 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models Are Real-Time Game Engines
Aug 27, 2024We present GameNGen, the first game engine powered entirely by a neural model that enables real-time interaction with a complex environment over long trajectories at high quality. GameNGen can interactively simulate the classic game DOOM at over 20 frames per second on a single TPU. Next frame prediction achieves a PSNR of 29.4, comparable to lossy JPEG compression. Human raters are only slightly better than random chance at distinguishing short clips of the game from clips of the simulation. GameNGen is trained in two phases: (1) an RL-agent learns to play the game and the training sessions are recorded, and (2) a diffusion model is trained to produce the next frame, conditioned on the sequence of past frames and actions. Conditioning augmentations enable stable auto-regressive generation over long trajectories.
PALP: Prompt Aligned Personalization of Text-to-Image Models
Jan 11, 2024



Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally, they may want the resulting image to encompass a specific location, style, ambiance, and more. Existing personalization methods may compromise personalization ability or the alignment to complex textual prompts. This trade-off can impede the fulfillment of user prompts and subject fidelity. We propose a new approach focusing on personalization methods for a \emph{single} prompt to address this issue. We term our approach prompt-aligned personalization. While this may seem restrictive, our method excels in improving text alignment, enabling the creation of images with complex and intricate prompts, which may pose a challenge for current techniques. In particular, our method keeps the personalized model aligned with a target prompt using an additional score distillation sampling term. We demonstrate the versatility of our method in multi- and single-shot settings and further show that it can compose multiple subjects or use inspiration from reference images, such as artworks. We compare our approach quantitatively and qualitatively with existing baselines and state-of-the-art techniques.
AnyLens: A Generative Diffusion Model with Any Rendering Lens
Nov 29, 2023State-of-the-art diffusion models can generate highly realistic images based on various conditioning like text, segmentation, and depth. However, an essential aspect often overlooked is the specific camera geometry used during image capture. The influence of different optical systems on the final scene appearance is frequently overlooked. This study introduces a framework that intimately integrates a text-to-image diffusion model with the particular lens geometry used in image rendering. Our method is based on a per-pixel coordinate conditioning method, enabling the control over the rendering geometry. Notably, we demonstrate the manipulation of curvature properties, achieving diverse visual effects, such as fish-eye, panoramic views, and spherical texturing using a single diffusion model.
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
Nov 27, 2023



Recent advances in text-to-image generation models have unlocked vast potential for visual creativity. However, these models struggle with generation of consistent characters, a crucial aspect for numerous real-world applications such as story visualization, game development asset design, advertising, and more. Current methods typically rely on multiple pre-existing images of the target character or involve labor-intensive manual processes. In this work, we propose a fully automated solution for consistent character generation, with the sole input being a text prompt. We introduce an iterative procedure that, at each stage, identifies a coherent set of images sharing a similar identity and extracts a more consistent identity from this set. Our quantitative analysis demonstrates that our method strikes a better balance between prompt alignment and identity consistency compared to the baseline methods, and these findings are reinforced by a user study. To conclude, we showcase several practical applications of our approach. Project page is available at https://omriavrahami.com/the-chosen-one
Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models
Jul 13, 2023Text-to-image (T2I) personalization allows users to guide the creative image generation process by combining their own visual concepts in natural language prompts. Recently, encoder-based techniques have emerged as a new effective approach for T2I personalization, reducing the need for multiple images and long training times. However, most existing encoders are limited to a single-class domain, which hinders their ability to handle diverse concepts. In this work, we propose a domain-agnostic method that does not require any specialized dataset or prior information about the personalized concepts. We introduce a novel contrastive-based regularization technique to maintain high fidelity to the target concept characteristics while keeping the predicted embeddings close to editable regions of the latent space, by pushing the predicted tokens toward their nearest existing CLIP tokens. Our experimental results demonstrate the effectiveness of our approach and show how the learned tokens are more semantic than tokens predicted by unregularized models. This leads to a better representation that achieves state-of-the-art performance while being more flexible than previous methods.
Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models
Mar 05, 2023Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
Single Motion Diffusion
Feb 12, 2023



Synthesizing realistic animations of humans, animals, and even imaginary creatures, has long been a goal for artists and computer graphics professionals. Compared to the imaging domain, which is rich with large available datasets, the number of data instances for the motion domain is limited, particularly for the animation of animals and exotic creatures (e.g., dragons), which have unique skeletons and motion patterns. In this work, we present a Single Motion Diffusion Model, dubbed SinMDM, a model designed to learn the internal motifs of a single motion sequence with arbitrary topology and synthesize motions of arbitrary length that are faithful to them. We harness the power of diffusion models and present a denoising network designed specifically for the task of learning from a single input motion. Our transformer-based architecture avoids overfitting by using local attention layers that narrow the receptive field, and encourages motion diversity by using relative positional embedding. SinMDM can be applied in a variety of contexts, including spatial and temporal in-betweening, motion expansion, style transfer, and crowd animation. Our results show that SinMDM outperforms existing methods both in quality and time-space efficiency. Moreover, while current approaches require additional training for different applications, our work facilitates these applications at inference time. Our code and trained models are available at https://sinmdm.github.io/SinMDM-page.
Learned Queries for Efficient Local Attention
Dec 21, 2021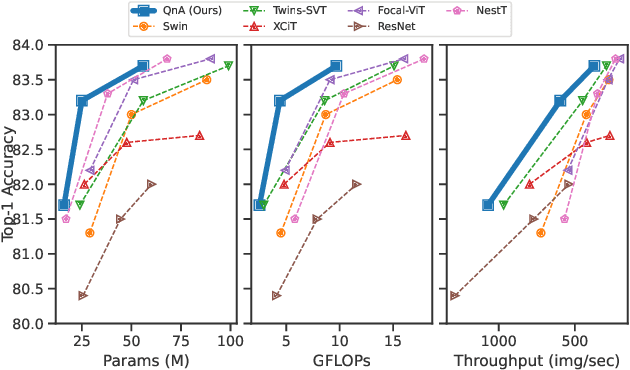
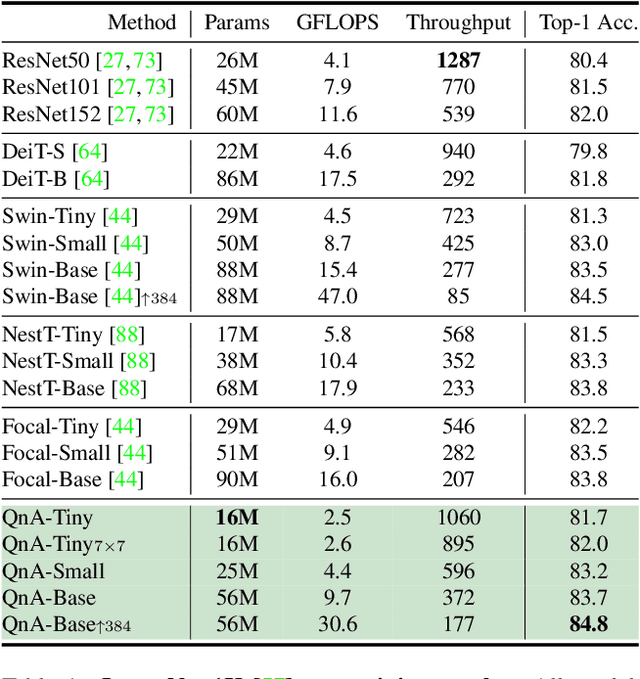
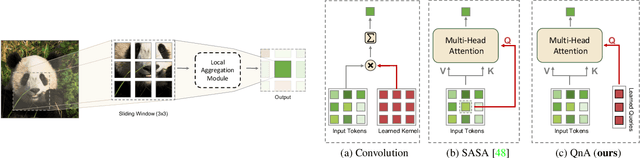
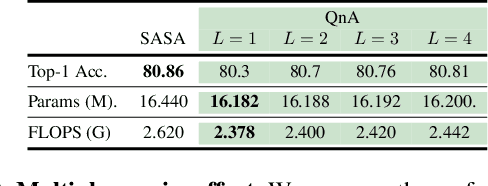
Vision Transformers (ViT) serve as powerful vision models. Unlike convolutional neural networks, which dominated vision research in previous years, vision transformers enjoy the ability to capture long-range dependencies in the data. Nonetheless, an integral part of any transformer architecture, the self-attention mechanism, suffers from high latency and inefficient memory utilization, making it less suitable for high-resolution input images. To alleviate these shortcomings, hierarchical vision models locally employ self-attention on non-interleaving windows. This relaxation reduces the complexity to be linear in the input size; however, it limits the cross-window interaction, hurting the model performance. In this paper, we propose a new shift-invariant local attention layer, called query and attend (QnA), that aggregates the input locally in an overlapping manner, much like convolutions. The key idea behind QnA is to introduce learned queries, which allow fast and efficient implementation. We verify the effectiveness of our layer by incorporating it into a hierarchical vision transformer model. We show improvements in speed and memory complexity while achieving comparable accuracy with state-of-the-art models. Finally, our layer scales especially well with window size, requiring up-to x10 less memory while being up-to x5 faster than existing methods.
InAugment: Improving Classifiers via Internal Augmentation
Apr 08, 2021
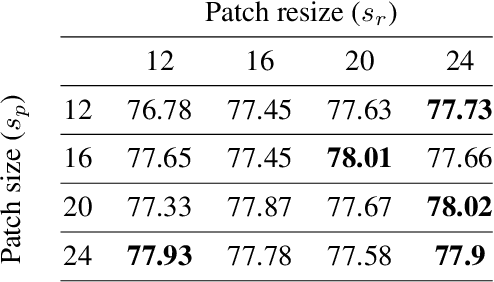
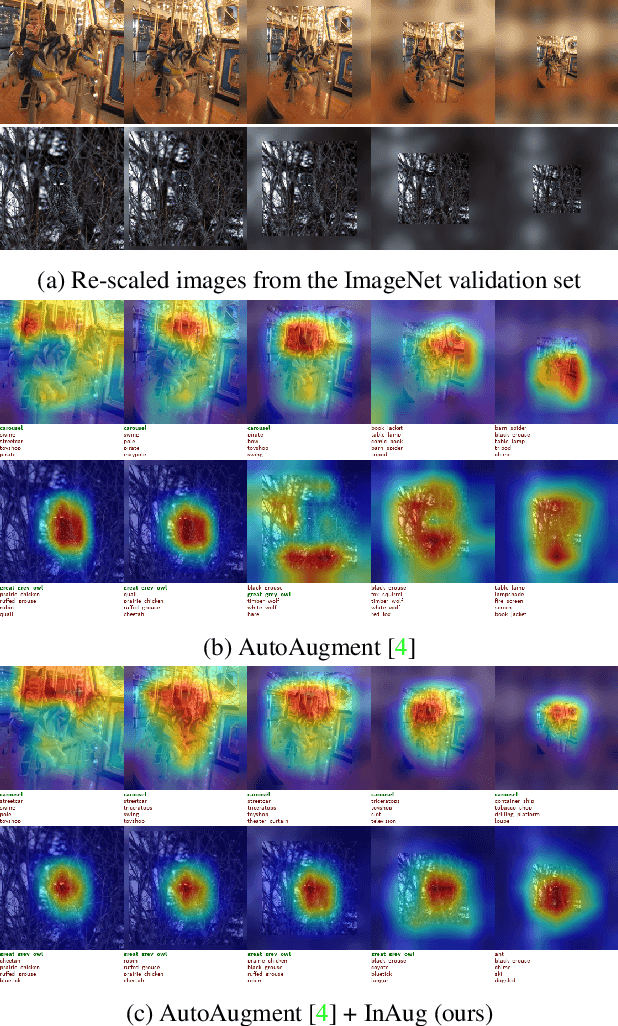

Image augmentation techniques apply transformation functions such as rotation, shearing, or color distortion on an input image. These augmentations were proven useful in improving neural networks' generalization ability. In this paper, we present a novel augmentation operation, InAugment, that exploits image internal statistics. The key idea is to copy patches from the image itself, apply augmentation operations on them, and paste them back at random positions on the same image. This method is simple and easy to implement and can be incorporated with existing augmentation techniques. We test InAugment on two popular datasets -- CIFAR and ImageNet. We show improvement over state-of-the-art augmentation techniques. Incorporating InAugment with Auto Augment yields a significant improvement over other augmentation techniques (e.g., +1% improvement over multiple architectures trained on the CIFAR dataset). We also demonstrate an increase for ResNet50 and EfficientNet-B3 top-1's accuracy on the ImageNet dataset compared to prior augmentation methods. Finally, our experiments suggest that training convolutional neural network using InAugment not only improves the model's accuracy and confidence but its performance on out-of-distribution images.
Focus-and-Expand: Training Guidance Through Gradual Manipulation of Input Features
Jul 15, 2020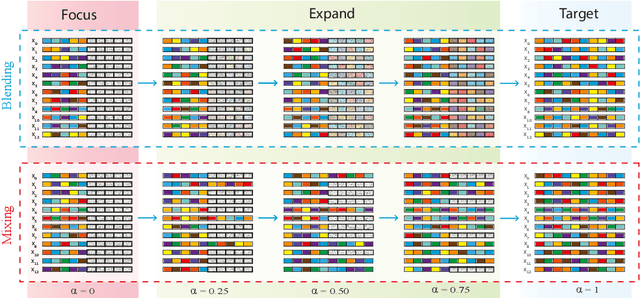
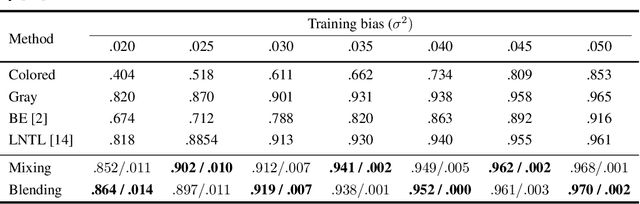

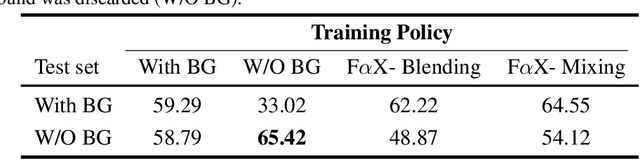
We present a simple and intuitive Focus-and-eXpand (\fax) method to guide the training process of a neural network towards a specific solution. Optimizing a neural network is a highly non-convex problem. Typically, the space of solutions is large, with numerous possible local minima, where reaching a specific minimum depends on many factors. In many cases, however, a solution which considers specific aspects, or features, of the input is desired. For example, in the presence of bias, a solution that disregards the biased feature is a more robust and accurate one. Drawing inspiration from Parameter Continuation methods, we propose steering the training process to consider specific features in the input more than others, through gradual shifts in the input domain. \fax extracts a subset of features from each input data-point, and exposes the learner to these features first, Focusing the solution on them. Then, by using a blending/mixing parameter $\alpha$ it gradually eXpands the learning process to include all features of the input. This process encourages the consideration of the desired features more than others. Though not restricted to this field, we quantitatively evaluate the effectiveness of our approach on various Computer Vision tasks, and achieve state-of-the-art bias removal, improvements to an established augmentation method, and two examples of improvements to image classification tasks. Through these few examples we demonstrate the impact this approach potentially carries for a wide variety of problems, which stand to gain from understanding the solution landscape.