 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Recommendation Reasoning through Knowledge Graphs for Explanation Path Quality
Sep 11, 2022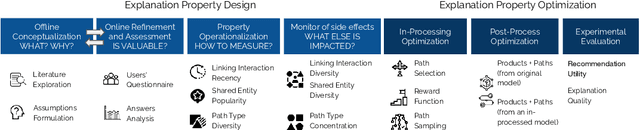

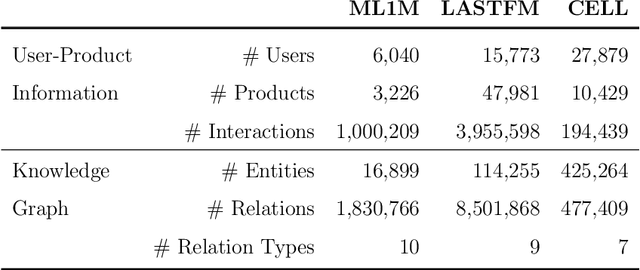

Numerous Knowledge Graphs (KGs) are being created to make recommender systems not only intelligent but also knowledgeable. Reinforcement recommendation reasoning is a recent approach able to model high-order user-product relations, according to the KG. This type of approach makes it possible to extract reasoning paths between the recommended product and already experienced products. These paths can be in turn translated into textual explanations to be provided to the user for a given recommendation. However, none of the existing approaches has investigated user-level properties of a single or a group of reasoning paths. In this paper, we propose a series of quantitative properties that monitor the quality of the reasoning paths, based on recency, popularity, and diversity. We then combine in- and post-processing approaches to optimize for both recommendation quality and reasoning path quality. Experiments on three public data sets show that our approaches significantly increase reasoning path quality according to the proposed properties, while preserving recommendation quality. Source code, data sets, and KGs are available at https://tinyurl.com/bdbfzr4n.
Explaining Bias in Deep Face Recognition via Image Characteristics
Aug 23, 2022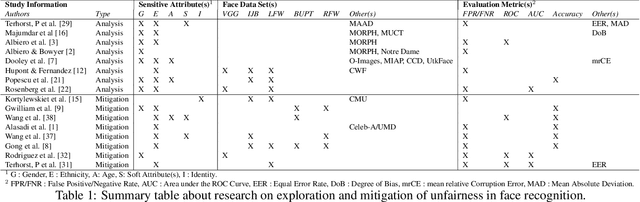
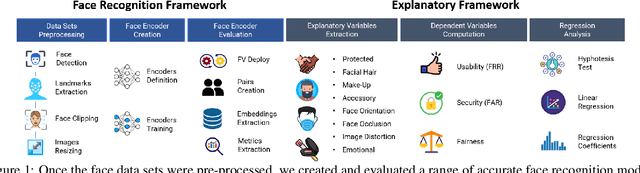

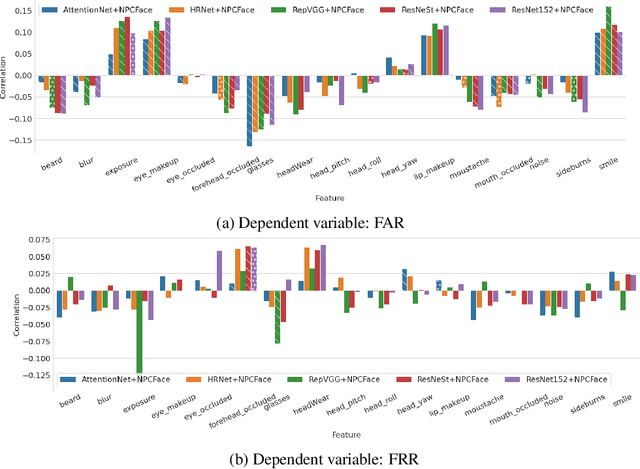
In this paper, we propose a novel explanatory framework aimed to provide a better understanding of how face recognition models perform as the underlying data characteristics (protected attributes: gender, ethnicity, age; non-protected attributes: facial hair, makeup, accessories, face orientation and occlusion, image distortion, emotions) on which they are tested change. With our framework, we evaluate ten state-of-the-art face recognition models, comparing their fairness in terms of security and usability on two data sets, involving six groups based on gender and ethnicity. We then analyze the impact of image characteristics on models performance. Our results show that trends appearing in a single-attribute analysis disappear or reverse when multi-attribute groups are considered, and that performance disparities are also related to non-protected attributes. Source code: https://cutt.ly/2XwRLiA.
Generalisable Methods for Early Prediction in Interactive Simulations for Education
Jul 04, 2022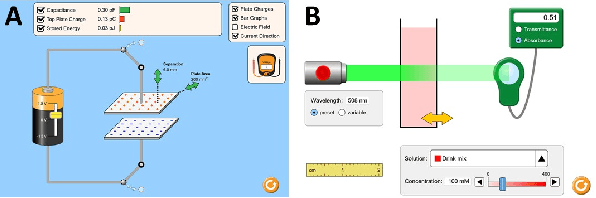
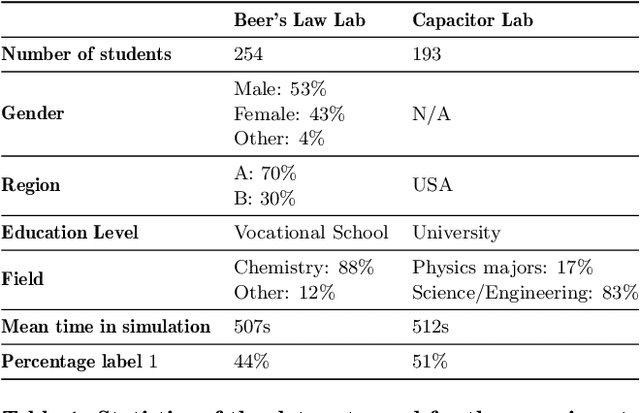
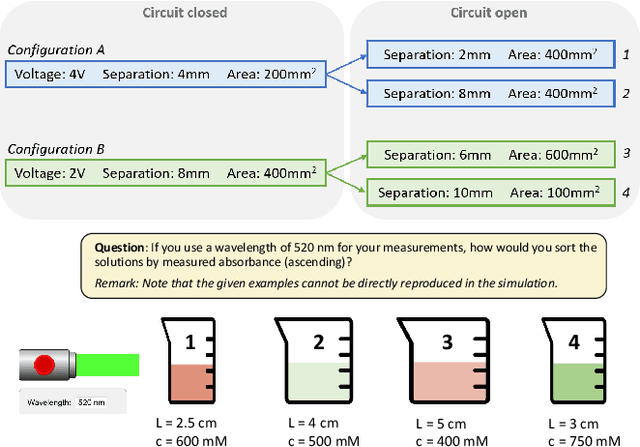
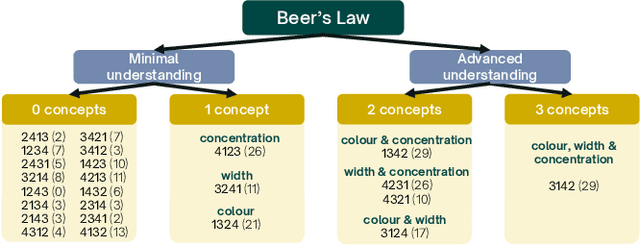
Interactive simulations allow students to discover the underlying principles of a scientific phenomenon through their own exploration. Unfortunately, students often struggle to learn effectively in these environments. Classifying students' interaction data in the simulations based on their expected performance has the potential to enable adaptive guidance and consequently improve students' learning. Previous research in this field has mainly focused on a-posteriori analyses or investigations limited to one specific predictive model and simulation. In this paper, we investigate the quality and generalisability of models for an early prediction of conceptual understanding based on clickstream data of students across interactive simulations. We first measure the students' conceptual understanding through their in-task performance. Then, we suggest a novel type of features that, starting from clickstream data, encodes both the state of the simulation and the action performed by the student. We finally propose to feed these features into GRU-based models, with and without attention, for prediction. Experiments on two different simulations and with two different populations show that our proposed models outperform shallow learning baselines and better generalise to different learning environments and populations. The inclusion of attention into the model increases interpretability in terms of effective inquiry. The source code is available on Github (https://github.com/epfl-ml4ed/beerslaw-lab.git).
Evaluating the Explainers: Black-Box Explainable Machine Learning for Student Success Prediction in MOOCs
Jul 01, 2022
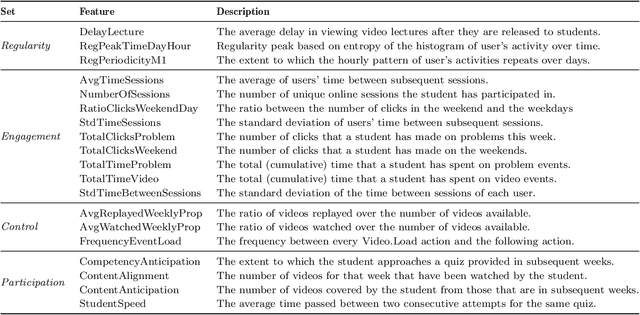

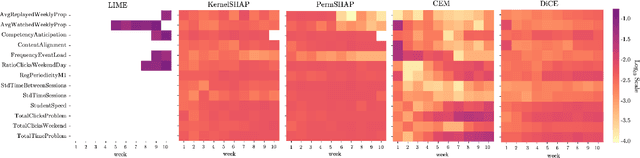
Neural networks are ubiquitous in applied machine learning for education. Their pervasive success in predictive performance comes alongside a severe weakness, the lack of explainability of their decisions, especially relevant in human-centric fields. We implement five state-of-the-art methodologies for explaining black-box machine learning models (LIME, PermutationSHAP, KernelSHAP, DiCE, CEM) and examine the strengths of each approach on the downstream task of student performance prediction for five massive open online courses. Our experiments demonstrate that the families of explainers do not agree with each other on feature importance for the same Bidirectional LSTM models with the same representative set of students. We use Principal Component Analysis, Jensen-Shannon distance, and Spearman's rank-order correlation to quantitatively cross-examine explanations across methods and courses. Furthermore, we validate explainer performance across curriculum-based prerequisite relationships. Our results come to the concerning conclusion that the choice of explainer is an important decision and is in fact paramount to the interpretation of the predictive results, even more so than the course the model is trained on. Source code and models are released at http://github.com/epfl-ml4ed/evaluating-explainers.
Experts' View on Challenges and Needs for Fairness in Artificial Intelligence for Education
Jun 23, 2022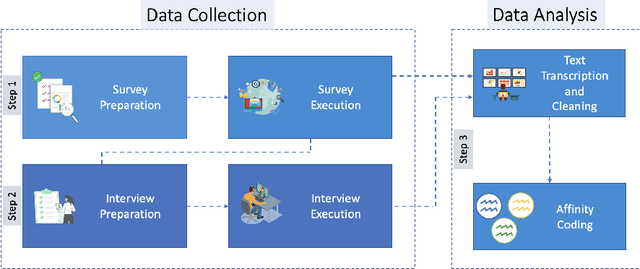
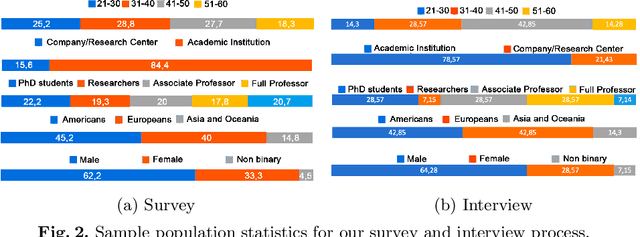
In recent years, there has been a stimulating discussion on how artificial intelligence (AI) can support the science and engineering of intelligent educational applications. Many studies in the field are proposing actionable data mining pipelines and machine-learning models driven by learning-related data. The potential of these pipelines and models to amplify unfairness for certain categories of students is however receiving increasing attention. If AI applications are to have a positive impact on education, it is crucial that their design considers fairness at every step. Through anonymous surveys and interviews with experts (researchers and practitioners) who have published their research at top-tier educational conferences in the last year, we conducted the first expert-driven systematic investigation on the challenges and needs for addressing fairness throughout the development of educational systems based on AI. We identified common and diverging views about the challenges and the needs faced by educational technologies experts in practice, that lead the community to have a clear understanding on the main questions raising doubts in this topic. Based on these findings, we highlighted directions that will facilitate the ongoing research towards fairer AI for education.
Meta Transfer Learning for Early Success Prediction in MOOCs
Apr 25, 2022
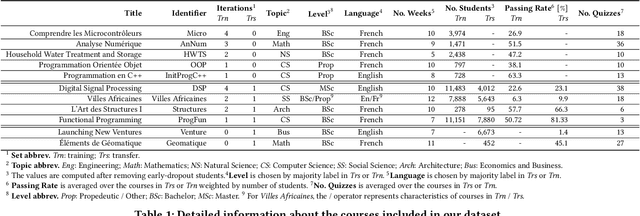
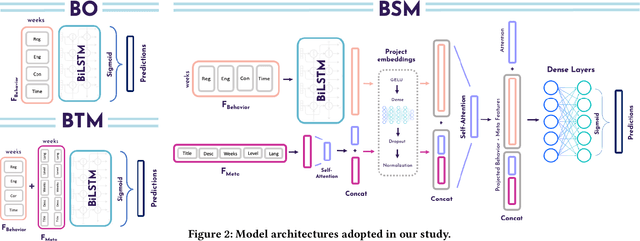
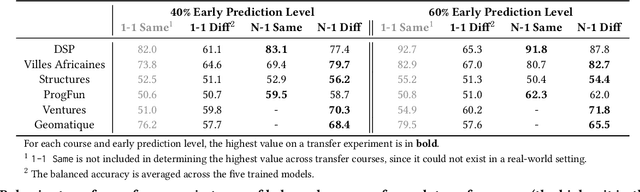
Despite the increasing popularity of massive open online courses (MOOCs), many suffer from high dropout and low success rates. Early prediction of student success for targeted intervention is therefore essential to ensure no student is left behind in a course. There exists a large body of research in success prediction for MOOCs, focusing mainly on training models from scratch for individual courses. This setting is impractical in early success prediction as the performance of a student is only known at the end of the course. In this paper, we aim to create early success prediction models that can be transferred between MOOCs from different domains and topics. To do so, we present three novel strategies for transfer: 1) pre-training a model on a large set of diverse courses, 2) leveraging the pre-trained model by including meta information about courses, and 3) fine-tuning the model on previous course iterations. Our experiments on 26 MOOCs with over 145,000 combined enrollments and millions of interactions show that models combining interaction data and course information have comparable or better performance than models which have access to previous iterations of the course. With these models, we aim to effectively enable educators to warm-start their predictions for new and ongoing courses.
Dictionary Attacks on Speaker Verification
Apr 24, 2022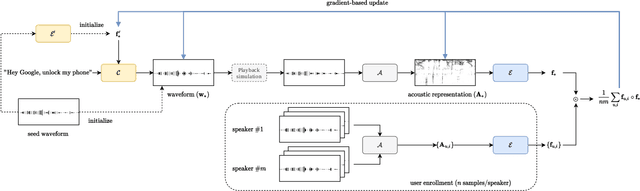
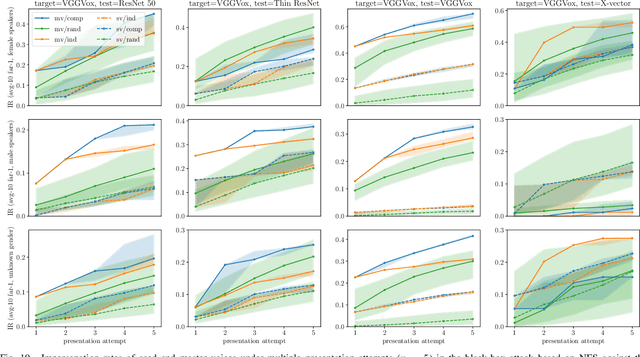

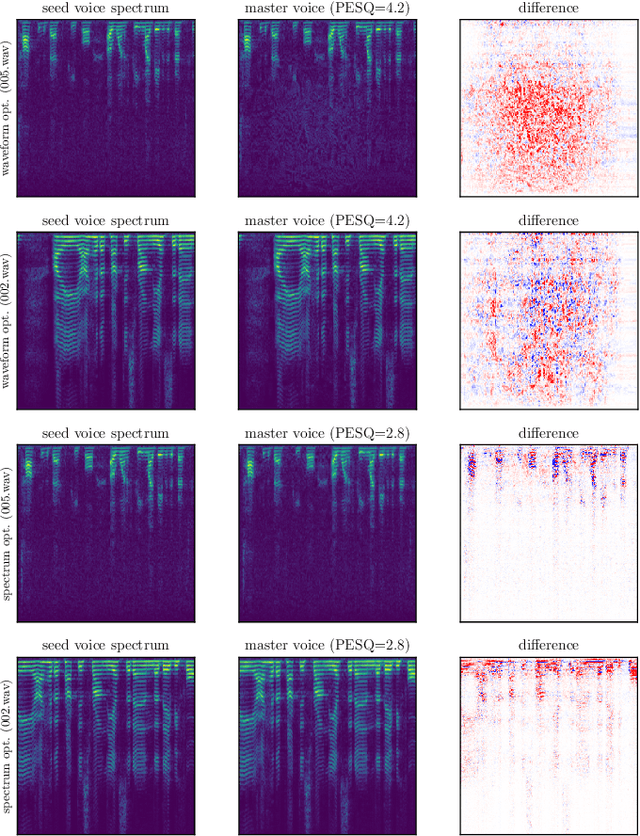
In this paper, we propose dictionary attacks against speaker verification - a novel attack vector that aims to match a large fraction of speaker population by chance. We introduce a generic formulation of the attack that can be used with various speech representations and threat models. The attacker uses adversarial optimization to maximize raw similarity of speaker embeddings between a seed speech sample and a proxy population. The resulting master voice successfully matches a non-trivial fraction of people in an unknown population. Adversarial waveforms obtained with our approach can match on average 69% of females and 38% of males enrolled in the target system at a strict decision threshold calibrated to yield false alarm rate of 1%. By using the attack with a black-box voice cloning system, we obtain master voices that are effective in the most challenging conditions and transferable between speaker encoders. We also show that, combined with multiple attempts, this attack opens even more to serious issues on the security of these systems.
Regulating Group Exposure for Item Providers in Recommendation
Apr 24, 2022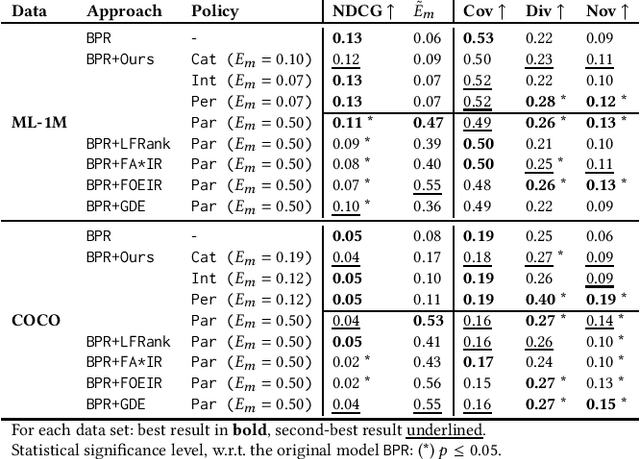
Engaging all content providers, including newcomers or minority demographic groups, is crucial for online platforms to keep growing and working. Hence, while building recommendation services, the interests of those providers should be valued. In this paper, we consider providers as grouped based on a common characteristic in settings in which certain provider groups have low representation of items in the catalog and, thus, in the user interactions. Then, we envision a scenario wherein platform owners seek to control the degree of exposure to such groups in the recommendation process. To support this scenario, we rely on disparate exposure measures that characterize the gap between the share of recommendations given to groups and the target level of exposure pursued by the platform owners. We then propose a re-ranking procedure that ensures desired levels of exposure are met. Experiments show that, while supporting certain groups of providers by rendering them with the target exposure, beyond-accuracy objectives experience significant gains with negligible impact in recommendation utility.
Post Processing Recommender Systems with Knowledge Graphs for Recency, Popularity, and Diversity of Explanations
Apr 24, 2022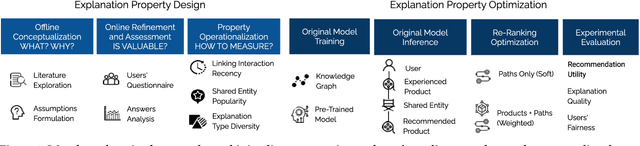
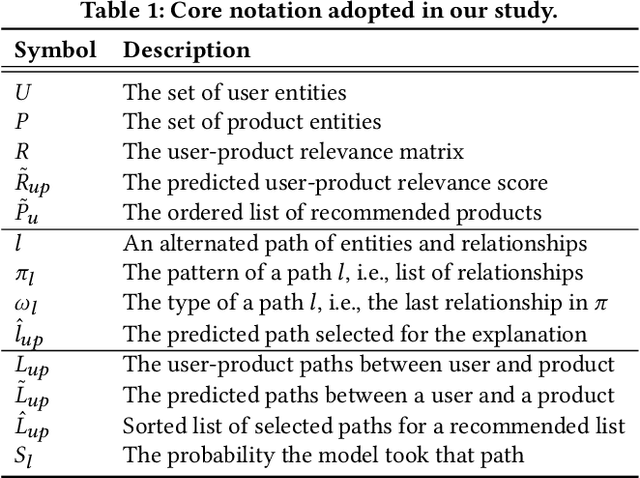
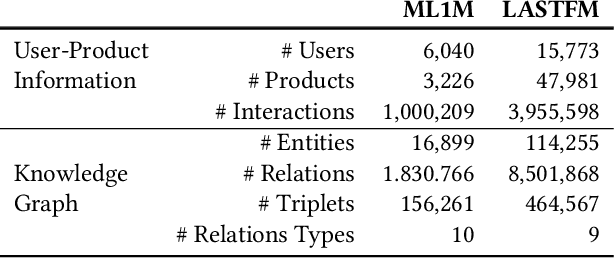
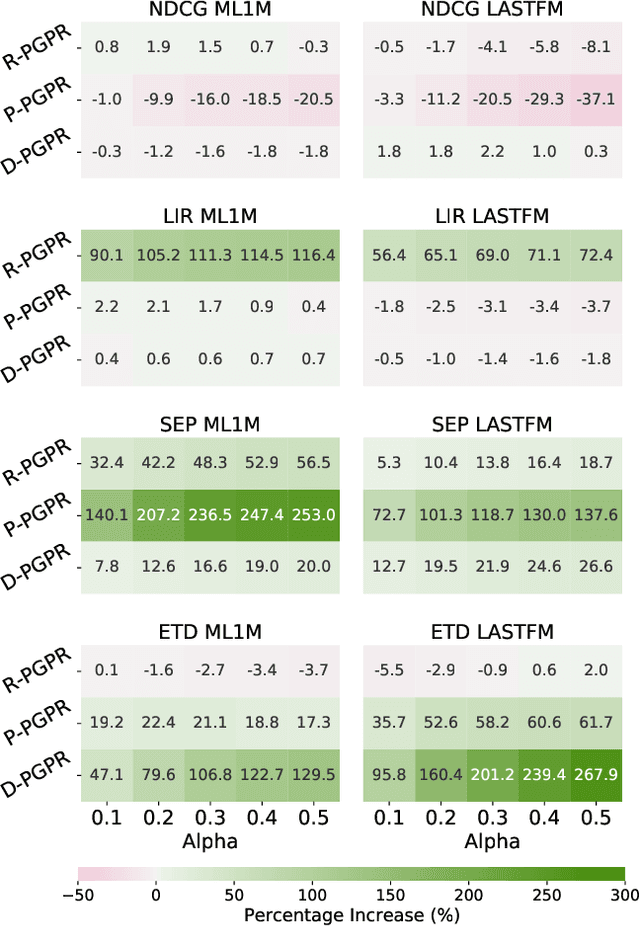
Existing explainable recommender systems have mainly modeled relationships between recommended and already experienced products, and shaped explanation types accordingly (e.g., movie "x" starred by actress "y" recommended to a user because that user watched other movies with "y" as an actress). However, none of these systems has investigated the extent to which properties of a single explanation (e.g., the recency of interaction with that actress) and of a group of explanations for a recommended list (e.g., the diversity of the explanation types) can influence the perceived explaination quality. In this paper, we conceptualized three novel properties that model the quality of the explanations (linking interaction recency, shared entity popularity, and explanation type diversity) and proposed re-ranking approaches able to optimize for these properties. Experiments on two public data sets showed that our approaches can increase explanation quality according to the proposed properties, fairly across demographic groups, while preserving recommendation utility. The source code and data are available at https://github.com/giacoballoccu/explanation-quality-recsys.
Robust Reputation Independence in Ranking Systems for Multiple Sensitive Attributes
Mar 30, 2022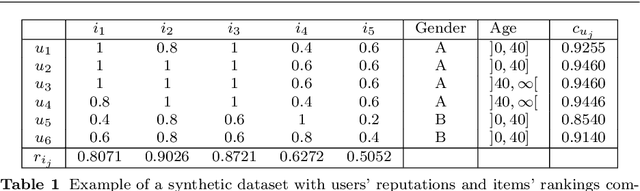

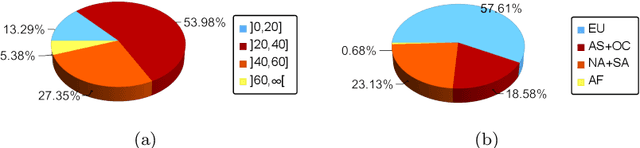
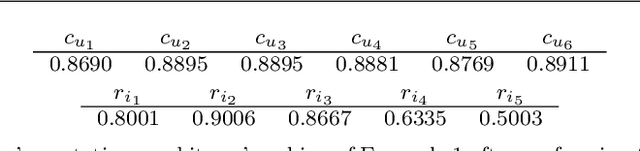
Ranking systems have an unprecedented influence on how and what information people access, and their impact on our society is being analyzed from different perspectives, such as users' discrimination. A notable example is represented by reputation-based ranking systems, a class of systems that rely on users' reputation to generate a non-personalized item-ranking, proved to be biased against certain demographic classes. To safeguard that a given sensitive user's attribute does not systematically affect the reputation of that user, prior work has operationalized a reputation independence constraint on this class of systems. In this paper, we uncover that guaranteeing reputation independence for a single sensitive attribute is not enough. When mitigating biases based on one sensitive attribute (e.g., gender), the final ranking might still be biased against certain demographic groups formed based on another attribute (e.g., age). Hence, we propose a novel approach to introduce reputation independence for multiple sensitive attributes simultaneously. We then analyze the extent to which our approach impacts on discrimination and other important properties of the ranking system, such as its quality and robustness against attacks. Experiments on two real-world datasets show that our approach leads to less biased rankings with respect to multiple users' sensitive attributes, without affecting the system's quality and robustness.