 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICP-Based Pallet Tracking for Unloading on Inclined Surfaces by Autonomous Forklifts
Feb 18, 2026This paper proposes a control method for autonomous forklifts to unload pallets on inclined surfaces, enabling the fork to be withdrawn without dragging the pallets. The proposed method applies the Iterative Closest Point (ICP) algorithm to point clouds measured from the upper region of the pallet and thereby tracks the relative position and attitude angle difference between the pallet and the fork during the unloading operation in real-time. According to the tracking result, the fork is aligned parallel to the target surface. After the fork is aligned, it is possible to complete the unloading process by withdrawing the fork along the tilt, preventing any dragging of the pallet. The effectiveness of the proposed method is verified through dynamic simulations and experiments using a real forklift that replicate unloading operations onto the inclined bed of a truck.
* Accepted and published in IEEE/SICE SII 2024
TACT: Humanoid Whole-body Contact Manipulation through Deep Imitation Learning with Tactile Modality
Jun 18, 2025Manipulation with whole-body contact by humanoid robots offers distinct advantages, including enhanced stability and reduced load. On the other hand, we need to address challenges such as the increased computational cost of motion generation and the difficulty of measuring broad-area contact. We therefore have developed a humanoid control system that allows a humanoid robot equipped with tactile sensors on its upper body to learn a policy for whole-body manipulation through imitation learning based on human teleoperation data. This policy, named tactile-modality extended ACT (TACT), has a feature to take multiple sensor modalities as input, including joint position, vision, and tactile measurements. Furthermore, by integrating this policy with retargeting and locomotion control based on a biped model, we demonstrate that the life-size humanoid robot RHP7 Kaleido is capable of achieving whole-body contact manipulation while maintaining balance and walking. Through detailed experimental verification, we show that inputting both vision and tactile modalities into the policy contributes to improving the robustness of manipulation involving broad and delicate contact.
Humanoid Loco-Manipulations Pattern Generation and Stabilization Control
May 30, 2025



In order for a humanoid robot to perform loco-manipulation such as moving an object while walking, it is necessary to account for sustained or alternating external forces other than ground-feet reaction, resulting from humanoid-object contact interactions. In this letter, we propose a bipedal control strategy for humanoid loco-manipulation that can cope with such external forces. First, the basic formulas of the bipedal dynamics, i.e., linear inverted pendulum mode and divergent component of motion, are derived, taking into account the effects of external manipulation forces. Then, we propose a pattern generator to plan center of mass trajectories consistent with the reference trajectory of the manipulation forces, and a stabilizer to compensate for the error between desired and actual manipulation forces. The effectiveness of our controller is assessed both in simulation and loco-manipulation experiments with real humanoid robots.
Centroidal Trajectory Generation and Stabilization based on Preview Control for Humanoid Multi-contact Motion
May 29, 2025



Multi-contact motion is important for humanoid robots to work in various environments. We propose a centroidal online trajectory generation and stabilization control for humanoid dynamic multi-contact motion. The proposed method features the drastic reduction of the computational cost by using preview control instead of the conventional model predictive control that considers the constraints of all sample times. By combining preview control with centroidal state feedback for robustness to disturbances and wrench distribution for satisfying contact constraints, we show that the robot can stably perform a variety of multi-contact motions through simulation experiments.
Humanoid Loco-manipulation Planning based on Graph Search and Reachability Maps
May 29, 2025In this letter, we propose an efficient and highly versatile loco-manipulation planning for humanoid robots. Loco-manipulation planning is a key technological brick enabling humanoid robots to autonomously perform object transportation by manipulating them. We formulate planning of the alternation and sequencing of footsteps and grasps as a graph search problem with a new transition model that allows for a flexible representation of loco-manipulation. Our transition model is quickly evaluated by relocating and switching the reachability maps depending on the motion of both the robot and object. We evaluate our approach by applying it to loco-manipulation use-cases, such as a bobbin rolling operation with regrasping, where the motion is automatically planned by our framework.
Whole-body Multi-contact Motion Control for Humanoid Robots Based on Distributed Tactile Sensors
May 26, 2025



To enable humanoid robots to work robustly in confined environments, multi-contact motion that makes contacts not only at extremities, such as hands and feet, but also at intermediate areas of the limbs, such as knees and elbows, is essential. We develop a method to realize such whole-body multi-contact motion involving contacts at intermediate areas by a humanoid robot. Deformable sheet-shaped distributed tactile sensors are mounted on the surface of the robot's limbs to measure the contact force without significantly changing the robot body shape. The multi-contact motion controller developed earlier, which is dedicated to contact at extremities, is extended to handle contact at intermediate areas, and the robot motion is stabilized by feedback control using not only force/torque sensors but also distributed tactile sensors. Through verification on dynamics simulations, we show that the developed tactile feedback improves the stability of whole-body multi-contact motion against disturbances and environmental errors. Furthermore, the life-sized humanoid RHP Kaleido demonstrates whole-body multi-contact motions, such as stepping forward while supporting the body with forearm contact and balancing in a sitting posture with thigh contacts.
Robust Humanoid Walking on Compliant and Uneven Terrain with Deep Reinforcement Learning
Apr 18, 2025For the deployment of legged robots in real-world environments, it is essential to develop robust locomotion control methods for challenging terrains that may exhibit unexpected deformability and irregularity. In this paper, we explore the application of sim-to-real deep reinforcement learning (RL) for the design of bipedal locomotion controllers for humanoid robots on compliant and uneven terrains. Our key contribution is to show that a simple training curriculum for exposing the RL agent to randomized terrains in simulation can achieve robust walking on a real humanoid robot using only proprioceptive feedback. We train an end-to-end bipedal locomotion policy using the proposed approach, and show extensive real-robot demonstration on the HRP-5P humanoid over several difficult terrains inside and outside the lab environment. Further, we argue that the robustness of a bipedal walking policy can be improved if the robot is allowed to exhibit aperiodic motion with variable stepping frequency. We propose a new control policy to enable modification of the observed clock signal, leading to adaptive gait frequencies depending on the terrain and command velocity. Through simulation experiments, we show the effectiveness of this policy specifically for walking over challenging terrains by controlling swing and stance durations. The code for training and evaluation is available online at https://github.com/rohanpsingh/LearningHumanoidWalking. Demo video is available at https://www.youtube.com/watch?v=ZgfNzGAkk2Q.
Humanoid Robot RHP Friends: Seamless Combination of Autonomous and Teleoperated Tasks in a Nursing Context
Dec 30, 2024



This paper describes RHP Friends, a social humanoid robot developed to enable assistive robotic deployments in human-coexisting environments. As a use-case application, we present its potential use in nursing by extending its capabilities to operate human devices and tools according to the task and by enabling remote assistance operations. To meet a wide variety of tasks and situations in environments designed by and for humans, we developed a system that seamlessly integrates the slim and lightweight robot and several technologies: locomanipulation, multi-contact motion, teleoperation, and object detection and tracking. We demonstrated the system's usage in a nursing application. The robot efficiently performed the daily task of patient transfer and a non-routine task, represented by a request to operate a circuit breaker. This demonstration, held at the 2023 International Robot Exhibition (IREX), conducted three times a day over three days.
Learning Bipedal Walking On Planned Footsteps For Humanoid Robots
Jul 26, 2022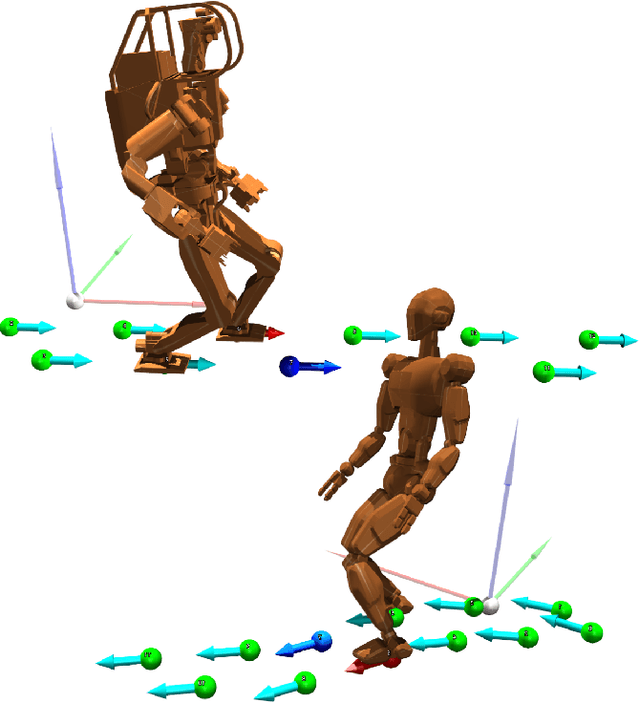
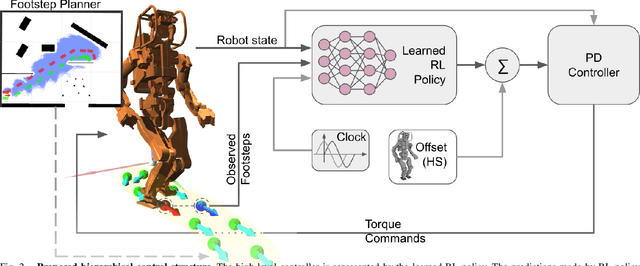
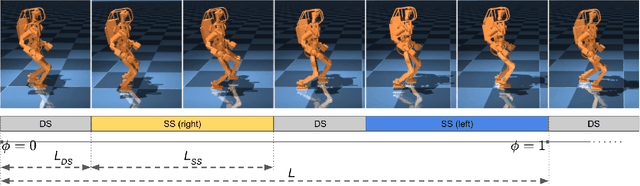
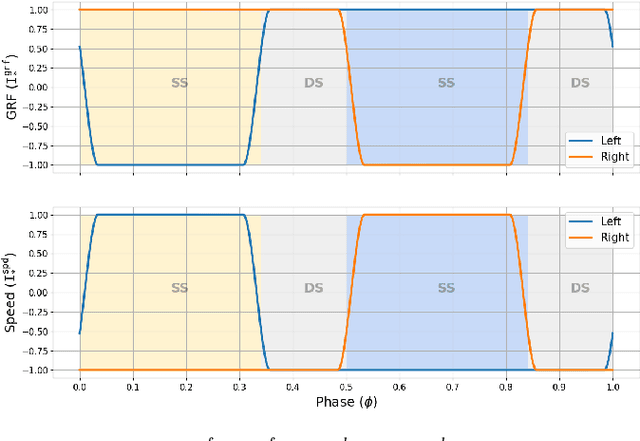
Deep reinforcement learning (RL) based controllers for legged robots have demonstrated impressive robustness for walking in different environments for several robot platforms. To enable the application of RL policies for humanoid robots in real-world settings, it is crucial to build a system that can achieve robust walking in any direction, on 2D and 3D terrains, and be controllable by a user-command. In this paper, we tackle this problem by learning a policy to follow a given step sequence. The policy is trained with the help of a set of procedurally generated step sequences (also called footstep plans). We show that simply feeding the upcoming 2 steps to the policy is sufficient to achieve omnidirectional walking, turning in place, standing, and climbing stairs. Our method employs curriculum learning on the complexity of terrains, and circumvents the need for reference motions or pre-trained weights. We demonstrate the application of our proposed method to learn RL policies for 2 new robot platforms - HRP5P and JVRC-1 - in the MuJoCo simulation environment. The code for training and evaluation is available online.
Lyapunov-Stable Orientation Estimator for Humanoid Robots
Oct 09, 2020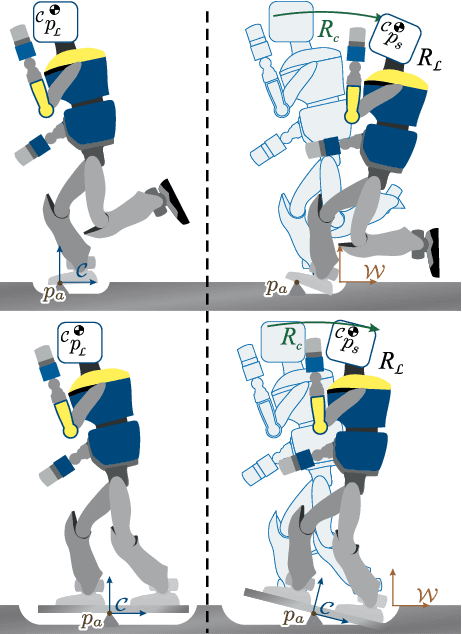
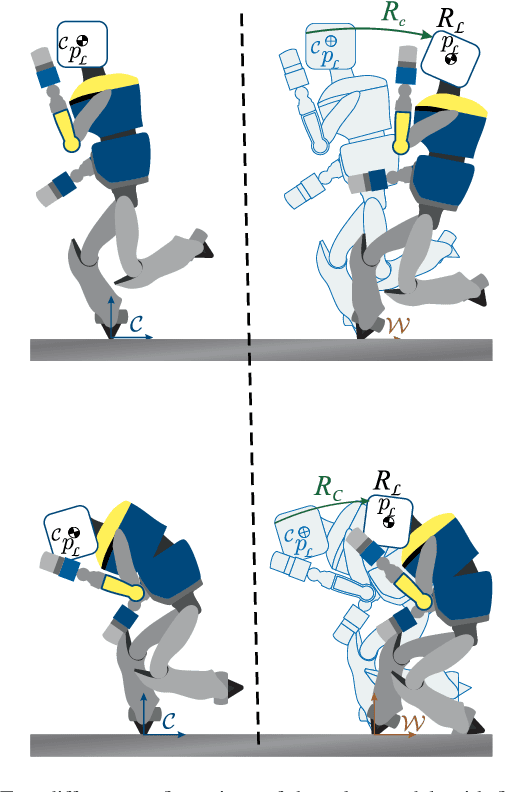
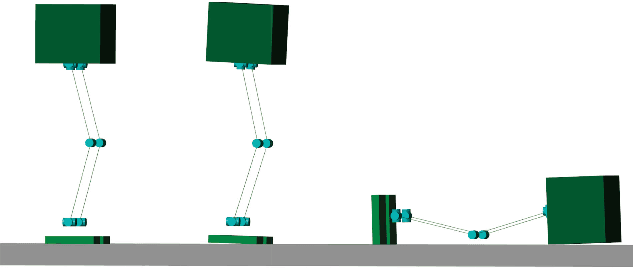
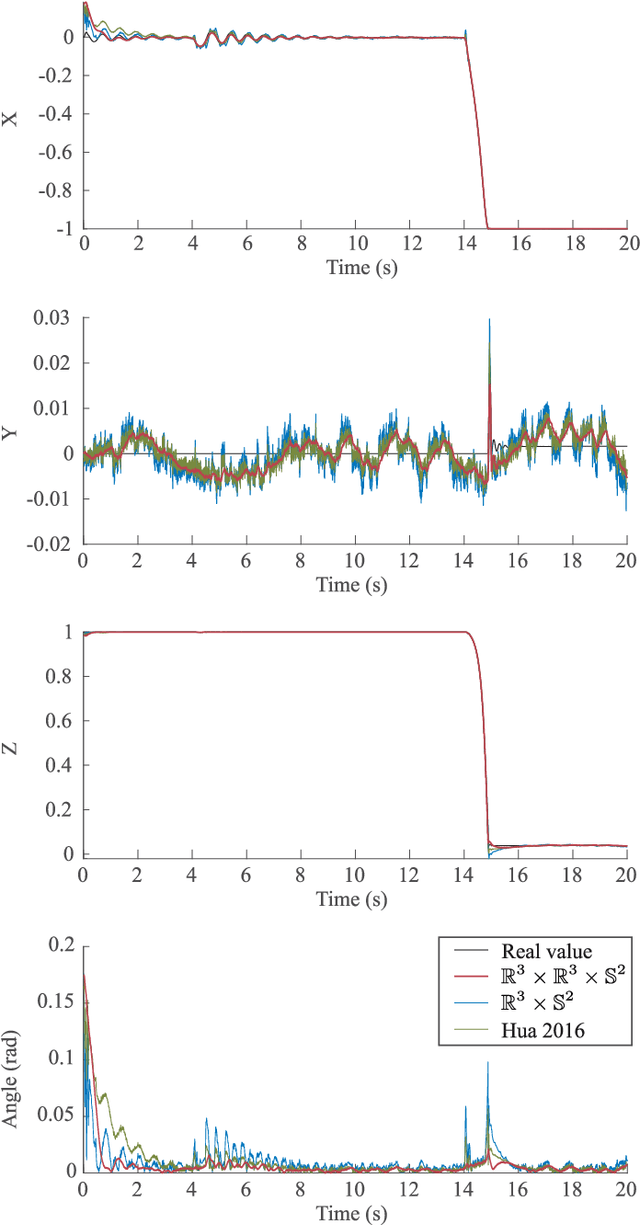
In this paper, we present an observation scheme, with proven Lyapunov stability, for estimating a humanoid's floating base orientation. The idea is to use velocity aided attitude estimation, which requires to know the velocity of the system. This velocity can be obtained by taking into account the kinematic data provided by contact information with the environment and using the IMU and joint encoders. We demonstrate how this operation can be used in the case of a fixed or a moving contact, allowing it to be employed for locomotion. We show how to use this velocity estimation within a selected two-stage state tilt estimator: (i) the first which has a global and quick convergence (ii) and the second which has smooth and robust dynamics. We provide new specific proofs of almost global Lyapunov asymptotic stability and local exponential convergence for this observer. Finally, we assess its performance by employing a comparative simulation and by using it within a closed-loop stabilization scheme for HRP-5P and HRP-2KAI robots performing whole-body kinematic tasks and locomotion.