Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Text Pre-Training for Data-to-Text Tasks
Paper and Code
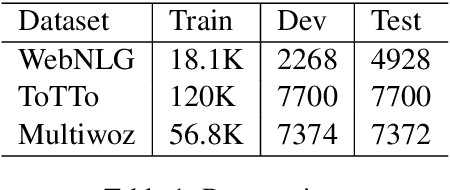
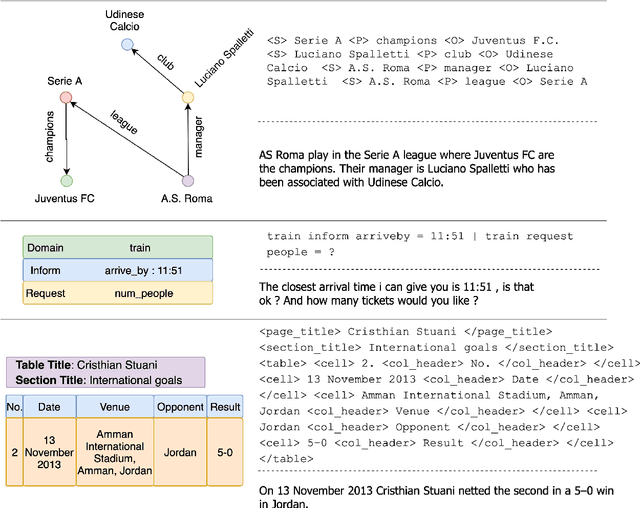
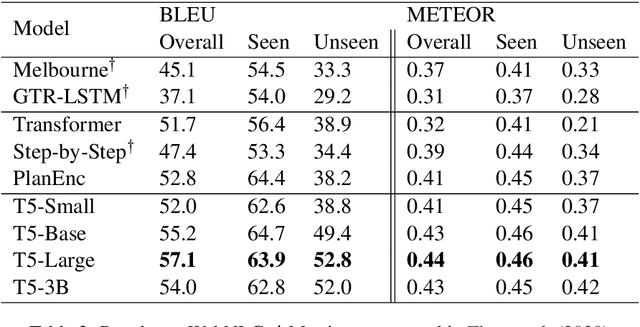
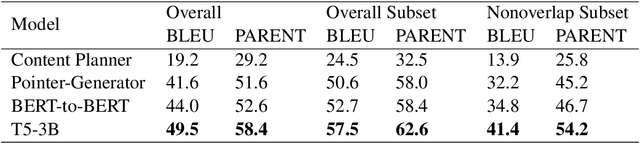
We study the pre-train + fine-tune strategy for data-to-text tasks. Fine-tuning T5 achieves state-of-the-art results on the WebNLG, MultiWoz and ToTTo benchmarks. Such transfer learning enables training of fully end-to-end models that do not rely on any intermediate planning steps, delexicalization or copy mechanisms. T5 pre-training also enables stronger generalization, as evidenced by large improvements on out-of-domain test sets. We hope our work serves as a useful baseline for future research, as pre-training becomes ever more prevalent for data-to-text tasks.
View paper on