 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Trained Sequential Labeling and Classification by Sparse Attention Neural Networks
Sep 28, 2017
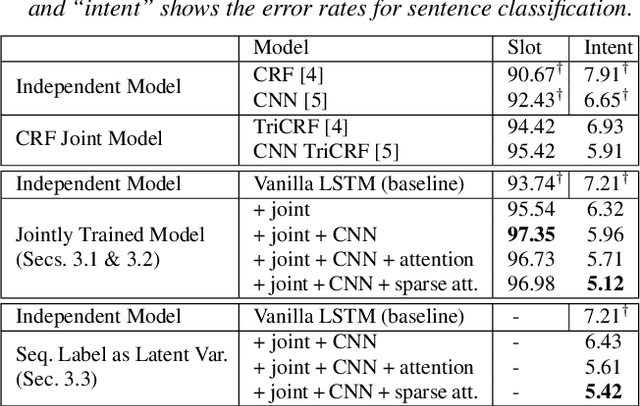
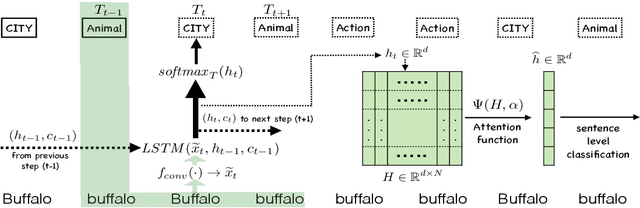
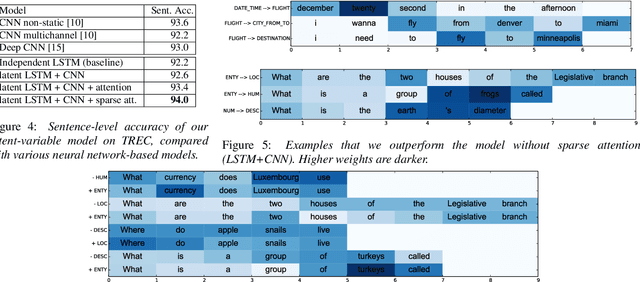
Sentence-level classification and sequential labeling are two fundamental tasks in language understanding. While these two tasks are usually modeled separately, in reality, they are often correlated, for example in intent classification and slot filling, or in topic classification and named-entity recognition. In order to utilize the potential benefits from their correlations, we propose a jointly trained model for learning the two tasks simultaneously via Long Short-Term Memory (LSTM) networks. This model predicts the sentence-level category and the word-level label sequence from the stepwise output hidden representations of LSTM. We also introduce a novel mechanism of "sparse attention" to weigh words differently based on their semantic relevance to sentence-level classification. The proposed method outperforms baseline models on ATIS and TREC datasets.
Textual Entailment with Structured Attentions and Composition
Jan 04, 2017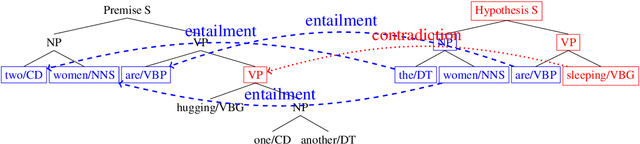
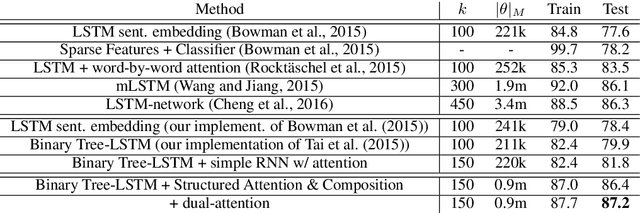
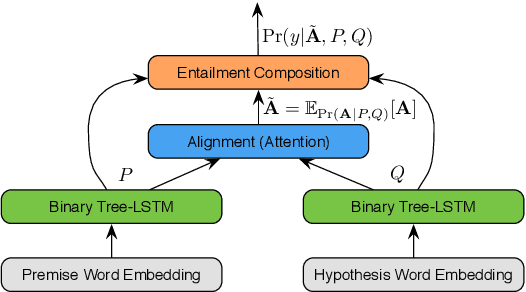
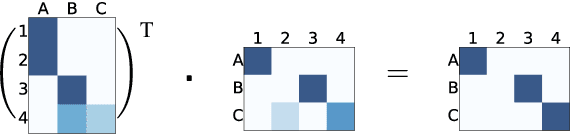
Deep learning techniques are increasingly popular in the textual entailment task, overcoming the fragility of traditional discrete models with hard alignments and logics. In particular, the recently proposed attention models (Rockt\"aschel et al., 2015; Wang and Jiang, 2015) achieves state-of-the-art accuracy by computing soft word alignments between the premise and hypothesis sentences. However, there remains a major limitation: this line of work completely ignores syntax and recursion, which is helpful in many traditional efforts. We show that it is beneficial to extend the attention model to tree nodes between premise and hypothesis. More importantly, this subtree-level attention reveals information about entailment relation. We study the recursive composition of this subtree-level entailment relation, which can be viewed as a soft version of the Natural Logic framework (MacCartney and Manning, 2009). Experiments show that our structured attention and entailment composition model can correctly identify and infer entailment relations from the bottom up, and bring significant improvements in accuracy.
Classify or Select: Neural Architectures for Extractive Document Summarization
Nov 14, 2016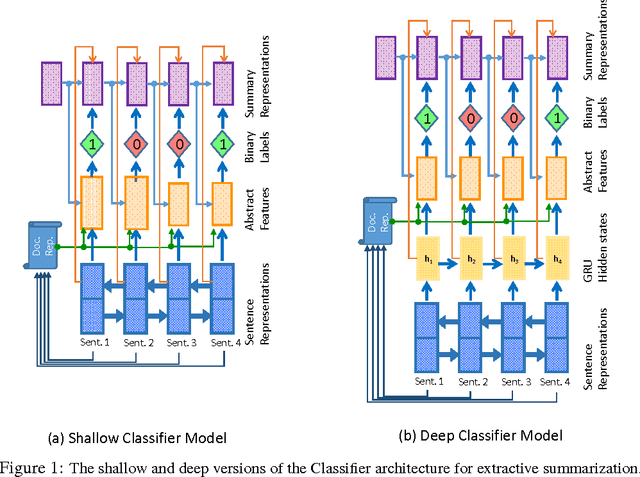

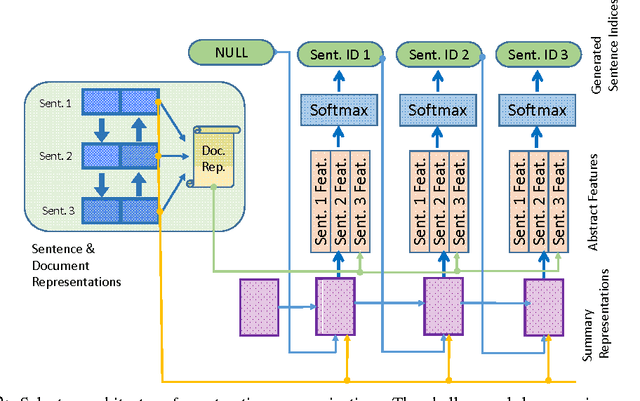
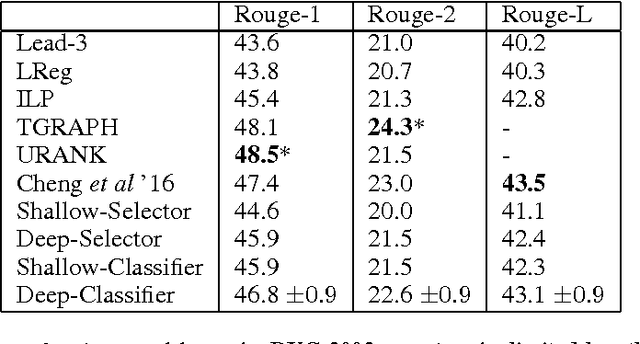
We present two novel and contrasting Recurrent Neural Network (RNN) based architectures for extractive summarization of documents. The Classifier based architecture sequentially accepts or rejects each sentence in the original document order for its membership in the final summary. The Selector architecture, on the other hand, is free to pick one sentence at a time in any arbitrary order to piece together the summary. Our models under both architectures jointly capture the notions of salience and redundancy of sentences. In addition, these models have the advantage of being very interpretable, since they allow visualization of their predictions broken up by abstract features such as information content, salience and redundancy. We show that our models reach or outperform state-of-the-art supervised models on two different corpora. We also recommend the conditions under which one architecture is superior to the other based on experimental evidence.
Dependency-based Convolutional Neural Networks for Sentence Embedding
Aug 03, 2015
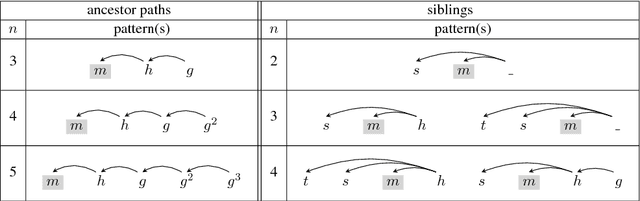
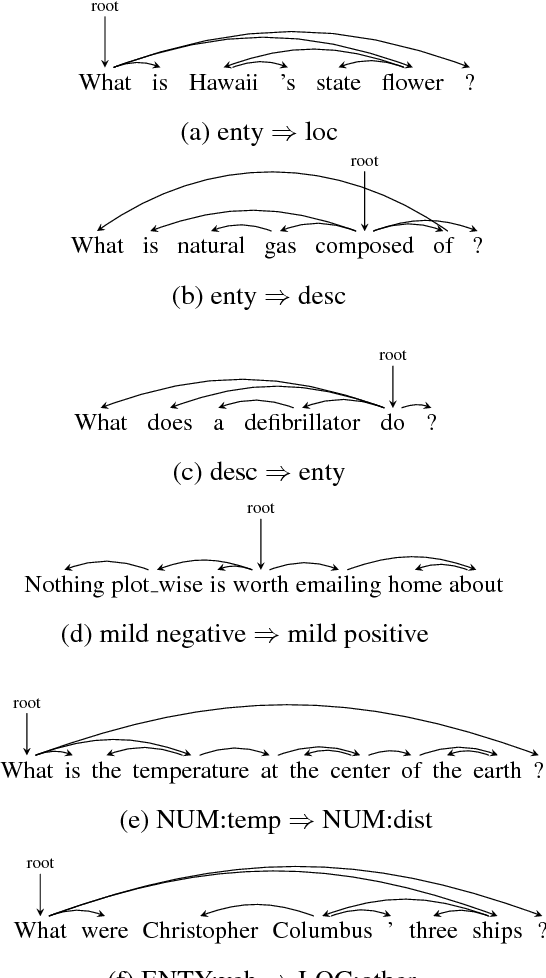
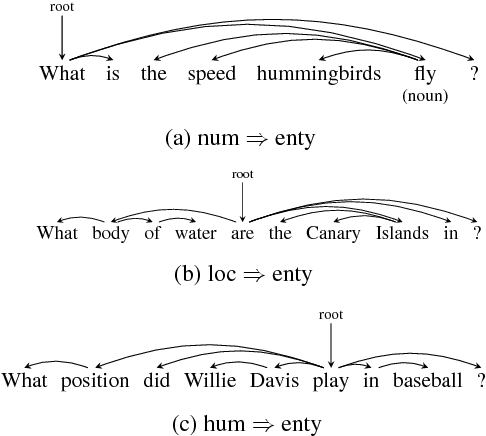
In sentence modeling and classification, convolutional neural network approaches have recently achieved state-of-the-art results, but all such efforts process word vectors sequentially and neglect long-distance dependencies. To exploit both deep learning and linguistic structures, we propose a tree-based convolutional neural network model which exploit various long-distance relationships between words. Our model improves the sequential baselines on all three sentiment and question classification tasks, and achieves the highest published accuracy on TREC.