 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Elevation Models as a Lightweight Alternative to LiDAR for Radio Environment Map Estimation
Apr 07, 2026Next-generation wireless systems such as 6G operate at higher frequency bands, making signal propagation highly sensitive to environmental factors such as buildings and vege- tation. Accurate Radio Environment Map (REM) estimation is therefore increasingly important for effective network planning and operation. Existing methods, from ray-tracing simulators to deep learning generative models, achieve promising results but require detailed 3D environment data such as LiDAR-derived point clouds, which are costly to acquire, several gigabytes per km2 in size, and quickly outdated in dynamic environments. We propose a two-stage framework that eliminates the need for 3D data at inference time: in the first stage, a learned estimator predicts elevation maps directly from satellite RGB imagery, which are then fed alongside antenna parameters into the REM estimator in the second stage. Across existing CNN- based REM estimation architectures, the proposed approach improves RMSE by up to 7.8% over image-only baselines, while operating on the same input feature space and requiring no 3D data during inference, offering a practical alternative for scalable radio environment modelling.
Design Principles of Zero-Shot Self-Supervised Unknown Emitter Detectors
Nov 10, 2025The proliferation of wireless devices necessitates more robust and reliable emitter detection and identification for critical tasks such as spectrum management and network security. Existing studies exploring methods for unknown emitters identification, however, are typically hindered by their dependence on labeled or proprietary datasets, unrealistic assumptions (e.g. all samples with identical transmitted messages), or deficiency of systematic evaluations across different architectures and design dimensions. In this work, we present a comprehensive evaluation of unknown emitter detection systems across key aspects of the design space, focusing on data modality, learning approaches, and feature learning modules. We demonstrate that prior self-supervised, zero-shot emitter detection approaches commonly use datasets with identical transmitted messages. To address this limitation, we propose a 2D-Constellation data modality for scenarios with varying messages, achieving up to a 40\% performance improvement in ROC-AUC, NMI, and F1 metrics compared to conventional raw I/Q data. Furthermore, we introduce interpretable Kolmogorov-Arnold Networks (KANs) to enhance model transparency, and a Singular Value Decomposition (SVD)-based initialization procedure for feature learning modules operating on sparse 2D-Constellation data, which improves the performance of Deep Clustering approaches by up to 40\% across the same metrics comparing to the modules without SVD initialization. We evaluate all data modalities and learning modules across three learning approaches: Deep Clustering, Auto Encoder and Contrastive Learning.
Automated Modeling Method for Pathloss Model Discovery
May 29, 2025Modeling propagation is the cornerstone for designing and optimizing next-generation wireless systems, with a particular emphasis on 5G and beyond era. Traditional modeling methods have long relied on statistic-based techniques to characterize propagation behavior across different environments. With the expansion of wireless communication systems, there is a growing demand for methods that guarantee the accuracy and interoperability of modeling. Artificial intelligence (AI)-based techniques, in particular, are increasingly being adopted to overcome this challenge, although the interpretability is not assured with most of these methods. Inspired by recent advancements in AI, this paper proposes a novel approach that accelerates the discovery of path loss models while maintaining interpretability. The proposed method automates the model formulation, evaluation, and refinement, facilitating model discovery. We evaluate two techniques: one based on Deep Symbolic Regression, offering full interpretability, and the second based on Kolmogorov-Arnold Networks, providing two levels of interpretability. Both approaches are evaluated on two synthetic and two real-world datasets. Our results show that Kolmogorov-Arnold Networks achieve R^2 values close to 1 with minimal prediction error, while Deep Symbolic Regression generates compact models with moderate accuracy. Moreover, on the selected examples, we demonstrate that automated methods outperform traditional methods, achieving up to 75% reduction in prediction errors, offering accurate and explainable solutions with potential to increase the efficiency of discovering next-generation path loss models.
A Network Science Approach to Granular Time Series Segmentation
May 23, 2025Time series segmentation (TSS) is one of the time series (TS) analysis techniques, that has received considerably less attention compared to other TS related tasks. In recent years, deep learning architectures have been introduced for TSS, however their reliance on sliding windows limits segmentation granularity due to fixed window sizes and strides. To overcome these challenges, we propose a new more granular TSS approach that utilizes the Weighted Dual Perspective Visbility Graph (WDPVG) TS into a graph and combines it with a Graph Attention Network (GAT). By transforming TS into graphs, we are able to capture different structural aspects of the data that would otherwise remain hidden. By utilizing the representation learning capabilities of Graph Neural Networks, our method is able to effectively identify meaningful segments within the TS. To better understand the potential of our approach, we also experimented with different TS-to-graph transformations and compared their performance. Our contributions include: a) formulating the TSS as a node classification problem on graphs; b) conducting an extensive analysis of various TS- to-graph transformations applied to TSS using benchmark datasets from the TSSB repository; c) providing the first detailed study on utilizing GNNs for analyzing graph representations of TS in the context of TSS; d) demonstrating the effectiveness of our method, which achieves an average F1 score of 0.97 across 59 diverse TSS benchmark datasets; e) outperforming the seq2point baseline method by 0.05 in terms of F1 score; and f) reducing the required training data compared to the baseline methods.
The Energy Cost of Artificial Intelligence of Things Lifecycle
Aug 01, 2024Artificial intelligence (AI)coupled with existing Internet of Things (IoT) enables more streamlined and autonomous operations across various economic sectors. Consequently, the paradigm of Artificial Intelligence of Things (AIoT) having AI techniques at its core implies additional energy and carbon costs that may become significant with more complex neural architectures. To better understand the energy and Carbon Footprint (CF) of some AIoT components, very recent studies employ conventional metrics. However, these metrics are not designed to capture energy efficiency aspects of inference. In this paper, we propose a new metric, the Energy Cost of AIoT Lifecycle (eCAL) to capture the overall energy cost of inference over the lifecycle of an AIoT system. We devise a new methodology for determining eCAL of an AIoT system by analyzing the complexity of data manipulation in individual components involved in the AIoT lifecycle and derive the overall and per bit energy consumption. With eCAL we show that the better a model is and the more it is used, the more energy efficient an inference is. For an example AIoT configuration, eCAL for making $100$ inferences is $1.43$ times higher than for $1000$ inferences. We also evaluate the CF of the AIoT system by calculating the equivalent CO$_{2}$ emissions based on the energy consumption and the Carbon Intensity (CI) across different countries. Using 2023 renewable data, our analysis reveals that deploying an AIoT system in Germany results in emitting $4.62$ times higher CO$_2$ than in Finland, due to latter using more low-CI energy sources.
Deep Feature Learning for Wireless Spectrum Data
Aug 07, 2023In recent years, the traditional feature engineering process for training machine learning models is being automated by the feature extraction layers integrated in deep learning architectures. In wireless networks, many studies were conducted in automatic learning of feature representations for domain-related challenges. However, most of the existing works assume some supervision along the learning process by using labels to optimize the model. In this paper, we investigate an approach to learning feature representations for wireless transmission clustering in a completely unsupervised manner, i.e. requiring no labels in the process. We propose a model based on convolutional neural networks that automatically learns a reduced dimensionality representation of the input data with 99.3% less components compared to a baseline principal component analysis (PCA). We show that the automatic representation learning is able to extract fine-grained clusters containing the shapes of the wireless transmission bursts, while the baseline enables only general separability of the data based on the background noise.
Towards Sustainable Deep Learning for Multi-Label Classification on NILM
Jul 18, 2023



Non-intrusive load monitoring (NILM) is the process of obtaining appliance-level data from a single metering point, measuring total electricity consumption of a household or a business. Appliance-level data can be directly used for demand response applications and energy management systems as well as for awareness raising and motivation for improvements in energy efficiency and reduction in the carbon footprint. Recently, classical machine learning and deep learning (DL) techniques became very popular and proved as highly effective for NILM classification, but with the growing complexity these methods are faced with significant computational and energy demands during both their training and operation. In this paper, we introduce a novel DL model aimed at enhanced multi-label classification of NILM with improved computation and energy efficiency. We also propose a testing methodology for comparison of different models using data synthesized from the measurement datasets so as to better represent real-world scenarios. Compared to the state-of-the-art, the proposed model has its carbon footprint reduced by more than 23% while providing on average approximately 8 percentage points in performance improvement when testing on data derived from REFIT and UK-DALE datasets.
XAI for Self-supervised Clustering of Wireless Spectrum Activity
May 17, 2023The so-called black-box deep learning (DL) models are increasingly used in classification tasks across many scientific disciplines, including wireless communications domain. In this trend, supervised DL models appear as most commonly proposed solutions to domain-related classification problems. Although they are proven to have unmatched performance, the necessity for large labeled training data and their intractable reasoning, as two major drawbacks, are constraining their usage. The self-supervised architectures emerged as a promising solution that reduces the size of the needed labeled data, but the explainability problem remains. In this paper, we propose a methodology for explaining deep clustering, self-supervised learning architectures comprised of a representation learning part based on a Convolutional Neural Network (CNN) and a clustering part. For the state of the art representation learning part, our methodology employs Guided Backpropagation to interpret the regions of interest of the input data. For the clustering part, the methodology relies on Shallow Trees to explain the clustering result using optimized depth decision tree. Finally, a data-specific visualizations part enables connection for each of the clusters to the input data trough the relevant features. We explain on a use case of wireless spectrum activity clustering how the CNN-based, deep clustering architecture reasons.
On-Premise Artificial Intelligence as a Service for Small and Medium Size Setups
Oct 12, 2022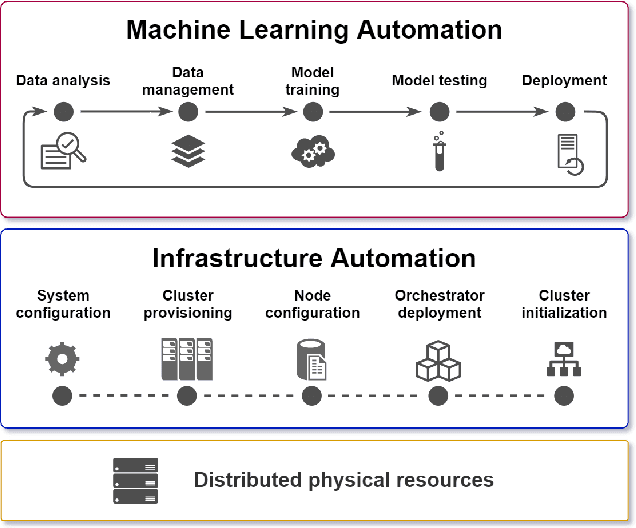
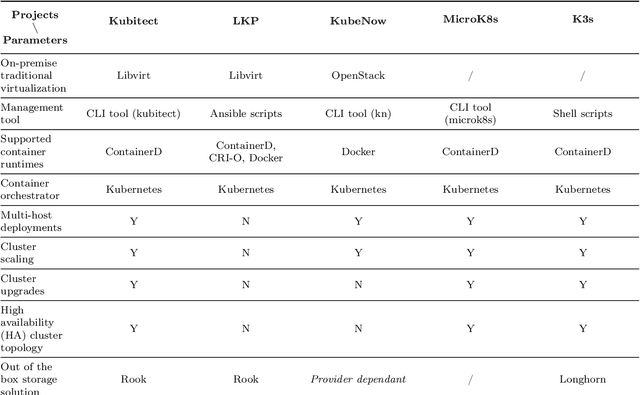
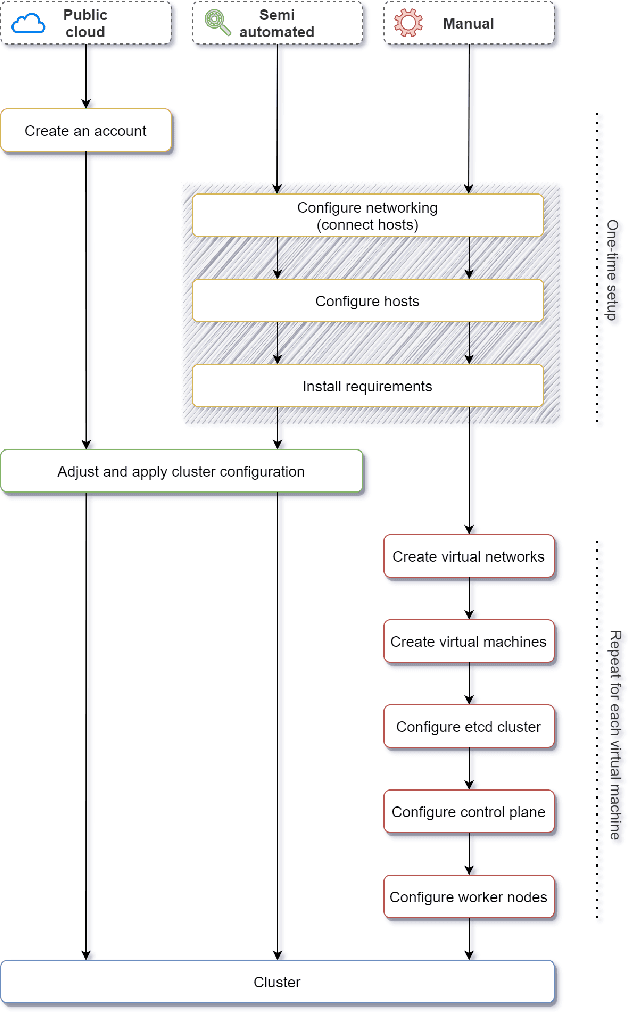
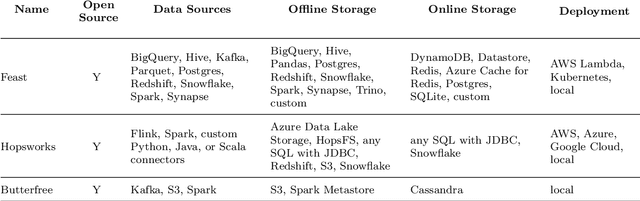
Artificial Intelligence (AI) technologies are moving from customized deployments in specific domains towards generic solutions horizontally permeating vertical domains and industries. For instance, decisions on when to perform maintenance of roads or bridges or how to optimize public lighting in view of costs and safety in smart cities are increasingly informed by AI models. While various commercial solutions offer user friendly and easy to use AI as a Service (AIaaS), functionality-wise enabling the democratization of such ecosystems, open-source equivalent ecosystems are lagging behind. In this chapter, we discuss AIaaS functionality and corresponding technology stack and analyze possible realizations using open source user friendly technologies that are suitable for on-premise set-ups of small and medium sized users allowing full control over the data and technological platform without any third-party dependence or vendor lock-in.
Self-supervised Learning for Clustering of Wireless Spectrum Activity
Sep 22, 2022
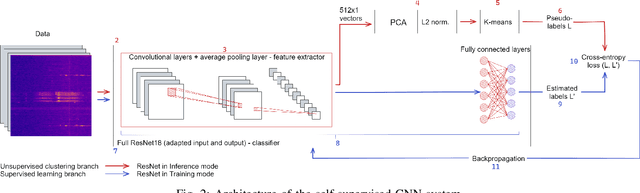
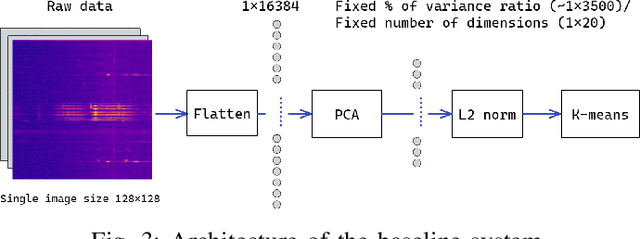
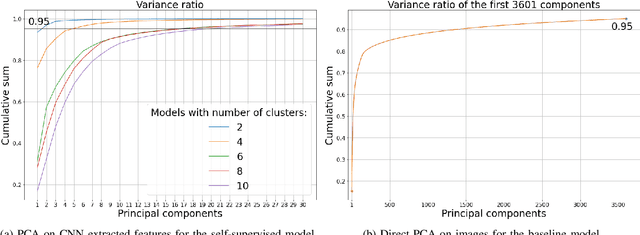
In recent years, much work has been done on processing of wireless spectral data involving machine learning techniques in domain-related problems for cognitive radio networks, such as anomaly detection, modulation classification, technology classification and device fingerprinting. Most of the solutions are based on labeled data, created in a controlled manner and processed with supervised learning approaches. Labeling spectral data is a laborious and expensive process, being one of the main drawbacks of using supervised approaches. In this paper, we introduce self-supervised learning for exploring spectral activities using real-world, unlabeled data. We show that the proposed model achieves superior performance regarding the quality of extracted features and clustering performance. We achieve reduction of the feature vectors size by 2 orders of magnitude (from 3601 to 20), while improving performance by 2 to 2.5 times across the evaluation metrics, supported by visual assessment. Using 15 days of continuous narrowband spectrum sensing data, we found that 17% of the spectrogram slices contain no or very weak transmissions, 36% contain mostly IEEE 802.15.4, 26% contain coexisting IEEE 802.15.4 with LoRA and proprietary activity, 12% contain LoRA with variable background noise and 9% contain only dotted activity, representing LoRA and proprietary transmissions.