 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemT5: A massively multilingual pre-trained text-to-text transformer
Oct 23, 2020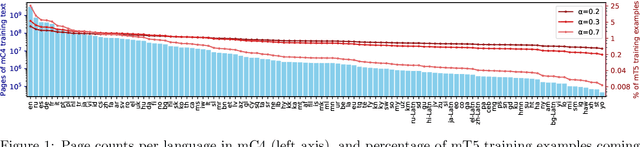

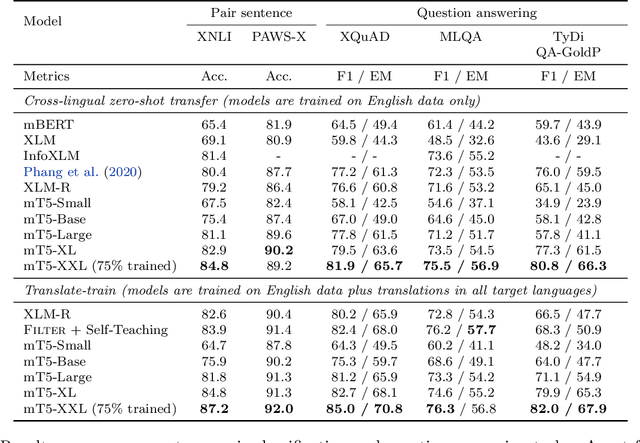
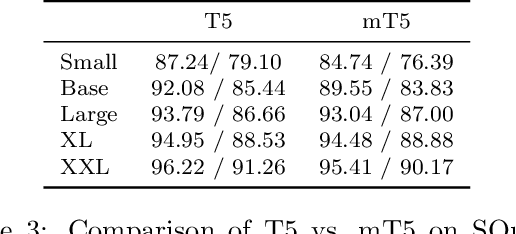
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available.
Text-to-Text Pre-Training for Data-to-Text Tasks
May 22, 2020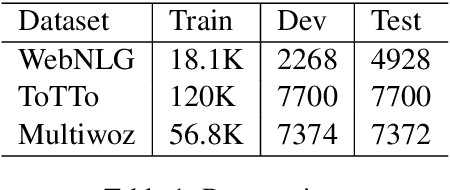
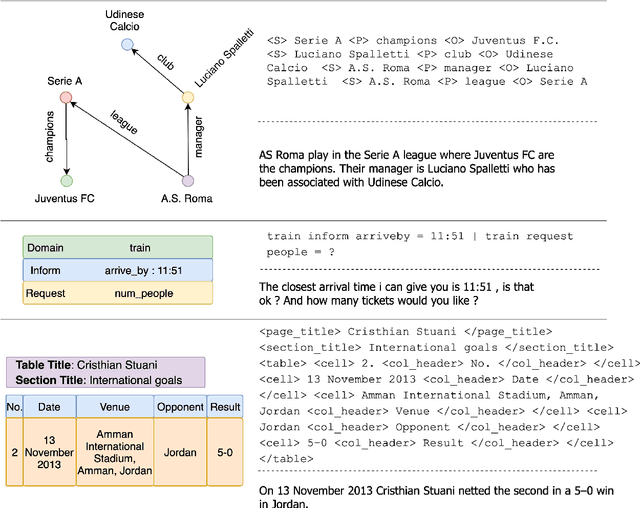
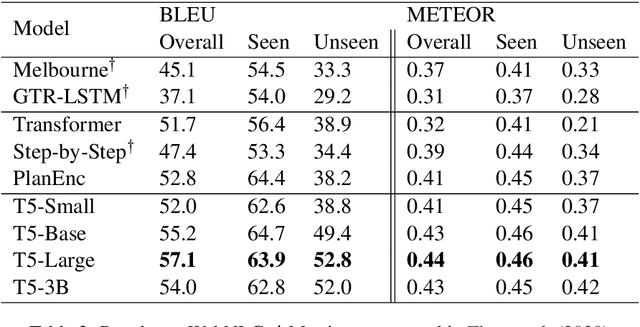
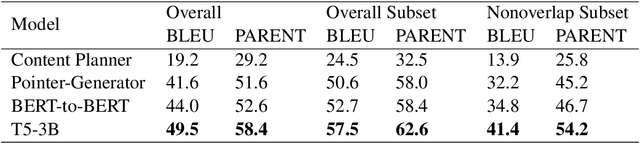
We study the pre-train + fine-tune strategy for data-to-text tasks. Fine-tuning T5 achieves state-of-the-art results on the WebNLG, MultiWoz and ToTTo benchmarks. Such transfer learning enables training of fully end-to-end models that do not rely on any intermediate planning steps, delexicalization or copy mechanisms. T5 pre-training also enables stronger generalization, as evidenced by large improvements on out-of-domain test sets. We hope our work serves as a useful baseline for future research, as pre-training becomes ever more prevalent for data-to-text tasks.
Few-Shot Natural Language Generation by Rewriting Templates
Apr 30, 2020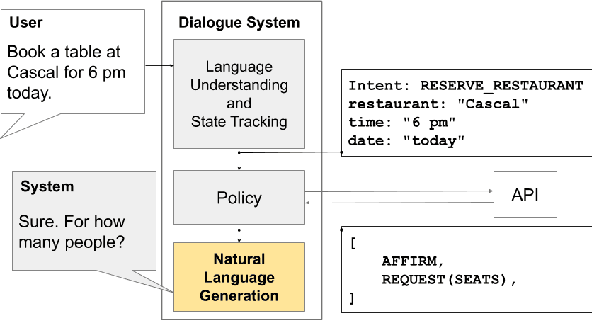
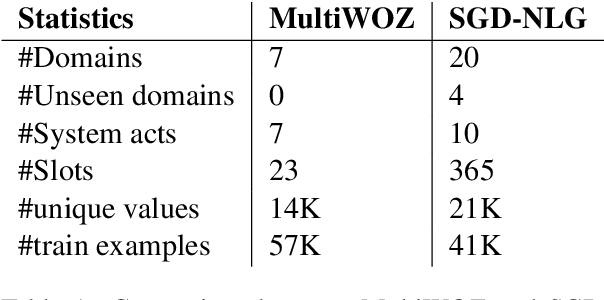
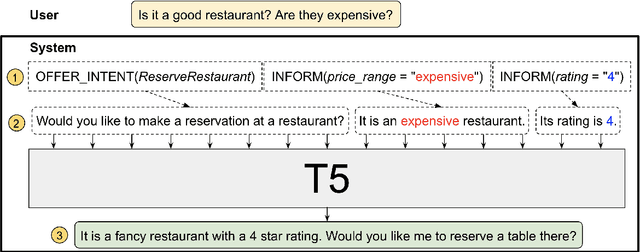
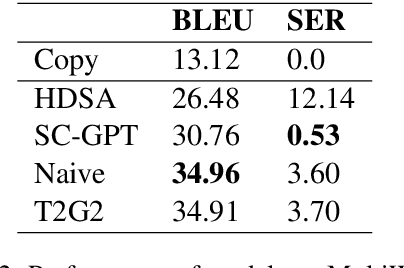
Virtual assistants such as Google Assistant, Alexa and Siri enable users to interact with a large number of services and APIs on the web using natural language. The response generation module converts the actions generated by a policy module into a natural language utterance. Traditionally, template based approaches have been used for response generation in virtual assistants. However, such approaches are not feasible for commercial assistants, which need to support a large number of services. Defining templates for a large number of slot combinations for each of the services supported by large scale assistants becomes tedious. In this work, we propose a template rewriting method for Natural Language Generation (NLG), where the number of templates scales only linearly with the number of slots. A set of simple templates is used to convert actions into utterances, which are concatenated to give a semantically correct, but possibly incoherent and ungrammatical utterance. A pre-trained language model is subsequently employed to rewrite it into coherent, natural sounding text. Through automatic metrics and human evaluation, we show that our method improves over strong baselines, while being much more sample efficient.
Machine Translation Pre-training for Data-to-Text Generation -- A Case Study in Czech
Apr 05, 2020
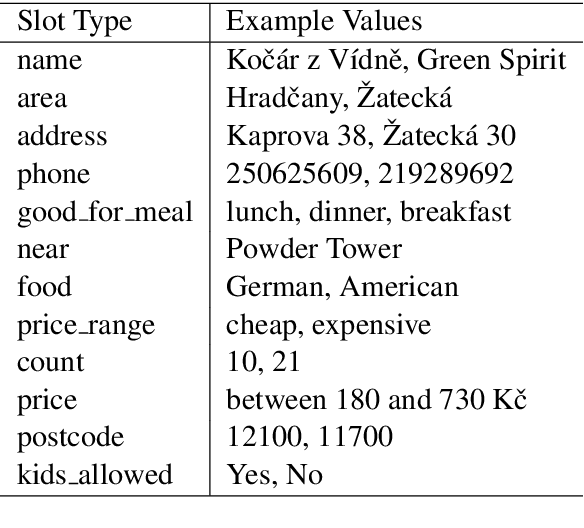

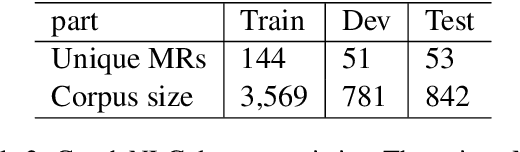
While there is a large body of research studying deep learning methods for text generation from structured data, almost all of it focuses purely on English. In this paper, we study the effectiveness of machine translation based pre-training for data-to-text generation in non-English languages. Since the structured data is generally expressed in English, text generation into other languages involves elements of translation, transliteration and copying - elements already encoded in neural machine translation systems. Moreover, since data-to-text corpora are typically small, this task can benefit greatly from pre-training. Based on our experiments on Czech, a morphologically complex language, we find that pre-training lets us train end-to-end models with significantly improved performance, as judged by automatic metrics and human evaluation. We also show that this approach enjoys several desirable properties, including improved performance in low data scenarios and robustness to unseen slot values.
Incorporating Bilingual Dictionaries for Low Resource Semi-Supervised Neural Machine Translation
Apr 05, 2020
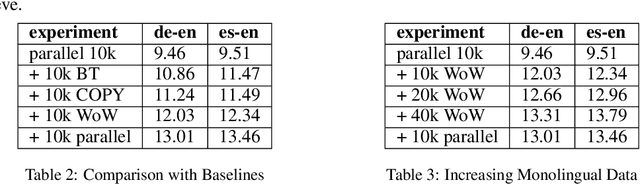
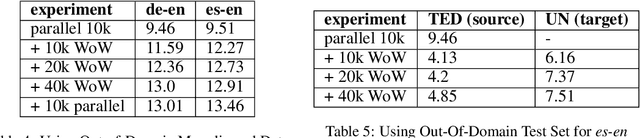

We explore ways of incorporating bilingual dictionaries to enable semi-supervised neural machine translation. Conventional back-translation methods have shown success in leveraging target side monolingual data. However, since the quality of back-translation models is tied to the size of the available parallel corpora, this could adversely impact the synthetically generated sentences in a low resource setting. We propose a simple data augmentation technique to address both this shortcoming. We incorporate widely available bilingual dictionaries that yield word-by-word translations to generate synthetic sentences. This automatically expands the vocabulary of the model while maintaining high quality content. Our method shows an appreciable improvement in performance over strong baselines.
Supervised Contextual Embeddings for Transfer Learning in Natural Language Processing Tasks
Jun 28, 2019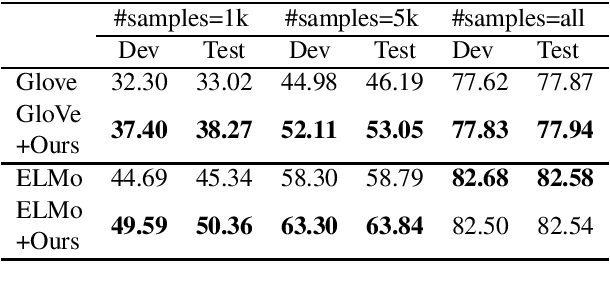
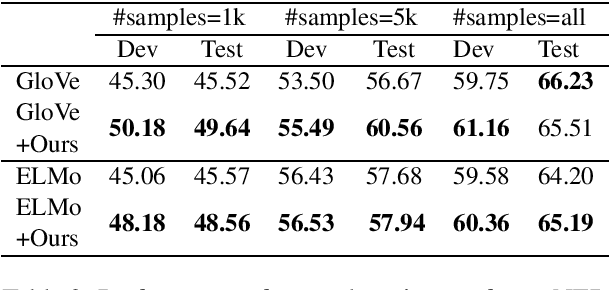
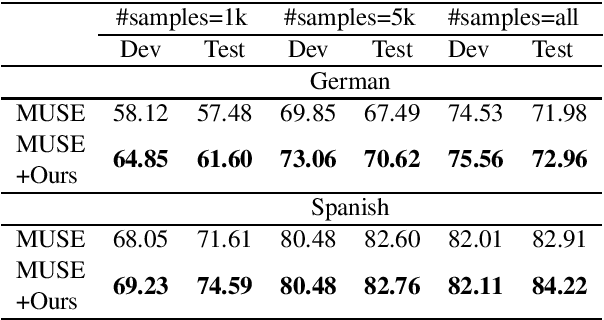
Pre-trained word embeddings are the primary method for transfer learning in several Natural Language Processing (NLP) tasks. Recent works have focused on using unsupervised techniques such as language modeling to obtain these embeddings. In contrast, this work focuses on extracting representations from multiple pre-trained supervised models, which enriches word embeddings with task and domain specific knowledge. Experiments performed in cross-task, cross-domain and cross-lingual settings indicate that such supervised embeddings are helpful, especially in the low-resource setting, but the extent of gains is dependent on the nature of the task and domain. We make our code publicly available.
Tartan: A retrieval-based socialbot powered by a dynamic finite-state machine architecture
Dec 04, 2018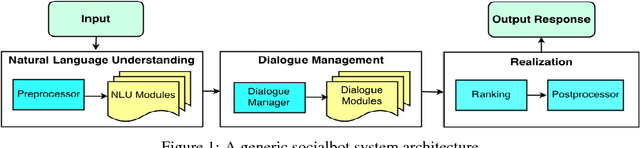
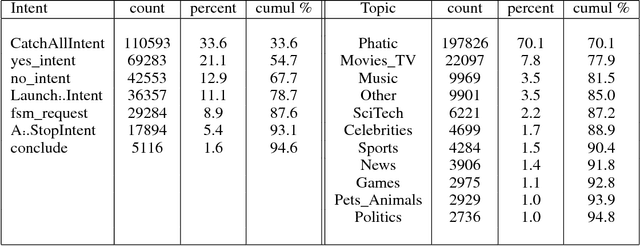
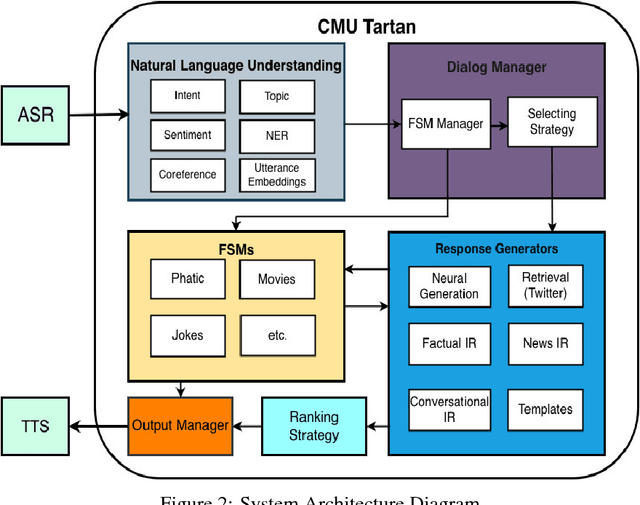
This paper describes the Tartan conversational agent built for the 2018 Alexa Prize Competition. Tartan is a non-goal-oriented socialbot focused around providing users with an engaging and fluent casual conversation. Tartan's key features include an emphasis on structured conversation based on flexible finite-state models and an approach focused on understanding and using conversational acts. To provide engaging conversations, Tartan blends script-like yet dynamic responses with data-based generative and retrieval models. Unique to Tartan is that our dialog manager is modeled as a dynamic Finite State Machine. To our knowledge, no other conversational agent implementation has followed this specific structure.