 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Earth Observation Satellite Schedules under Unknown Operational Constraints: An Active Constraint Acquisition Approach
Apr 14, 2026Earth Observation (EO) satellite scheduling (deciding which imaging tasks to perform and when) is a well-studied combinatorial optimization problem. Existing methods typically assume that the operational constraint model is fully specified in advance. In practice, however, constraints governing separation between observations, power budgets, and thermal limits are often embedded in engineering artefacts or high-fidelity simulators rather than in explicit mathematical models. We study EO scheduling under \emph{unknown constraints}: the objective is known, but feasibility must be learned interactively from a binary oracle. Working with a simplified model restricted to pairwise separation and global capacity constraints, we introduce Conservative Constraint Acquisition~(CCA), a domain-specific procedure designed to identify justified constraints efficiently in practice while limiting unnecessary tightening of the learned model. Embedded in the \textsc{Learn\&Optimize} framework, CCA supports an interactive search process that alternates optimization under a learned constraint model with targeted oracle queries. On synthetic instances with up to 50~tasks and dense constraint networks, L\&O improves over a no-knowledge greedy baseline and uses far fewer main oracle queries than a two-phase acquire-then-solve baseline (FAO). For $n\leq 30$, the average gap drops from 65--68\% (Priority Greedy) to 17.7--35.8\% using L\&O. At $n{=}50$, where the CP-SAT reference is the best feasible solution found in 120~s, L\&O improves on FAO on average (17.9\% vs.\ 20.3\%) while using 21.3 main queries instead of 100 and about $5\times$ less execution time.
Generalized Convergence Analysis of Tsetlin Machines: A Probabilistic Approach to Concept Learning
Oct 03, 2023



Tsetlin Machines (TMs) have garnered increasing interest for their ability to learn concepts via propositional formulas and their proven efficiency across various application domains. Despite this, the convergence proof for the TMs, particularly for the AND operator (\emph{conjunction} of literals), in the generalized case (inputs greater than two bits) remains an open problem. This paper aims to fill this gap by presenting a comprehensive convergence analysis of Tsetlin automaton-based Machine Learning algorithms. We introduce a novel framework, referred to as Probabilistic Concept Learning (PCL), which simplifies the TM structure while incorporating dedicated feedback mechanisms and dedicated inclusion/exclusion probabilities for literals. Given $n$ features, PCL aims to learn a set of conjunction clauses $C_i$ each associated with a distinct inclusion probability $p_i$. Most importantly, we establish a theoretical proof confirming that, for any clause $C_k$, PCL converges to a conjunction of literals when $0.5<p_k<1$. This result serves as a stepping stone for future research on the convergence properties of Tsetlin automaton-based learning algorithms. Our findings not only contribute to the theoretical understanding of Tsetlin Machines but also have implications for their practical application, potentially leading to more robust and interpretable machine learning models.
Solve Optimization Problems with Unknown Constraint Networks
Nov 23, 2021In most optimization problems, users have a clear understanding of the function to optimize (e.g., minimize the makespan for scheduling problems). However, the constraints may be difficult to state and their modelling often requires expertise in Constraint Programming. Active constraint acquisition has been successfully used to support non-experienced users in learning constraint networks through the generation of a sequence of queries. In this paper, we propose Learn&Optimize, a method to solve optimization problems with known objective function and unknown constraint network. It uses an active constraint acquisition algorithm which learns the unknown constraints and computes boundaries for the optimal solution during the learning process. As a result, our method allows users to solve optimization problems without learning the overall constraint network.
Frequent Itemset Mining with Multiple Minimum Supports: a Constraint-based Approach
Sep 16, 2021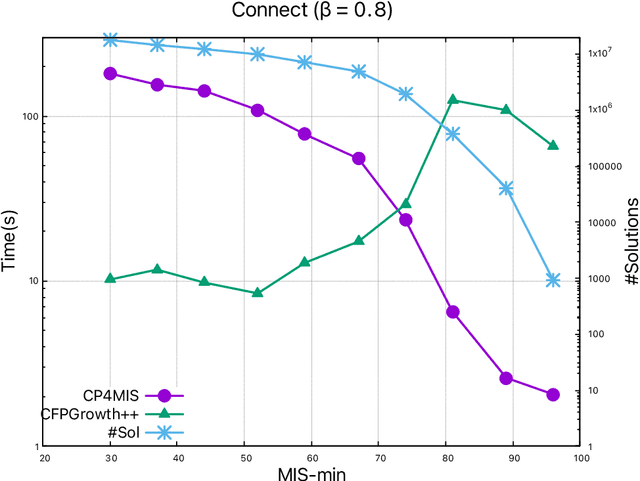
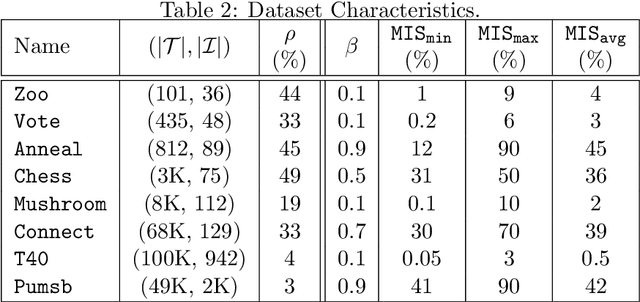
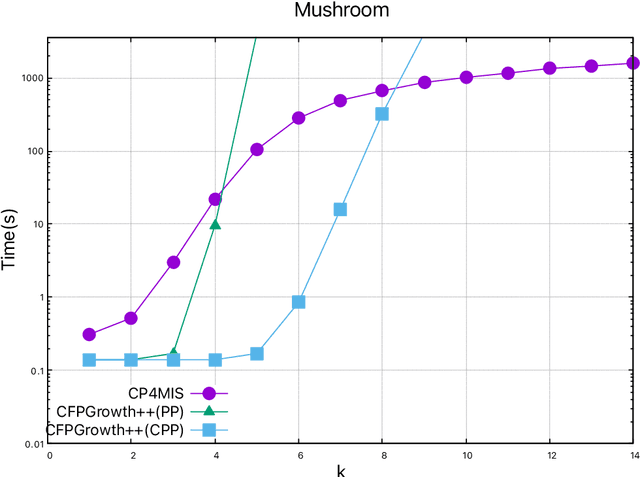
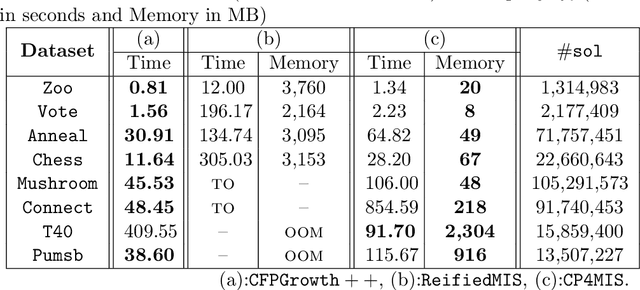
The problem of discovering frequent itemsets including rare ones has received a great deal of attention. The mining process needs to be flexible enough to extract frequent and rare regularities at once. On the other hand, it has recently been shown that constraint programming is a flexible way to tackle data mining tasks. In this paper, we propose a constraint programming approach for mining itemsets with multiple minimum supports. Our approach provides the user with the possibility to express any kind of constraints on the minimum item supports. An experimental analysis shows the practical effectiveness of our approach compared to the state of the art.
Computational Complexity of Three Central Problems in Itemset Mining
Dec 08, 2020

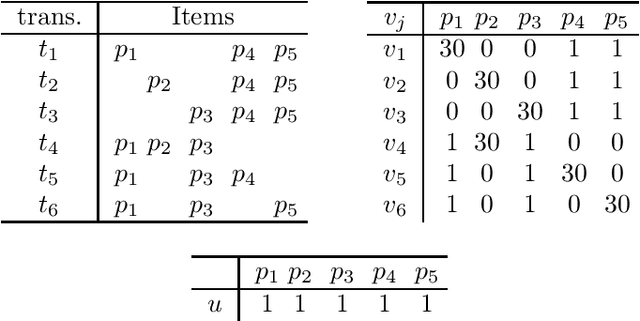
Itemset mining is one of the most studied tasks in knowledge discovery. In this paper we analyze the computational complexity of three central itemset mining problems. We prove that mining confident rules with a given item in the head is NP-hard. We prove that mining high utility itemsets is NP-hard. We finally prove that mining maximal or closed itemsets is coNP-hard as soon as the users can specify constraints on the kind of itemsets they are interested in.
Opening the Software Engineering Toolbox for the Assessment of Trustworthy AI
Jul 14, 2020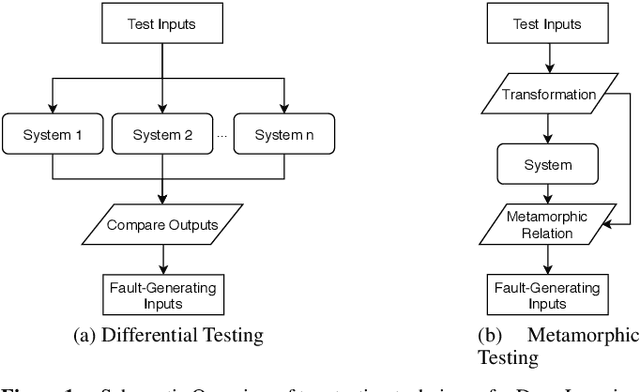
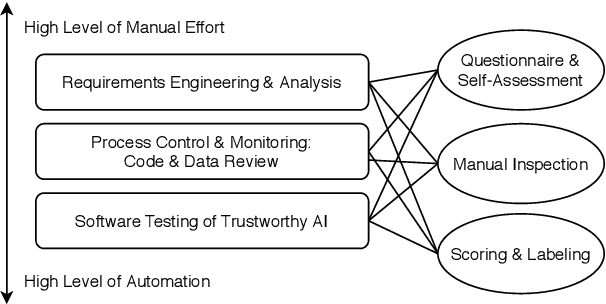
Trustworthiness is a central requirement for the acceptance and success of human-centered artificial intelligence (AI). To deem an AI system as trustworthy, it is crucial to assess its behaviour and characteristics against a gold standard of Trustworthy AI, consisting of guidelines, requirements, or only expectations. While AI systems are highly complex, their implementations are still based on software. The software engineering community has a long-established toolbox for the assessment of software systems, especially in the context of software testing. In this paper, we argue for the application of software engineering and testing practices for the assessment of trustworthy AI. We make the connection between the seven key requirements as defined by the European Commission's AI high-level expert group and established procedures from software engineering and raise questions for future work.