 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Bundle Adjustment for Dynamic 3D Human Reconstruction in the Wild
Jul 24, 2020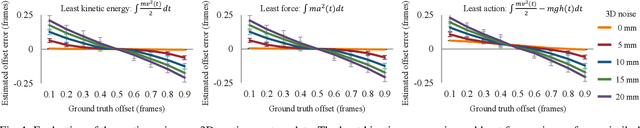

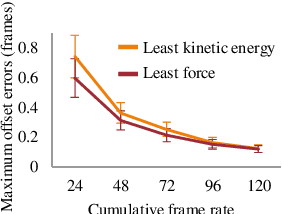
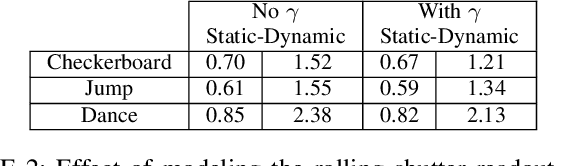
Bundle adjustment jointly optimizes camera intrinsics and extrinsics and 3D point triangulation to reconstruct a static scene. The triangulation constraint, however, is invalid for moving points captured in multiple unsynchronized videos and bundle adjustment is not designed to estimate the temporal alignment between cameras. We present a spatiotemporal bundle adjustment framework that jointly optimizes four coupled sub-problems: estimating camera intrinsics and extrinsics, triangulating static 3D points, as well as sub-frame temporal alignment between cameras and computing 3D trajectories of dynamic points. Key to our joint optimization is the careful integration of physics-based motion priors within the reconstruction pipeline, validated on a large motion capture corpus of human subjects. We devise an incremental reconstruction and alignment algorithm to strictly enforce the motion prior during the spatiotemporal bundle adjustment. This algorithm is further made more efficient by a divide and conquer scheme while still maintaining high accuracy. We apply this algorithm to reconstruct 3D motion trajectories of human bodies in dynamic events captured by multiple uncalibrated and unsynchronized video cameras in the wild. To make the reconstruction visually more interpretable, we fit a statistical 3D human body model to the asynchronous video streams.Compared to the baseline, the fitting significantly benefits from the proposed spatiotemporal bundle adjustment procedure. Because the videos are aligned with sub-frame precision, we reconstruct 3D motion at much higher temporal resolution than the input videos.
Long-term Human Motion Prediction with Scene Context
Jul 07, 2020
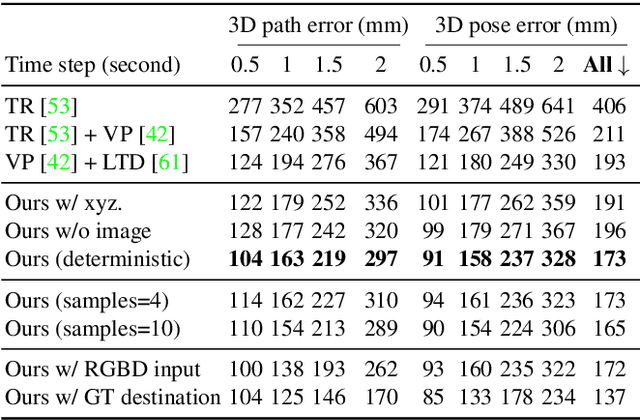
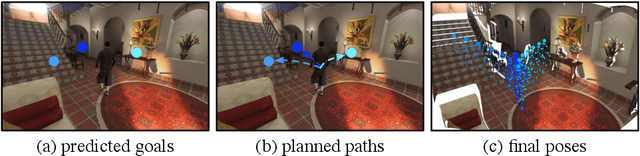
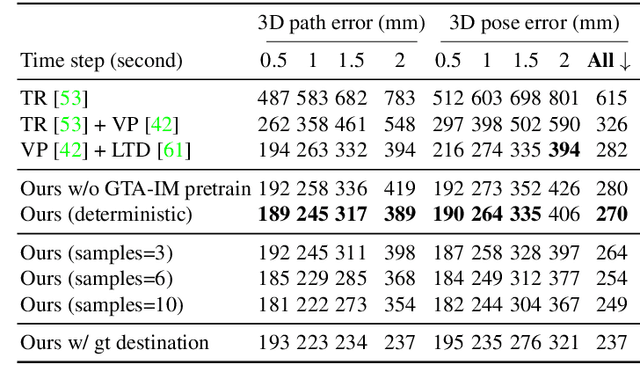
Human movement is goal-directed and influenced by the spatial layout of the objects in the scene. To plan future human motion, it is crucial to perceive the environment -- imagine how hard it is to navigate a new room with lights off. Existing works on predicting human motion do not pay attention to the scene context and thus struggle in long-term prediction. In this work, we propose a novel three-stage framework that exploits scene context to tackle this task. Given a single scene image and 2D pose histories, our method first samples multiple human motion goals, then plans 3D human paths towards each goal, and finally predicts 3D human pose sequences following each path. For stable training and rigorous evaluation, we contribute a diverse synthetic dataset with clean annotations. In both synthetic and real datasets, our method shows consistent quantitative and qualitative improvements over existing methods.
4D Visualization of Dynamic Events from Unconstrained Multi-View Videos
May 27, 2020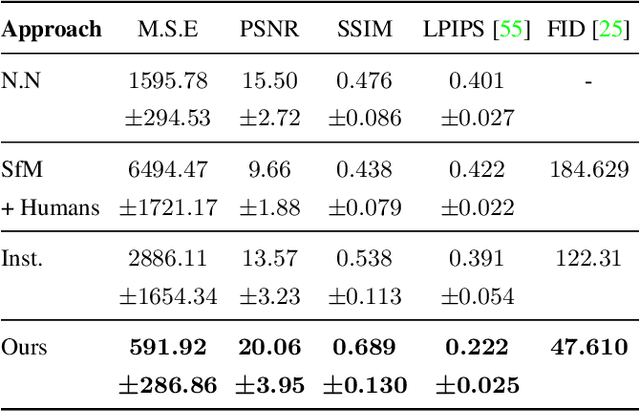



We present a data-driven approach for 4D space-time visualization of dynamic events from videos captured by hand-held multiple cameras. Key to our approach is the use of self-supervised neural networks specific to the scene to compose static and dynamic aspects of an event. Though captured from discrete viewpoints, this model enables us to move around the space-time of the event continuously. This model allows us to create virtual cameras that facilitate: (1) freezing the time and exploring views; (2) freezing a view and moving through time; and (3) simultaneously changing both time and view. We can also edit the videos and reveal occluded objects for a given view if it is visible in any of the other views. We validate our approach on challenging in-the-wild events captured using up to 15 mobile cameras.
Automatic Adaptation of Person Association for Multiview Tracking in Group Activities
May 22, 2018
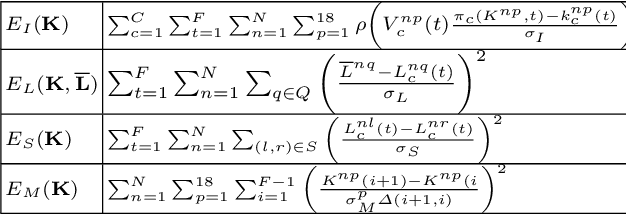


Reliable markerless motion tracking of multiple people participating in complex group activity from multiple handheld cameras is challenging due to frequent occlusions, strong viewpoint and appearance variations, and asynchronous video streams. The key to solving this problem is to reliably associate the same person across distant viewpoint and temporal instances. In this work, we combine motion tracking, mutual exclusion constraints, and multiview geometry in a multitask learning framework to automatically adapt a generic person appearance descriptor to the domain videos. Tracking is formulated as a spatiotemporally constrained clustering using the adapted person descriptor. Physical human constraints are exploited to reconstruct accurate and consistent 3D skeletons for every person across the entire sequence. We show significant improvement in association accuracy (up to 18%) in events with up to 60 people and 3D human skeleton reconstruction (5 to 10 times) over the baseline for events captured "in the wild".