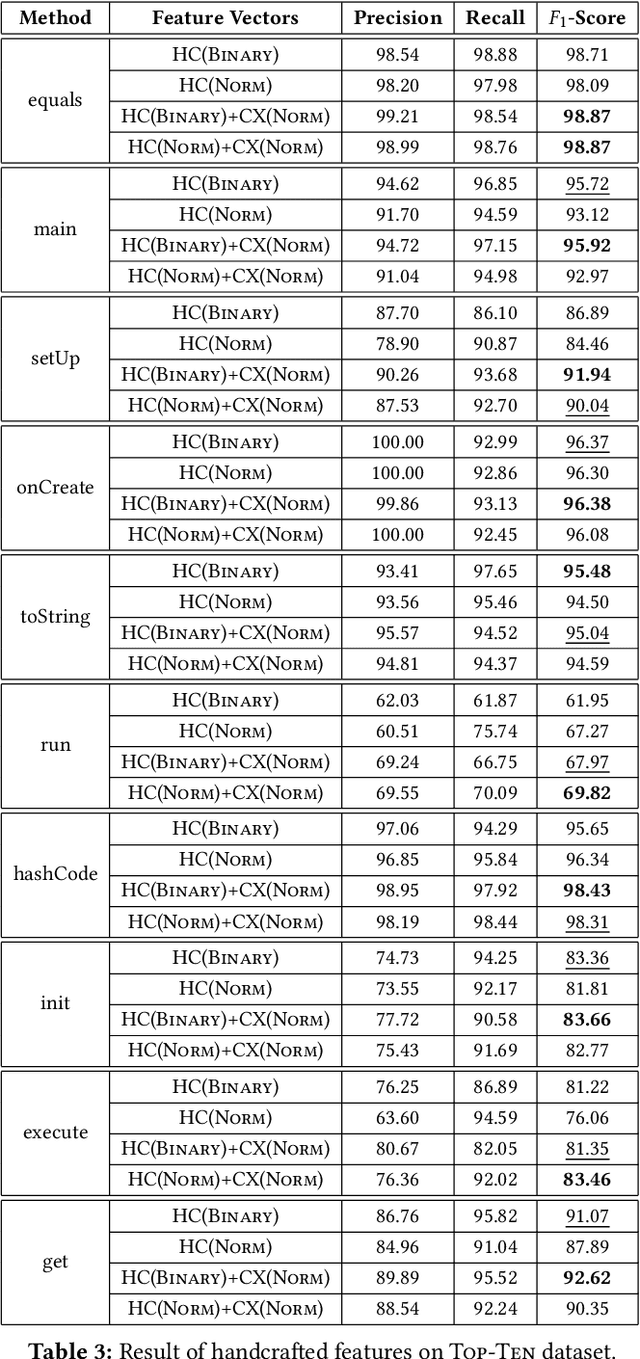
Source code representations are key in applying machine learning techniques for processing and analyzing programs. A popular approach in representing source code is neural source code embeddings that represents programs with high-dimensional vectors computed by training deep neural networks on a large volume of programs. Although successful, there is little known about the contents of these vectors and their characteristics. In this paper, we present our preliminary results towards better understanding the contents of code2vec neural source code embeddings. In particular, in a small case study, we use the code2vec embeddings to create binary SVM classifiers and compare their performance with the handcrafted features. Our results suggest that the handcrafted features can perform very close to the highly-dimensional code2vec embeddings, and the information gains are more evenly distributed in the code2vec embeddings compared to the handcrafted features. We also find that the code2vec embeddings are more resilient to the removal of dimensions with low information gains than the handcrafted features. We hope our results serve a stepping stone toward principled analysis and evaluation of these code representations.
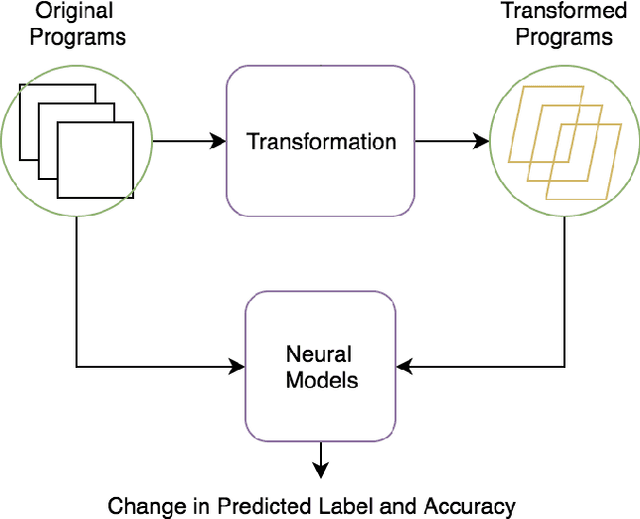
On the Generalizability of Neural Program Analyzers with respect to Semantic-Preserving Program Transformations
Jul 31, 2020
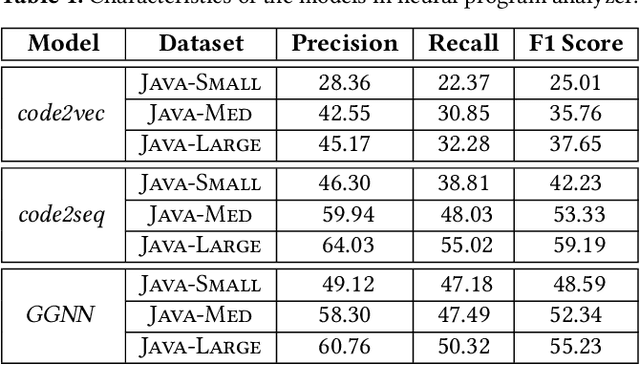
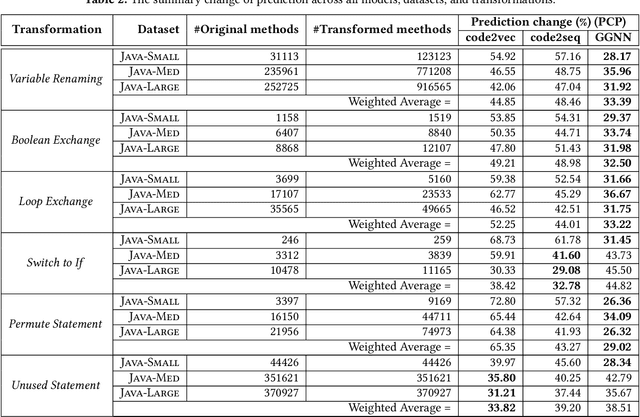
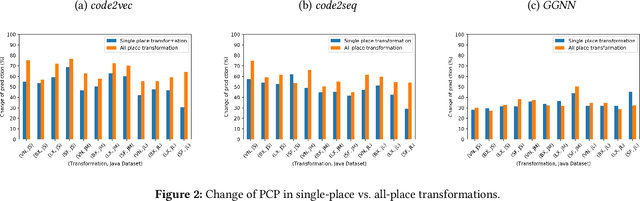
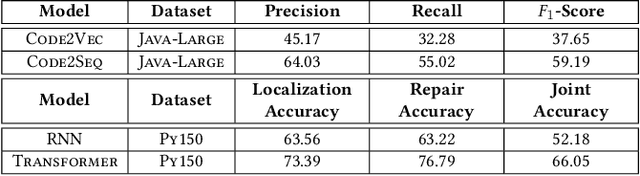
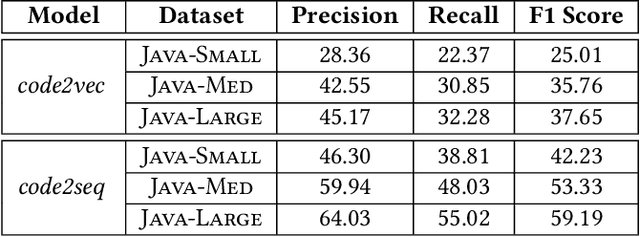
With the prevalence of publicly available source code repositories to train deep neural network models, neural program analyzers can do well in source code analysis tasks such as predicting method names in given programs that cannot be easily done by traditional program analyzers. Although such analyzers have been tested on various existing datasets, the extent in which they generalize to unforeseen source code is largely unknown. Since it is impossible to test neural program analyzers on all unforeseen programs, in this paper, we propose to evaluate the generalizability of neural program analyzers with respect to semantic-preserving transformations: a generalizable neural program analyzer should perform equally well on programs that are of the same semantics but of different lexical appearances and syntactical structures. More specifically, we compare the results of various neural program analyzers for the method name prediction task on programs before and after automated semantic-preserving transformations. We use three Java datasets of different sizes and three state-of-the-art neural network models for code, namely code2vec, code2seq, and Gated Graph Neural Networks (GGNN), to build nine such neural program analyzers for evaluation. Our results show that even with small semantically preserving changes to the programs, these neural program analyzers often fail to generalize their performance. Our results also suggest that neural program analyzers based on data and control dependencies in programs generalize better than neural program analyzers based only on abstract syntax trees. On the positive side, we observe that as the size of training dataset grows and diversifies the generalizability of correct predictions produced by the analyzers can be improved too.
Evaluation of Generalizability of Neural Program Analyzers under Semantic-Preserving Transformations
Apr 15, 2020
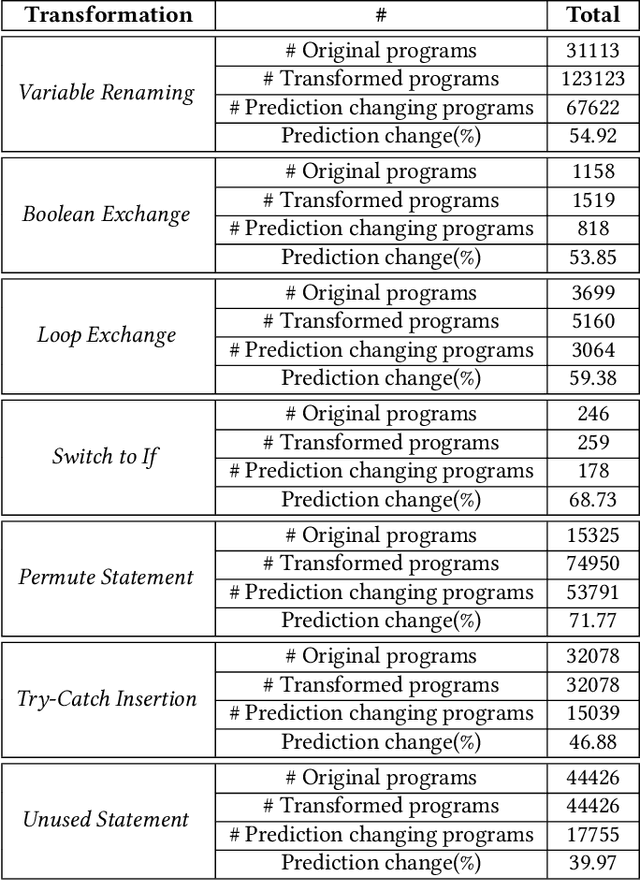
The abundance of publicly available source code repositories, in conjunction with the advances in neural networks, has enabled data-driven approaches to program analysis. These approaches, called neural program analyzers, use neural networks to extract patterns in the programs for tasks ranging from development productivity to program reasoning. Despite the growing popularity of neural program analyzers, the extent to which their results are generalizable is unknown. In this paper, we perform a large-scale evaluation of the generalizability of two popular neural program analyzers using seven semantically-equivalent transformations of programs. Our results caution that in many cases the neural program analyzers fail to generalize well, sometimes to programs with negligible textual differences. The results provide the initial stepping stones for quantifying robustness in neural program analyzers.
Testing Neural Program Analyzers
Sep 25, 2019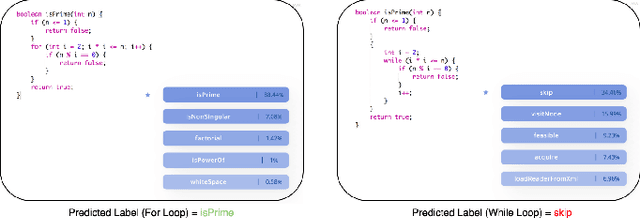
Deep neural networks have been increasingly used in software engineering and program analysis tasks. They usually take a program and make some predictions about it, e.g., bug prediction. We call these models neural program analyzers. The reliability of neural programs can impact the reliability of the encompassing analyses. In this paper, we describe our ongoing efforts to develop effective techniques for testing neural programs. We discuss the challenges involved in developing such tools and our future plans. In our preliminary experiment on a neural model recently proposed in the literature, we found that the model is very brittle, and simple perturbations in the input can cause the model to make mistakes in its prediction.
An Automated Testing Framework for Conversational Agents
Feb 17, 2019
Conversational agents are systems with a conversational interface that afford interaction in spoken language. These systems are becoming prevalent and are preferred in various contexts and for many users. Despite their increasing success, the automated testing infrastructure to support the effective and efficient development of such systems compared to traditional software systems is still limited. Automated testing framework for conversational systems can improve the quality of these systems by assisting developers to write, execute, and maintain test cases. In this paper, we introduce our work-in-progress automated testing framework, and its realization in the Python programming language. We discuss some research problems in the development of such an automated testing framework for conversational agents. In particular, we point out the problems of the specification of the expected behavior, known as test oracles, and semantic comparison of utterances.