 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMic-hackathon 2024: Hackathon on Machine Learning for Electron and Scanning Probe Microscopy
Jun 10, 2025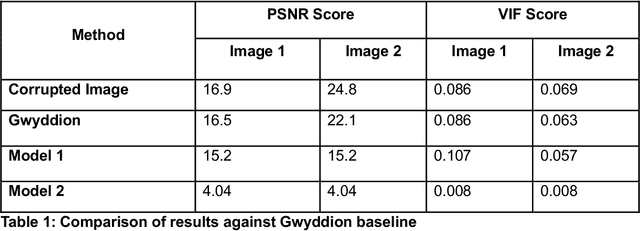

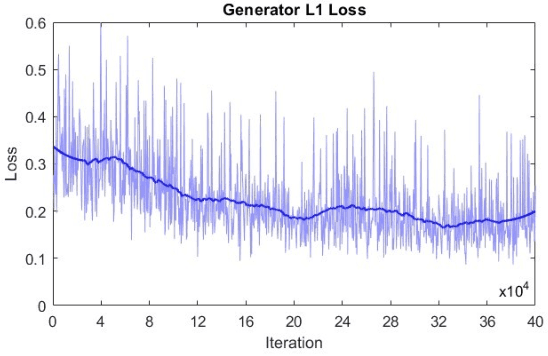
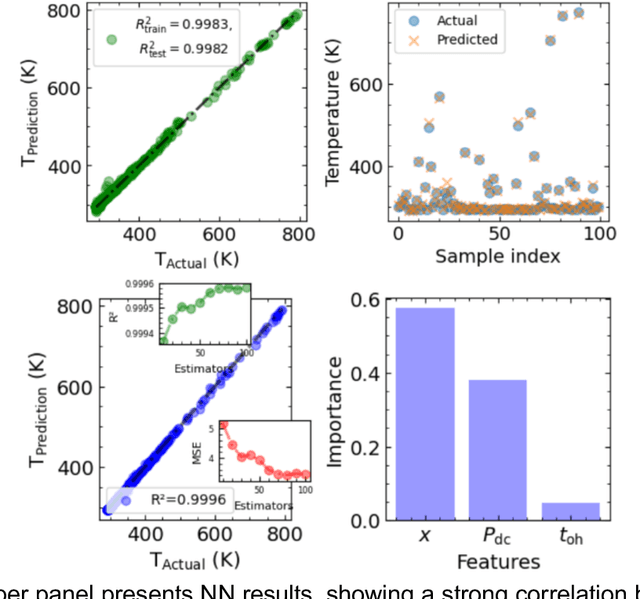
Microscopy is a primary source of information on materials structure and functionality at nanometer and atomic scales. The data generated is often well-structured, enriched with metadata and sample histories, though not always consistent in detail or format. The adoption of Data Management Plans (DMPs) by major funding agencies promotes preservation and access. However, deriving insights remains difficult due to the lack of standardized code ecosystems, benchmarks, and integration strategies. As a result, data usage is inefficient and analysis time is extensive. In addition to post-acquisition analysis, new APIs from major microscope manufacturers enable real-time, ML-based analytics for automated decision-making and ML-agent-controlled microscope operation. Yet, a gap remains between the ML and microscopy communities, limiting the impact of these methods on physics, materials discovery, and optimization. Hackathons help bridge this divide by fostering collaboration between ML researchers and microscopy experts. They encourage the development of novel solutions that apply ML to microscopy, while preparing a future workforce for instrumentation, materials science, and applied ML. This hackathon produced benchmark datasets and digital twins of microscopes to support community growth and standardized workflows. All related code is available at GitHub: https://github.com/KalininGroup/Mic-hackathon-2024-codes-publication/tree/1.0.0.1
Learning Hyperparameters via a Data-Emphasized Variational Objective
Feb 03, 2025



When training large flexible models, practitioners often rely on grid search to select hyperparameters that control over-fitting. This grid search has several disadvantages: the search is computationally expensive, requires carving out a validation set that reduces the available data for training, and requires users to specify candidate values. In this paper, we propose an alternative: directly learning regularization hyperparameters on the full training set via the evidence lower bound ("ELBo") objective from variational methods. For deep neural networks with millions of parameters, we recommend a modified ELBo that upweights the influence of the data likelihood relative to the prior. Our proposed technique overcomes all three disadvantages of grid search. In a case study on transfer learning of image classifiers, we show how our method reduces the 88+ hour grid search of past work to under 3 hours while delivering comparable accuracy. We further demonstrate how our approach enables efficient yet accurate approximations of Gaussian processes with learnable length-scale kernels.
Learning the Regularization Strength for Deep Fine-Tuning via a Data-Emphasized Variational Objective
Oct 25, 2024



A number of popular transfer learning methods rely on grid search to select regularization hyperparameters that control over-fitting. This grid search requirement has several key disadvantages: the search is computationally expensive, requires carving out a validation set that reduces the size of available data for model training, and requires practitioners to specify candidate values. In this paper, we propose an alternative to grid search: directly learning regularization hyperparameters on the full training set via model selection techniques based on the evidence lower bound ("ELBo") objective from variational methods. For deep neural networks with millions of parameters, we specifically recommend a modified ELBo that upweights the influence of the data likelihood relative to the prior while remaining a valid bound on the evidence for Bayesian model selection. Our proposed technique overcomes all three disadvantages of grid search. We demonstrate effectiveness on image classification tasks on several datasets, yielding heldout accuracy comparable to existing approaches with far less compute time.
Transfer Learning with Informative Priors: Simple Baselines Better than Previously Reported
May 24, 2024



We pursue transfer learning to improve classifier accuracy on a target task with few labeled examples available for training. Recent work suggests that using a source task to learn a prior distribution over neural net weights, not just an initialization, can boost target task performance. In this study, we carefully compare transfer learning with and without source task informed priors across 5 datasets. We find that standard transfer learning informed by an initialization only performs far better than reported in previous comparisons. The relative gains of methods using informative priors over standard transfer learning vary in magnitude across datasets. For the scenario of 5-300 examples per class, we find negative or negligible gains on 2 datasets, modest gains (between 1.5-3 points of accuracy) on 2 other datasets, and substantial gains (>8 points) on one dataset. Among methods using informative priors, we find that an isotropic covariance appears competitive with learned low-rank covariance matrix while being substantially simpler to understand and tune. Further analysis suggests that the mechanistic justification for informed priors -- hypothesized improved alignment between train and test loss landscapes -- is not consistently supported due to high variability in empirical landscapes. We release code to allow independent reproduction of all experiments.