 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermute Me Softly: Learning Soft Permutations for Graph Representations
Oct 05, 2021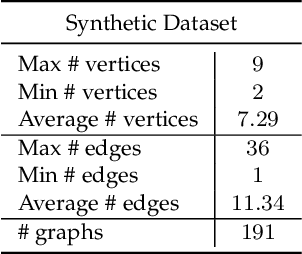
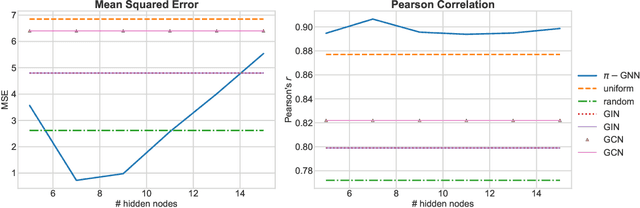
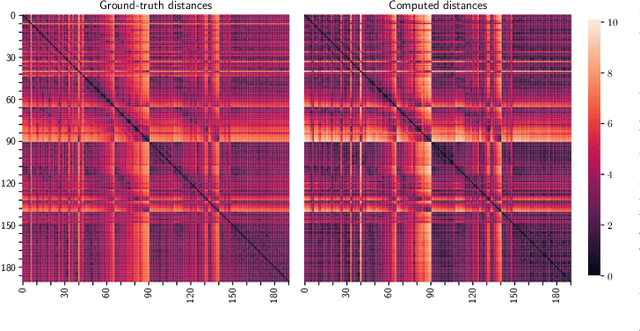
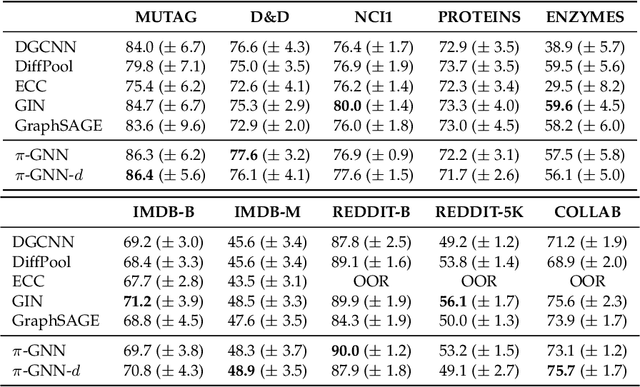
Graph neural networks (GNNs) have recently emerged as a dominant paradigm for machine learning with graphs. Research on GNNs has mainly focused on the family of message passing neural networks (MPNNs). Similar to the Weisfeiler-Leman (WL) test of isomorphism, these models follow an iterative neighborhood aggregation procedure to update vertex representations, and they next compute graph representations by aggregating the representations of the vertices. Although very successful, MPNNs have been studied intensively in the past few years. Thus, there is a need for novel architectures which will allow research in the field to break away from MPNNs. In this paper, we propose a new graph neural network model, so-called $\pi$-GNN which learns a "soft" permutation (i.e., doubly stochastic) matrix for each graph, and thus projects all graphs into a common vector space. The learned matrices impose a "soft" ordering on the vertices of the input graphs, and based on this ordering, the adjacency matrices are mapped into vectors. These vectors can be fed into fully-connected or convolutional layers to deal with supervised learning tasks. In case of large graphs, to make the model more efficient in terms of running time and memory, we further relax the doubly stochastic matrices to row stochastic matrices. We empirically evaluate the model on graph classification and graph regression datasets and show that it achieves performance competitive with state-of-the-art models.
JuriBERT: A Masked-Language Model Adaptation for French Legal Text
Oct 04, 2021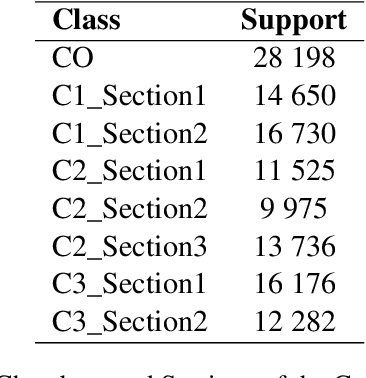
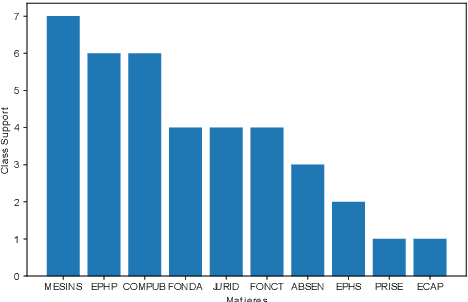
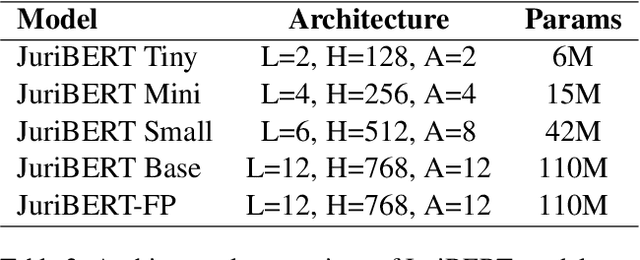
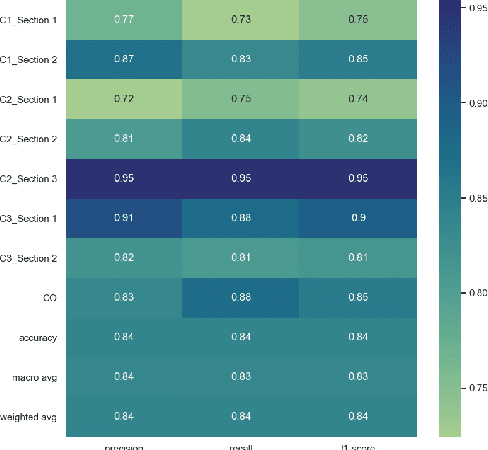
Language models have proven to be very useful when adapted to specific domains. Nonetheless, little research has been done on the adaptation of domain-specific BERT models in the French language. In this paper, we focus on creating a language model adapted to French legal text with the goal of helping law professionals. We conclude that some specific tasks do not benefit from generic language models pre-trained on large amounts of data. We explore the use of smaller architectures in domain-specific sub-languages and their benefits for French legal text. We prove that domain-specific pre-trained models can perform better than their equivalent generalised ones in the legal domain. Finally, we release JuriBERT, a new set of BERT models adapted to the French legal domain.
BERTweetFR : Domain Adaptation of Pre-Trained Language Models for French Tweets
Sep 21, 2021

We introduce BERTweetFR, the first large-scale pre-trained language model for French tweets. Our model is initialized using the general-domain French language model CamemBERT which follows the base architecture of RoBERTa. Experiments show that BERTweetFR outperforms all previous general-domain French language models on two downstream Twitter NLP tasks of offensiveness identification and named entity recognition. The dataset used in the offensiveness detection task is first created and annotated by our team, filling in the gap of such analytic datasets in French. We make our model publicly available in the transformers library with the aim of promoting future research in analytic tasks for French tweets.
Node Feature Kernels Increase Graph Convolutional Network Robustness
Sep 04, 2021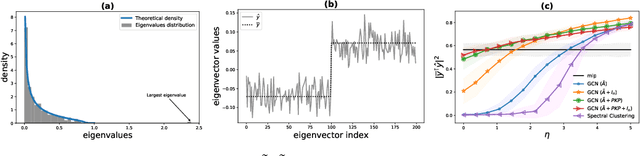
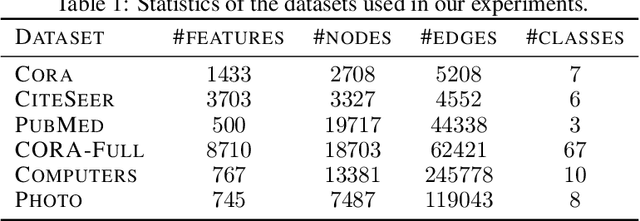
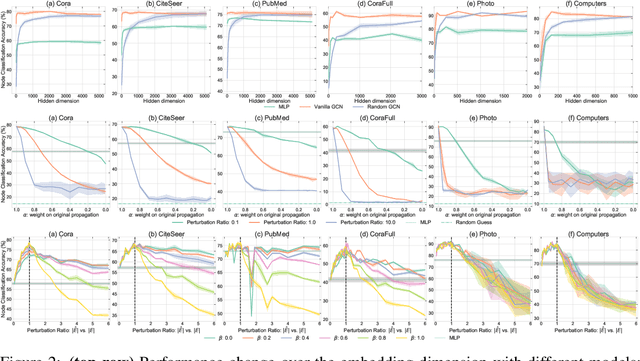
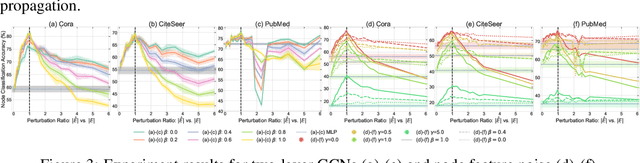
The robustness of the much-used Graph Convolutional Networks (GCNs) to perturbations of their input is becoming a topic of increasing importance. In this paper, the random GCN is introduced for which a random matrix theory analysis is possible. This analysis suggests that if the graph is sufficiently perturbed, or in the extreme case random, then the GCN fails to benefit from the node features. It is furthermore observed that enhancing the message passing step in GCNs by adding the node feature kernel to the adjacency matrix of the graph structure solves this problem. An empirical study of a GCN utilised for node classification on six real datasets further confirms the theoretical findings and demonstrates that perturbations of the graph structure can result in GCNs performing significantly worse than Multi-Layer Perceptrons run on the node features alone. In practice, adding a node feature kernel to the message passing of perturbed graphs results in a significant improvement of the GCN's performance, thereby rendering it more robust to graph perturbations. Our code is publicly available at:https://github.com/ChangminWu/RobustGCN.
Sparsifying the Update Step in Graph Neural Networks
Sep 02, 2021

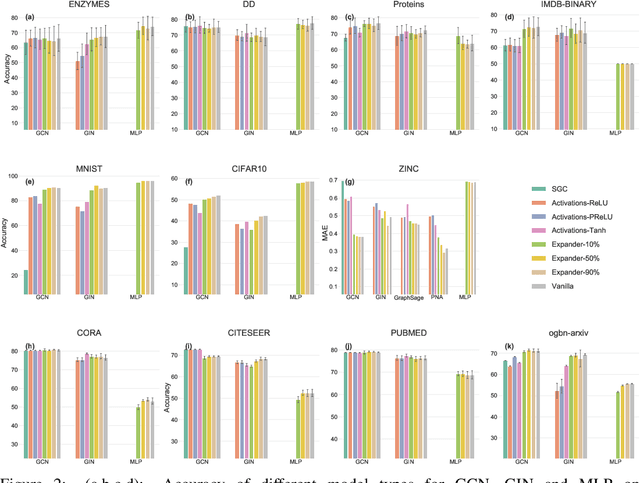
Message-Passing Neural Networks (MPNNs), the most prominent Graph Neural Network (GNN) framework, celebrate much success in the analysis of graph-structured data. Concurrently, the sparsification of Neural Network models attracts a great amount of academic and industrial interest. In this paper, we conduct a structured study of the effect of sparsification on the trainable part of MPNNs known as the Update step. To this end, we design a series of models to successively sparsify the linear transform in the Update step. Specifically, we propose the ExpanderGNN model with a tuneable sparsification rate and the Activation-Only GNN, which has no linear transform in the Update step. In agreement with a growing trend in the literature, the sparsification paradigm is changed by initialising sparse neural network architectures rather than expensively sparsifying already trained architectures. Our novel benchmark models enable a better understanding of the influence of the Update step on model performance and outperform existing simplified benchmark models such as the Simple Graph Convolution. The ExpanderGNNs, and in some cases the Activation-Only models, achieve performance on par with their vanilla counterparts on several downstream tasks while containing significantly fewer trainable parameters. In experiments with matching parameter numbers, our benchmark models outperform the state-of-the-art GNN models. Our code is publicly available at: https://github.com/ChangminWu/ExpanderGNN.
Learning to Maximize Influence
Aug 10, 2021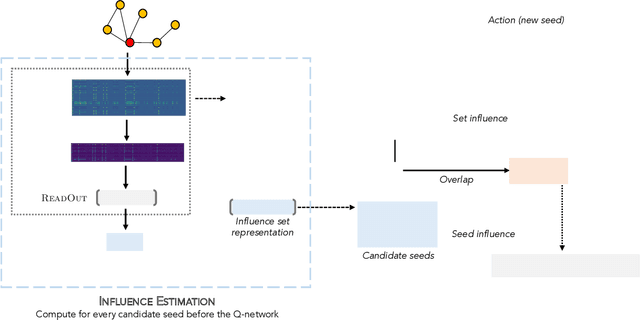

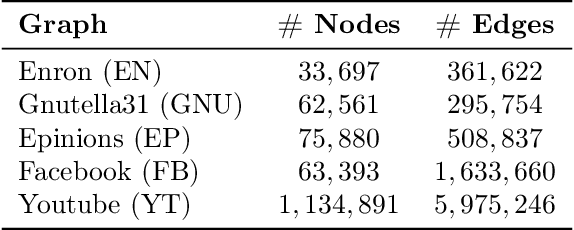
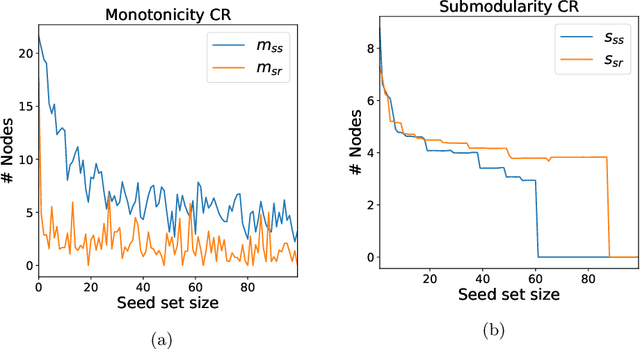
As the field of machine learning for combinatorial optimization advances, traditional problems are resurfaced and readdressed through this new perspective. The overwhelming majority of the literature focuses on small graph problems, while several real-world problems are devoted to large graphs. Here, we focus on two such problems that are related: influence estimation, a \#P-hard counting problem, and influence maximization, an NP-hard problem. We develop GLIE, a Graph Neural Network (GNN) that inherently parameterizes an upper bound of influence estimation and train it on small simulated graphs. Experiments show that GLIE can provide accurate predictions faster than the alternatives for graphs 10 times larger than the train set. More importantly, it can be used on arbitrary large graphs for influence maximization, as the predictions can rank effectively seed sets even when the accuracy deteriorates. To showcase this, we propose a version of a standard Influence Maximization (IM) algorithm where we substitute traditional influence estimation with the predictions of GLIE.We also transfer GLIE into a reinforcement learning model that learns how to choose seeds to maximize influence sequentially using GLIE's hidden representations and predictions. The final results show that the proposed methods surpasses a previous GNN-RL approach and perform on par with a state-of-the-art IM algorithm.
Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
Aug 02, 2021
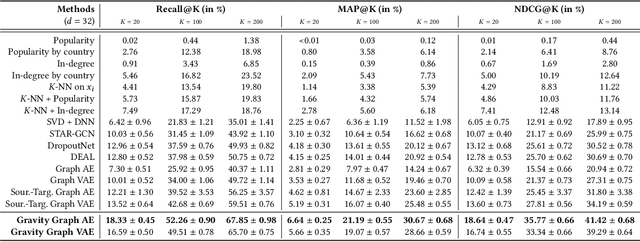
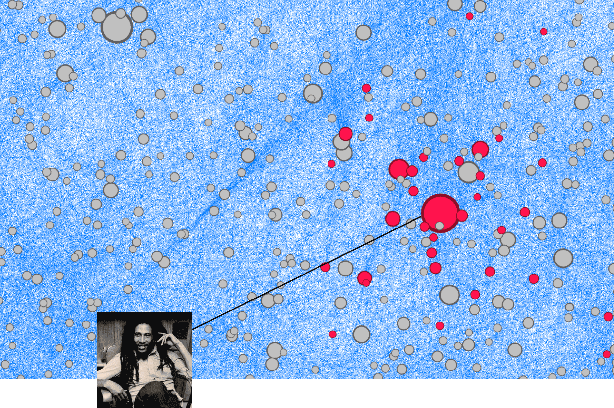
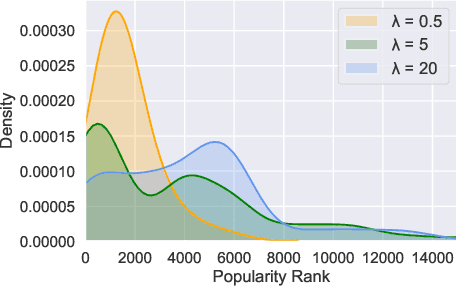
On an artist's profile page, music streaming services frequently recommend a ranked list of "similar artists" that fans also liked. However, implementing such a feature is challenging for new artists, for which usage data on the service (e.g. streams or likes) is not yet available. In this paper, we model this cold start similar artists ranking problem as a link prediction task in a directed and attributed graph, connecting artists to their top-k most similar neighbors and incorporating side musical information. Then, we leverage a graph autoencoder architecture to learn node embedding representations from this graph, and to automatically rank the top-k most similar neighbors of new artists using a gravity-inspired mechanism. We empirically show the flexibility and the effectiveness of our framework, by addressing a real-world cold start similar artists ranking problem on a global music streaming service. Along with this paper, we also publicly release our source code as well as the industrial graph data from our experiments.
Operation Embeddings for Neural Architecture Search
May 11, 2021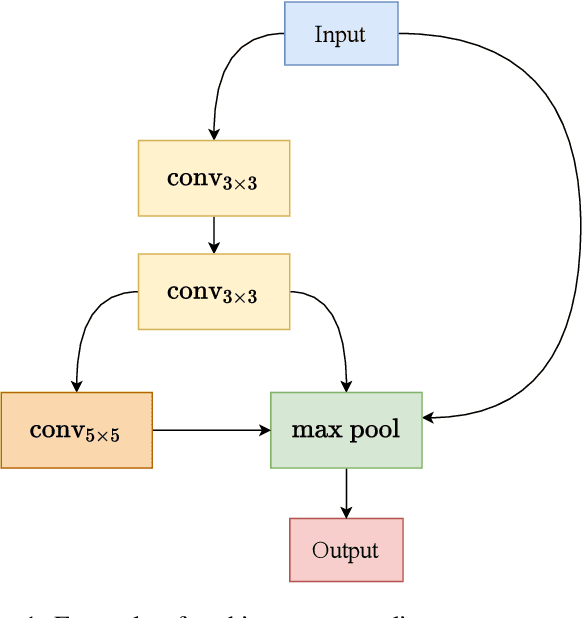
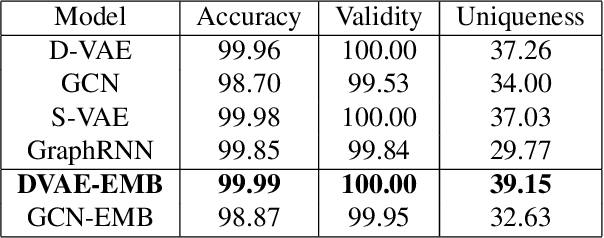
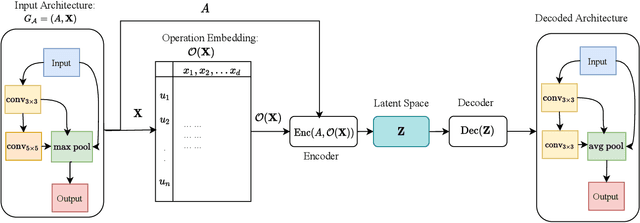
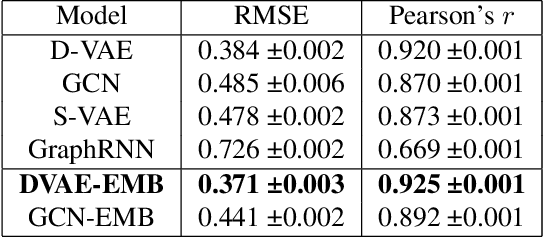
Neural Architecture Search (NAS) has recently gained increased attention, as a class of approaches that automatically searches in an input space of network architectures. A crucial part of the NAS pipeline is the encoding of the architecture that consists of the applied computational blocks, namely the operations and the links between them. Most of the existing approaches either fail to capture the structural properties of the architectures or use a hand-engineered vector to encode the operator information. In this paper, we propose the replacement of fixed operator encoding with learnable representations in the optimization process. This approach, which effectively captures the relations of different operations, leads to smoother and more accurate representations of the architectures and consequently to improved performance of the end task. Our extensive evaluation in ENAS benchmark demonstrates the effectiveness of the proposed operation embeddings to the generation of highly accurate models, achieving state-of-the-art performance. Finally, our method produces top-performing architectures that share similar operation and graph patterns, highlighting a strong correlation between architecture's structural properties and performance.
Evaluation Of Word Embeddings From Large-Scale French Web Content
May 05, 2021

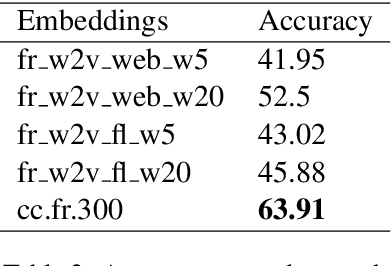
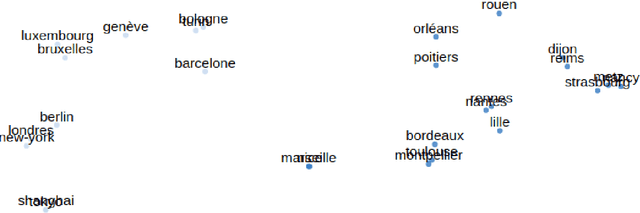
Distributed word representations are popularly used in many tasks in natural language processing, adding that pre-trained word vectors on huge text corpus achieved high performance in many different NLP tasks. This paper introduces multiple high quality word vectors for the French language where two of them are trained on huge crawled French data and the others are trained on an already existing French corpus. We also evaluate the quality of our proposed word vectors and the existing French word vectors on the French word analogy task. In addition, we do the evaluation on multiple real NLP tasks that show the important performance enhancement of the pre-trained word vectors compared to the existing and random ones. Finally, we created a demo web application to test and visualize the obtained word embeddings. The produced French word embeddings are available to the public, along with the fine-tuning code on the NLU tasks and the demo code.
Ego-based Entropy Measures for Structural Representations on Graphs
Feb 17, 2021
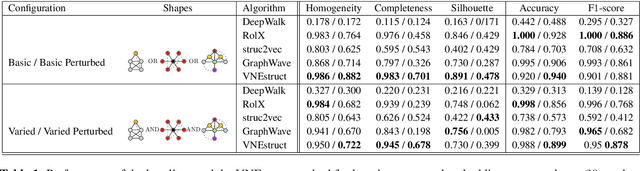
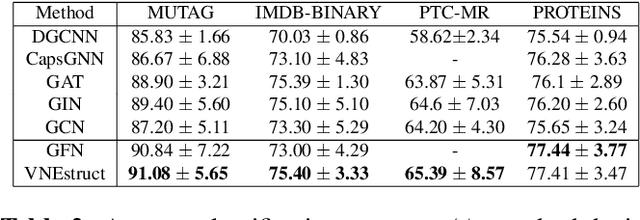
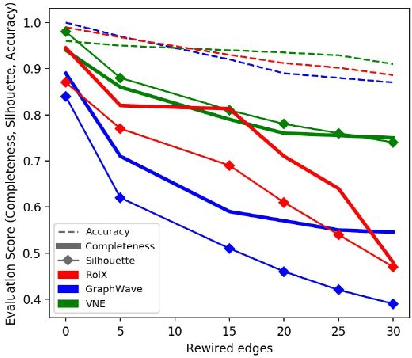
Machine learning on graph-structured data has attracted high research interest due to the emergence of Graph Neural Networks (GNNs). Most of the proposed GNNs are based on the node homophily, i.e neighboring nodes share similar characteristics. However, in many complex networks, nodes that lie to distant parts of the graph share structurally equivalent characteristics and exhibit similar roles (e.g chemical properties of distant atoms in a molecule, type of social network users). A growing literature proposed representations that identify structurally equivalent nodes. However, most of the existing methods require high time and space complexity. In this paper, we propose VNEstruct, a simple approach, based on entropy measures of the neighborhood's topology, for generating low-dimensional structural representations, that is time-efficient and robust to graph perturbations. Empirically, we observe that VNEstruct exhibits robustness on structural role identification tasks. Moreover, VNEstruct can achieve state-of-the-art performance on graph classification, without incorporating the graph structure information in the optimization, in contrast to GNN competitors.