 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR.FIX: Automatically Fixing Data Races at Industry Scale
Apr 22, 2025



Data races are a prevalent class of concurrency bugs in shared-memory parallel programs, posing significant challenges to software reliability and reproducibility. While there is an extensive body of research on detecting data races and a wealth of practical detection tools across various programming languages, considerably less effort has been directed toward automatically fixing data races at an industrial scale. In large codebases, data races are continuously introduced and exhibit myriad patterns, making automated fixing particularly challenging. In this paper, we tackle the problem of automatically fixing data races at an industrial scale. We present Dr.Fix, a tool that combines large language models (LLMs) with program analysis to generate fixes for data races in real-world settings, effectively addressing a broad spectrum of racy patterns in complex code contexts. Implemented for Go--the programming language widely used in modern microservice architectures where concurrency is pervasive and data races are common--Dr.Fix seamlessly integrates into existing development workflows. We detail the design of Dr.Fix and examine how individual design choices influence the quality of the fixes produced. Over the past 18 months, Dr.Fix has been integrated into developer workflows at Uber demonstrating its practical utility. During this period, Dr.Fix produced patches for 224 (55%) from a corpus of 404 data races spanning various categories; 193 of these patches (86%) were accepted by more than a hundred developers via code reviews and integrated into the codebase.
Language Modeling at Scale
Oct 23, 2018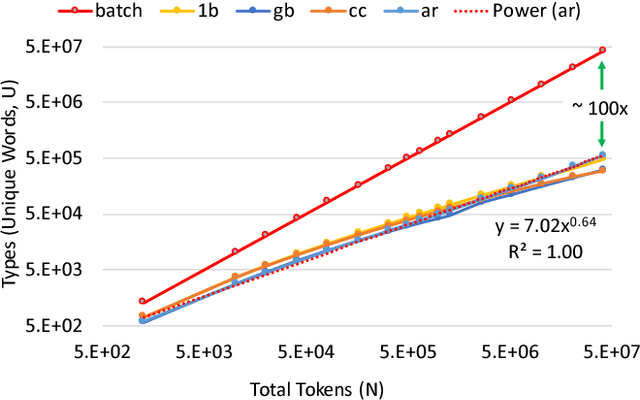
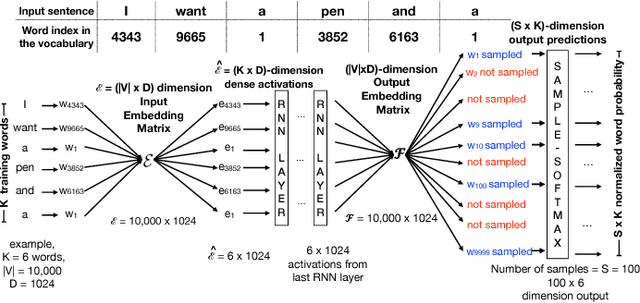
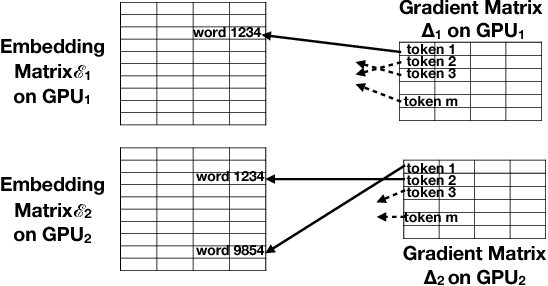
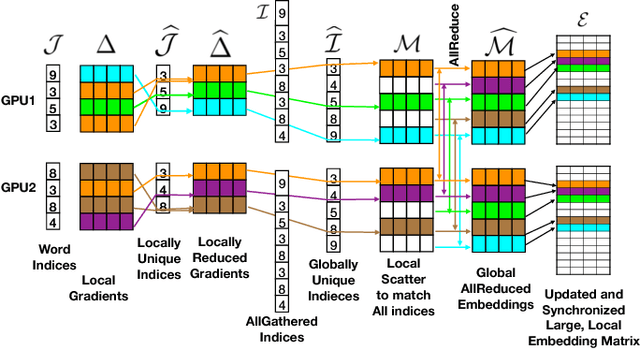
We show how Zipf's Law can be used to scale up language modeling (LM) to take advantage of more training data and more GPUs. LM plays a key role in many important natural language applications such as speech recognition and machine translation. Scaling up LM is important since it is widely accepted by the community that there is no data like more data. Eventually, we would like to train on terabytes (TBs) of text (trillions of words). Modern training methods are far from this goal, because of various bottlenecks, especially memory (within GPUs) and communication (across GPUs). This paper shows how Zipf's Law can address these bottlenecks by grouping parameters for common words and character sequences, because $U \ll N$, where $U$ is the number of unique words (types) and $N$ is the size of the training set (tokens). For a local batch size $K$ with $G$ GPUs and a $D$-dimension embedding matrix, we reduce the original per-GPU memory and communication asymptotic complexity from $\Theta(GKD)$ to $\Theta(GK + UD)$. Empirically, we find $U \propto (GK)^{0.64}$ on four publicly available large datasets. When we scale up the number of GPUs to 64, a factor of 8, training time speeds up by factors up to 6.7$\times$ (for character LMs) and 6.3$\times$ (for word LMs) with negligible loss of accuracy. Our weak scaling on 192 GPUs on the Tieba dataset shows a 35\% improvement in LM prediction accuracy by training on 93 GB of data (2.5$\times$ larger than publicly available SOTA dataset), but taking only 1.25$\times$ increase in training time, compared to 3 GB of the same dataset running on 6 GPUs.