 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMihaela van der Schaar
Shape Arithmetic Expressions: Advancing Scientific Discovery Beyond Closed-Form Equations
Apr 15, 2024
Symbolic regression has excelled in uncovering equations from physics, chemistry, biology, and related disciplines. However, its effectiveness becomes less certain when applied to experimental data lacking inherent closed-form expressions. Empirically derived relationships, such as entire stress-strain curves, may defy concise closed-form representation, compelling us to explore more adaptive modeling approaches that balance flexibility with interpretability. In our pursuit, we turn to Generalized Additive Models (GAMs), a widely used class of models known for their versatility across various domains. Although GAMs can capture non-linear relationships between variables and targets, they cannot capture intricate feature interactions. In this work, we investigate both of these challenges and propose a novel class of models, Shape Arithmetic Expressions (SHAREs), that fuses GAM's flexible shape functions with the complex feature interactions found in mathematical expressions. SHAREs also provide a unifying framework for both of these approaches. We also design a set of rules for constructing SHAREs that guarantee transparency of the found expressions beyond the standard constraints based on the model's size.
ODE Discovery for Longitudinal Heterogeneous Treatment Effects Inference
Mar 16, 2024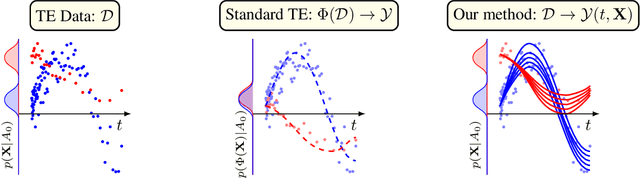

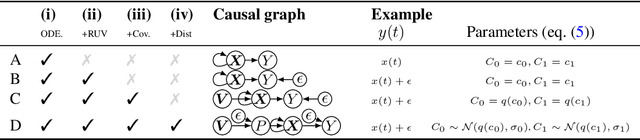
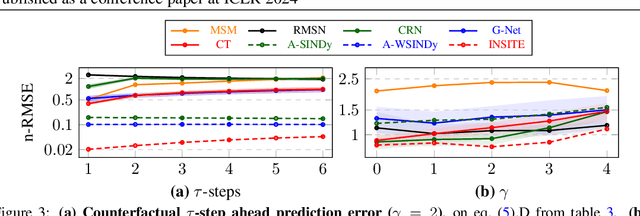
Inferring unbiased treatment effects has received widespread attention in the machine learning community. In recent years, our community has proposed numerous solutions in standard settings, high-dimensional treatment settings, and even longitudinal settings. While very diverse, the solution has mostly relied on neural networks for inference and simultaneous correction of assignment bias. New approaches typically build on top of previous approaches by proposing new (or refined) architectures and learning algorithms. However, the end result -- a neural-network-based inference machine -- remains unchallenged. In this paper, we introduce a different type of solution in the longitudinal setting: a closed-form ordinary differential equation (ODE). While we still rely on continuous optimization to learn an ODE, the resulting inference machine is no longer a neural network. Doing so yields several advantages such as interpretability, irregular sampling, and a different set of identification assumptions. Above all, we consider the introduction of a completely new type of solution to be our most important contribution as it may spark entirely new innovations in treatment effects in general. We facilitate this by formulating our contribution as a framework that can transform any ODE discovery method into a treatment effects method.
Dissecting Sample Hardness: A Fine-Grained Analysis of Hardness Characterization Methods for Data-Centric AI
Mar 07, 2024
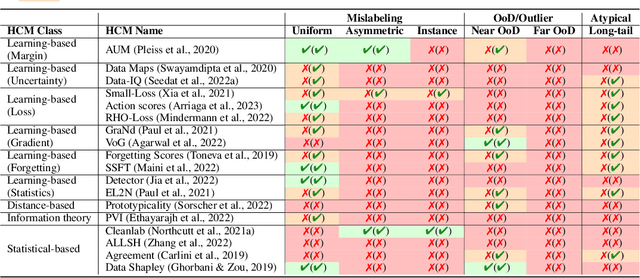
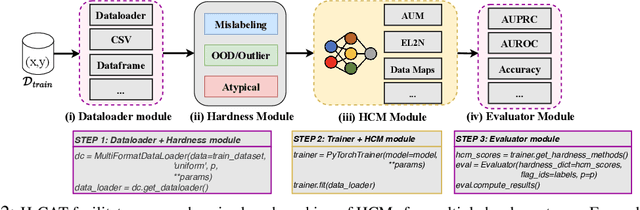
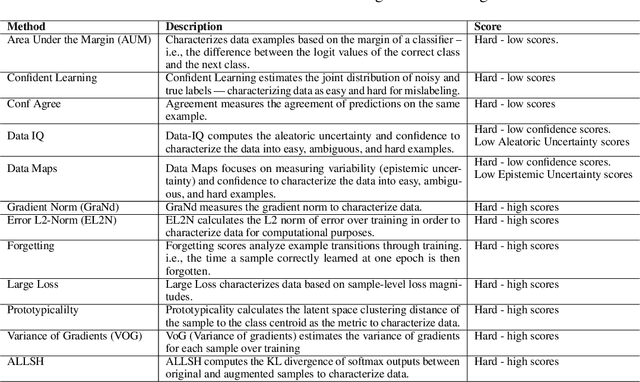
Characterizing samples that are difficult to learn from is crucial to developing highly performant ML models. This has led to numerous Hardness Characterization Methods (HCMs) that aim to identify "hard" samples. However, there is a lack of consensus regarding the definition and evaluation of "hardness". Unfortunately, current HCMs have only been evaluated on specific types of hardness and often only qualitatively or with respect to downstream performance, overlooking the fundamental quantitative identification task. We address this gap by presenting a fine-grained taxonomy of hardness types. Additionally, we propose the Hardness Characterization Analysis Toolkit (H-CAT), which supports comprehensive and quantitative benchmarking of HCMs across the hardness taxonomy and can easily be extended to new HCMs, hardness types, and datasets. We use H-CAT to evaluate 13 different HCMs across 8 hardness types. This comprehensive evaluation encompassing over 14K setups uncovers strengths and weaknesses of different HCMs, leading to practical tips to guide HCM selection and future development. Our findings highlight the need for more comprehensive HCM evaluation, while we hope our hardness taxonomy and toolkit will advance the principled evaluation and uptake of data-centric AI methods.
Defining Expertise: Applications to Treatment Effect Estimation
Mar 01, 2024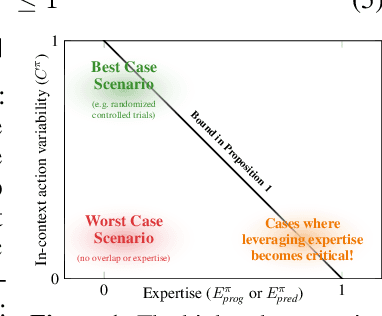
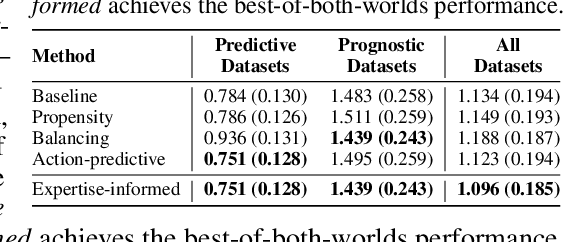
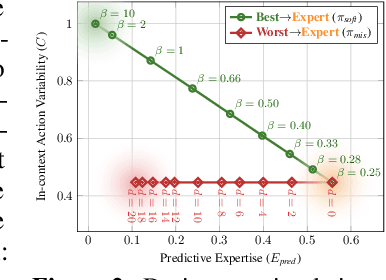
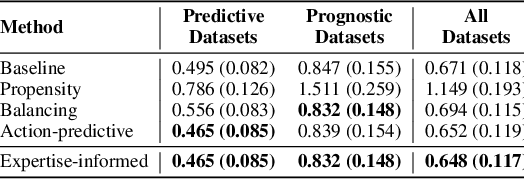
Decision-makers are often experts of their domain and take actions based on their domain knowledge. Doctors, for instance, may prescribe treatments by predicting the likely outcome of each available treatment. Actions of an expert thus naturally encode part of their domain knowledge, and can help make inferences within the same domain: Knowing doctors try to prescribe the best treatment for their patients, we can tell treatments prescribed more frequently are likely to be more effective. Yet in machine learning, the fact that most decision-makers are experts is often overlooked, and "expertise" is seldom leveraged as an inductive bias. This is especially true for the literature on treatment effect estimation, where often the only assumption made about actions is that of overlap. In this paper, we argue that expertise - particularly the type of expertise the decision-makers of a domain are likely to have - can be informative in designing and selecting methods for treatment effect estimation. We formally define two types of expertise, predictive and prognostic, and demonstrate empirically that: (i) the prominent type of expertise in a domain significantly influences the performance of different methods in treatment effect estimation, and (ii) it is possible to predict the type of expertise present in a dataset, which can provide a quantitative basis for model selection.
DAGnosis: Localized Identification of Data Inconsistencies using Structures
Feb 28, 2024Identification and appropriate handling of inconsistencies in data at deployment time is crucial to reliably use machine learning models. While recent data-centric methods are able to identify such inconsistencies with respect to the training set, they suffer from two key limitations: (1) suboptimality in settings where features exhibit statistical independencies, due to their usage of compressive representations and (2) lack of localization to pin-point why a sample might be flagged as inconsistent, which is important to guide future data collection. We solve these two fundamental limitations using directed acyclic graphs (DAGs) to encode the training set's features probability distribution and independencies as a structure. Our method, called DAGnosis, leverages these structural interactions to bring valuable and insightful data-centric conclusions. DAGnosis unlocks the localization of the causes of inconsistencies on a DAG, an aspect overlooked by previous approaches. Moreover, we show empirically that leveraging these interactions (1) leads to more accurate conclusions in detecting inconsistencies, as well as (2) provides more detailed insights into why some samples are flagged.
Informed Meta-Learning
Feb 25, 2024In noisy and low-data regimes prevalent in real-world applications, an outstanding challenge of machine learning lies in effectively incorporating inductive biases that promote data efficiency and robustness. Meta-learning and informed ML stand out as two approaches for incorporating prior knowledge into the ML pipeline. While the former relies on a purely data-driven source of priors, the latter is guided by a formal representation of expert knowledge. This paper introduces a novel hybrid paradigm, informed meta-learning, seeking complementarity in cross-task knowledge sharing of humans and machines. We establish the foundational components of informed meta-learning and present a concrete instantiation of this framework--the Informed Neural Process. Through a series of illustrative and larger-scale experiments, we demonstrate the potential benefits of informed meta-learning in improving data efficiency and robustness to observational noise, task distribution shifts, and heterogeneity.
Retrieval-Augmented Thought Process as Sequential Decision Making
Feb 12, 2024Large Language Models (LLMs) have demonstrated their strong ability to assist people and show "sparks of intelligence". However, several open challenges hinder their wider application: such as concerns over privacy, tendencies to produce hallucinations, and difficulties in handling long contexts. In this work, we address those challenges by introducing the Retrieval-Augmented Thought Process (RATP). Given access to external knowledge, RATP formulates the thought generation of LLMs as a multiple-step decision process. To optimize such a thought process, RATP leverages Monte-Carlo Tree Search, and learns a Q-value estimator that permits cost-efficient inference. In addressing the task of question-answering with private data, where ethical and security concerns limit LLM training methods, RATP achieves a 50% improvement over existing in-context retrieval-augmented language models.
Time Series Diffusion in the Frequency Domain
Feb 08, 2024Fourier analysis has been an instrumental tool in the development of signal processing. This leads us to wonder whether this framework could similarly benefit generative modelling. In this paper, we explore this question through the scope of time series diffusion models. More specifically, we analyze whether representing time series in the frequency domain is a useful inductive bias for score-based diffusion models. By starting from the canonical SDE formulation of diffusion in the time domain, we show that a dual diffusion process occurs in the frequency domain with an important nuance: Brownian motions are replaced by what we call mirrored Brownian motions, characterized by mirror symmetries among their components. Building on this insight, we show how to adapt the denoising score matching approach to implement diffusion models in the frequency domain. This results in frequency diffusion models, which we compare to canonical time diffusion models. Our empirical evaluation on real-world datasets, covering various domains like healthcare and finance, shows that frequency diffusion models better capture the training distribution than time diffusion models. We explain this observation by showing that time series from these datasets tend to be more localized in the frequency domain than in the time domain, which makes them easier to model in the former case. All our observations point towards impactful synergies between Fourier analysis and diffusion models.
Large Language Models to Enhance Bayesian Optimization
Feb 06, 2024Bayesian optimization (BO) is a powerful approach for optimizing complex and expensive-to-evaluate black-box functions. Its importance is underscored in many applications, notably including hyperparameter tuning, but its efficacy depends on efficiently balancing exploration and exploitation. While there has been substantial progress in BO methods, striking this balance still remains a delicate process. In this light, we present \texttt{LLAMBO}, a novel approach that integrates the capabilities of large language models (LLM) within BO. At a high level, we frame the BO problem in natural language terms, enabling LLMs to iteratively propose promising solutions conditioned on historical evaluations. More specifically, we explore how combining contextual understanding, few-shot learning proficiency, and domain knowledge of LLMs can enhance various components of model-based BO. Our findings illustrate that \texttt{LLAMBO} is effective at zero-shot warmstarting, and improves surrogate modeling and candidate sampling, especially in the early stages of search when observations are sparse. Our approach is performed in context and does not require LLM finetuning. Additionally, it is modular by design, allowing individual components to be integrated into existing BO frameworks, or function cohesively as an end-to-end method. We empirically validate \texttt{LLAMBO}'s efficacy on the problem of hyperparameter tuning, highlighting strong empirical performance across a range of diverse benchmarks, proprietary, and synthetic tasks.
Risk-Sensitive Diffusion: Learning the Underlying Distribution from Noisy Samples
Feb 03, 2024While achieving remarkable performances, we show that diffusion models are fragile to the presence of noisy samples, limiting their potential in the vast amount of settings where, unlike image synthesis, we are not blessed with clean data. Motivated by our finding that such fragility originates from the distribution gaps between noisy and clean samples along the diffusion process, we introduce risk-sensitive SDE, a stochastic differential equation that is parameterized by the risk (i.e., data "dirtiness") to adjust the distributions of noisy samples, reducing misguidance while benefiting from their contained information. The optimal expression for risk-sensitive SDE depends on the specific noise distribution, and we derive its parameterizations that minimize the misguidance of noisy samples for both Gaussian and general non-Gaussian perturbations. We conduct extensive experiments on both synthetic and real-world datasets (e.g., medical time series), showing that our model effectively recovers the clean data distribution from noisy samples, significantly outperforming conditional generation baselines.