 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Sense Induction with Hierarchical Clustering and Mutual Information Maximization
Oct 11, 2022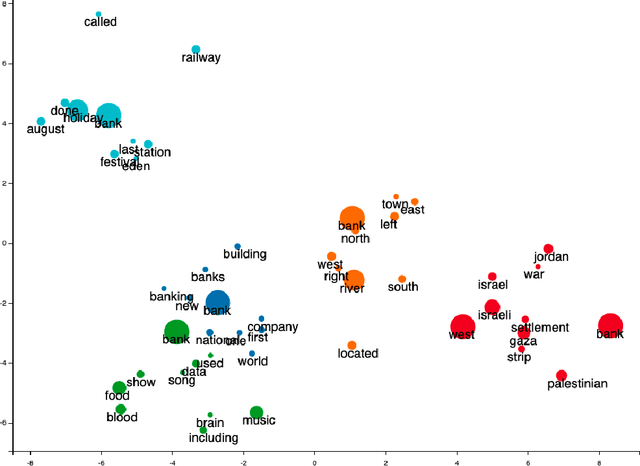
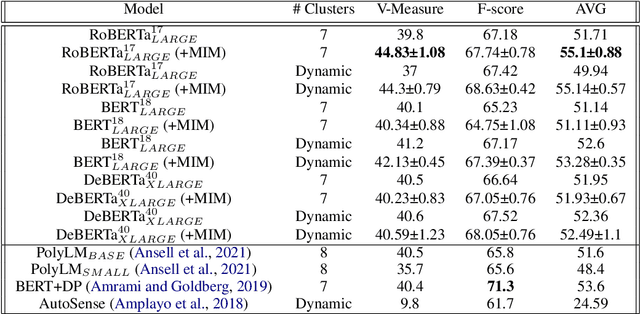
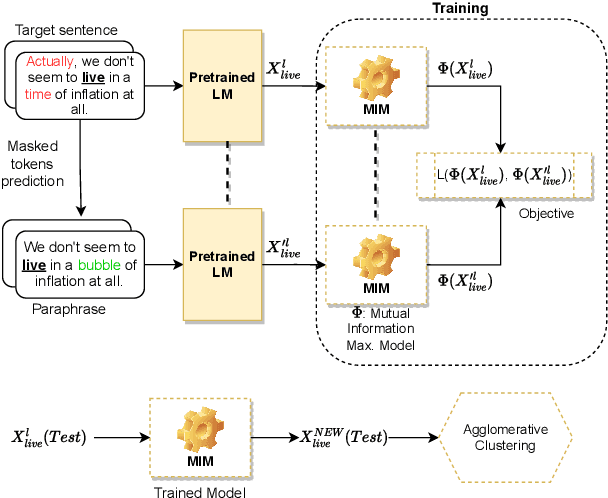
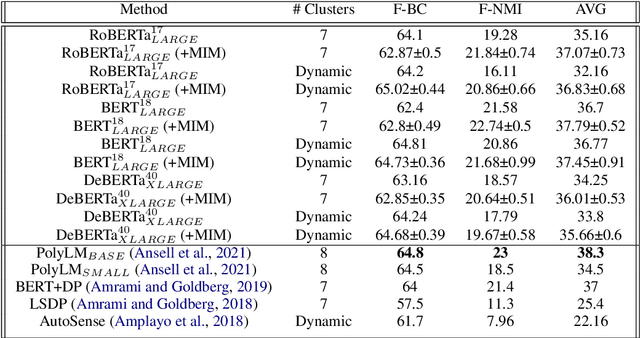
Word sense induction (WSI) is a difficult problem in natural language processing that involves the unsupervised automatic detection of a word's senses (i.e. meanings). Recent work achieves significant results on the WSI task by pre-training a language model that can exclusively disambiguate word senses, whereas others employ previously pre-trained language models in conjunction with additional strategies to induce senses. In this paper, we propose a novel unsupervised method based on hierarchical clustering and invariant information clustering (IIC). The IIC is used to train a small model to optimize the mutual information between two vector representations of a target word occurring in a pair of synthetic paraphrases. This model is later used in inference mode to extract a higher quality vector representation to be used in the hierarchical clustering. We evaluate our method on two WSI tasks and in two distinct clustering configurations (fixed and dynamic number of clusters). We empirically demonstrate that, in certain cases, our approach outperforms prior WSI state-of-the-art methods, while in others, it achieves a competitive performance.
Abstractive Meeting Summarization: A Survey
Aug 08, 2022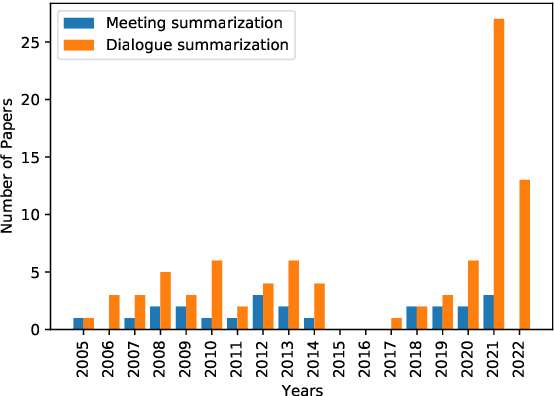
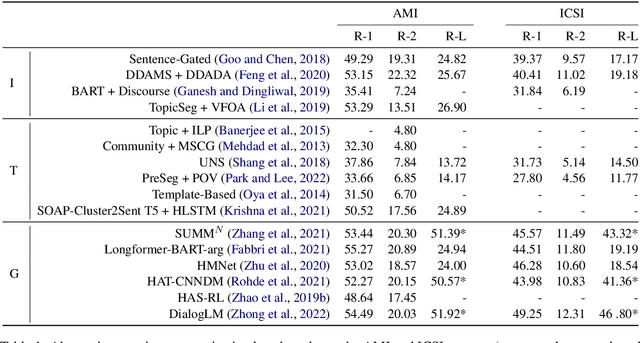
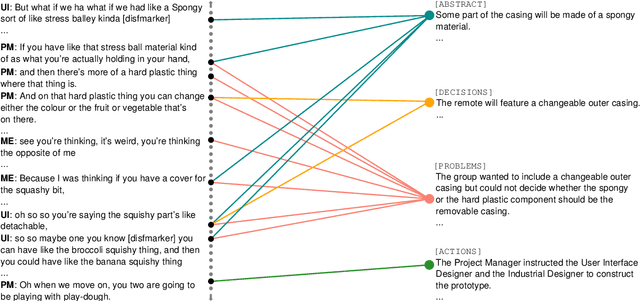
Recent advances in deep learning, and especially the invention of encoder-decoder architectures, has significantly improved the performance of abstractive summarization systems. While the majority of research has focused on written documents, we have observed an increasing interest in the summarization of dialogues and multi-party conversation over the past few years. A system that could reliably transform the audio or transcript of a human conversation into an abridged version that homes in on the most important points of the discussion would be valuable in a wide variety of real-world contexts, from business meetings to medical consultations to customer service calls. This paper focuses on abstractive summarization for multi-party meetings, providing a survey of the challenges, datasets and systems relevant to this task and a discussion of promising directions for future study.
Time Series Forecasting Models Copy the Past: How to Mitigate
Jul 27, 2022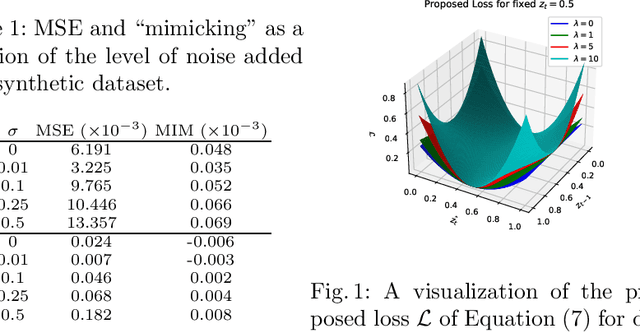
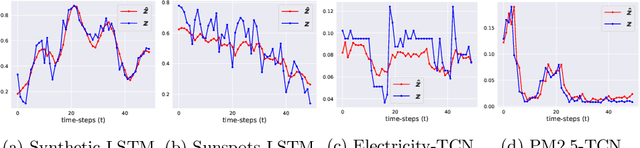
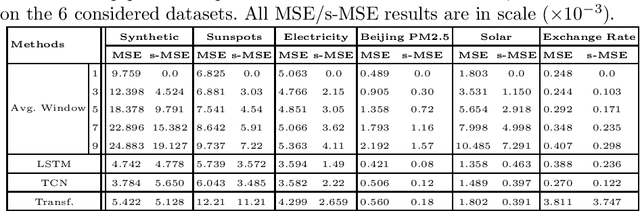
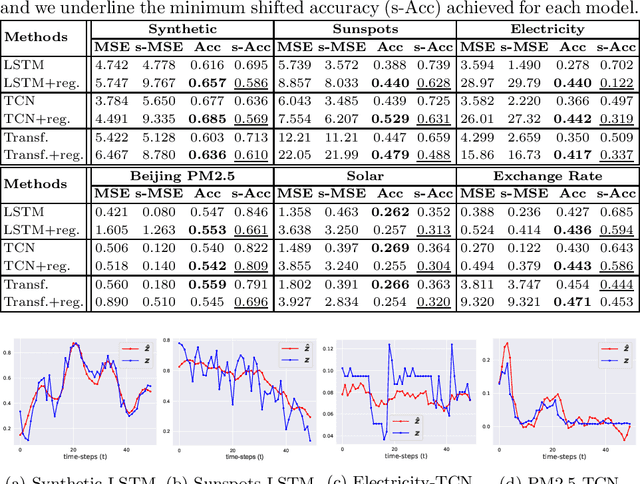
Time series forecasting is at the core of important application domains posing significant challenges to machine learning algorithms. Recently neural network architectures have been widely applied to the problem of time series forecasting. Most of these models are trained by minimizing a loss function that measures predictions' deviation from the real values. Typical loss functions include mean squared error (MSE) and mean absolute error (MAE). In the presence of noise and uncertainty, neural network models tend to replicate the last observed value of the time series, thus limiting their applicability to real-world data. In this paper, we provide a formal definition of the above problem and we also give some examples of forecasts where the problem is observed. We also propose a regularization term penalizing the replication of previously seen values. We evaluate the proposed regularization term both on synthetic and real-world datasets. Our results indicate that the regularization term mitigates to some extent the aforementioned problem and gives rise to more robust models.
Image Keypoint Matching using Graph Neural Networks
May 27, 2022Image matching is a key component of many tasks in computer vision and its main objective is to find correspondences between features extracted from different natural images. When images are represented as graphs, image matching boils down to the problem of graph matching which has been studied intensively in the past. In recent years, graph neural networks have shown great potential in the graph matching task, and have also been applied to image matching. In this paper, we propose a graph neural network for the problem of image matching. The proposed method first generates initial soft correspondences between keypoints using localized node embeddings and then iteratively refines the initial correspondences using a series of graph neural network layers. We evaluate our method on natural image datasets with keypoint annotations and show that, in comparison to a state-of-the-art model, our method speeds up inference times without sacrificing prediction accuracy.
Political Communities on Twitter: Case Study of the 2022 French Presidential Election
Apr 15, 2022
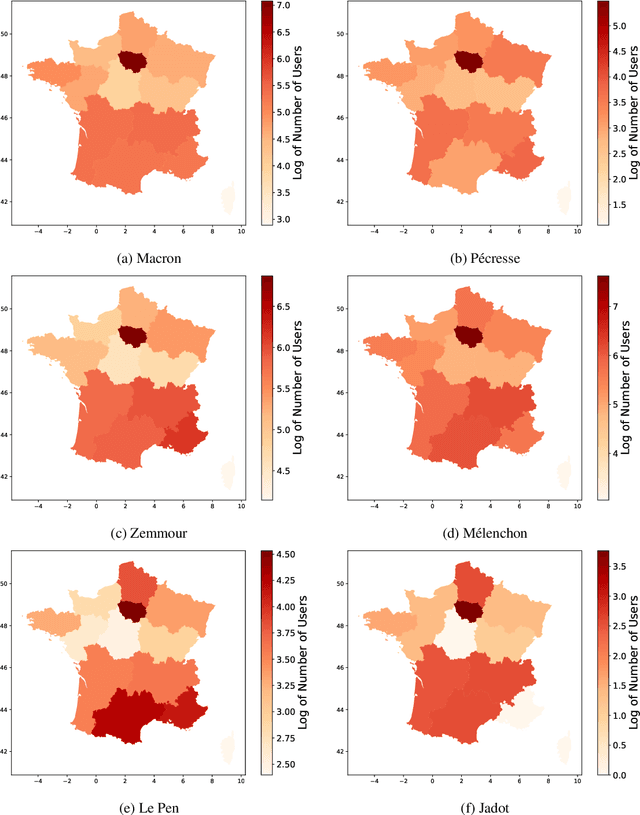
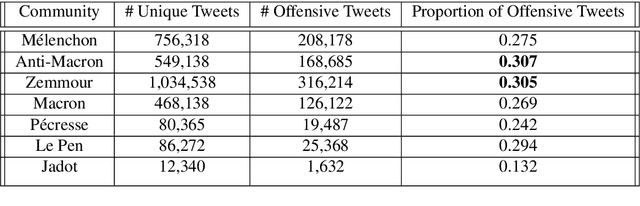
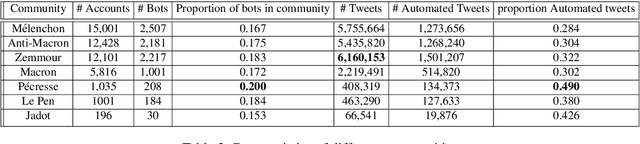
With the significant increase in users on social media platforms, a new means of political campaigning has appeared. Twitter and Facebook are now notable campaigning tools during elections. Indeed, the candidates and their parties now take to the internet to interact and spread their ideas. In this paper, we aim to identify political communities formed on Twitter during the 2022 French presidential election and analyze each respective community. We create a large-scale Twitter dataset containing 1.2 million users and 62.6 million tweets that mention keywords relevant to the election. We perform community detection on a retweet graph of users and propose an in-depth analysis of the stance of each community. Finally, we attempt to detect offensive tweets and automatic bots, comparing across communities in order to gain insight into each candidate's supporter demographics and online campaign strategy.
Graph Ordering Attention Networks
Apr 11, 2022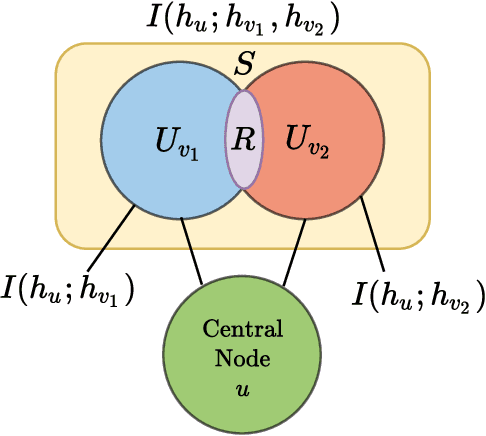
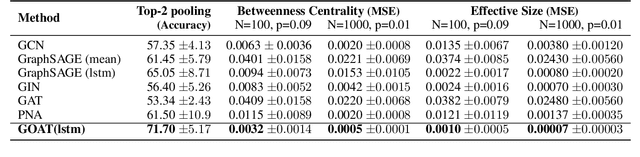

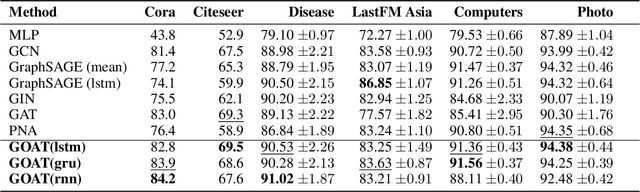
Graph Neural Networks (GNNs) have been successfully used in many problems involving graph-structured data, achieving state-of-the-art performance. GNNs typically employ a message-passing scheme, in which every node aggregates information from its neighbors using a permutation-invariant aggregation function. Standard well-examined choices such as the mean or sum aggregation functions have limited capabilities, as they are not able to capture interactions among neighbors. In this work, we formalize these interactions using an information-theoretic framework that notably includes synergistic information. Driven by this definition, we introduce the Graph Ordering Attention (GOAT) layer, a novel GNN component that captures interactions between nodes in a neighborhood. This is achieved by learning local node orderings via an attention mechanism and processing the ordered representations using a recurrent neural network aggregator. This design allows us to make use of a permutation-sensitive aggregator while maintaining the permutation-equivariance of the proposed GOAT layer. The GOAT model demonstrates its increased performance in modeling graph metrics that capture complex information, such as the betweenness centrality and the effective size of a node. In practical use-cases, its superior modeling capability is confirmed through its success in several real-world node classification benchmarks.
AraBART: a Pretrained Arabic Sequence-to-Sequence Model for Abstractive Summarization
Mar 21, 2022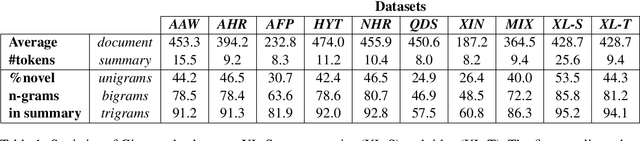
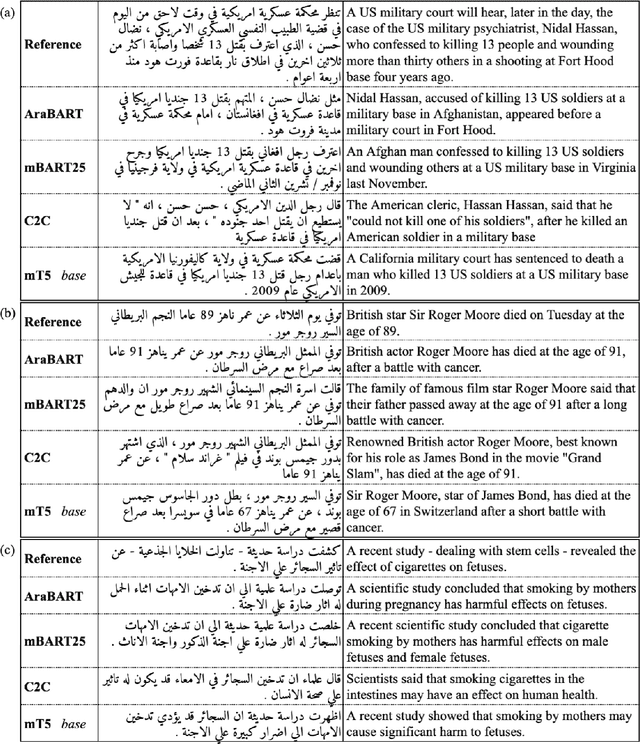
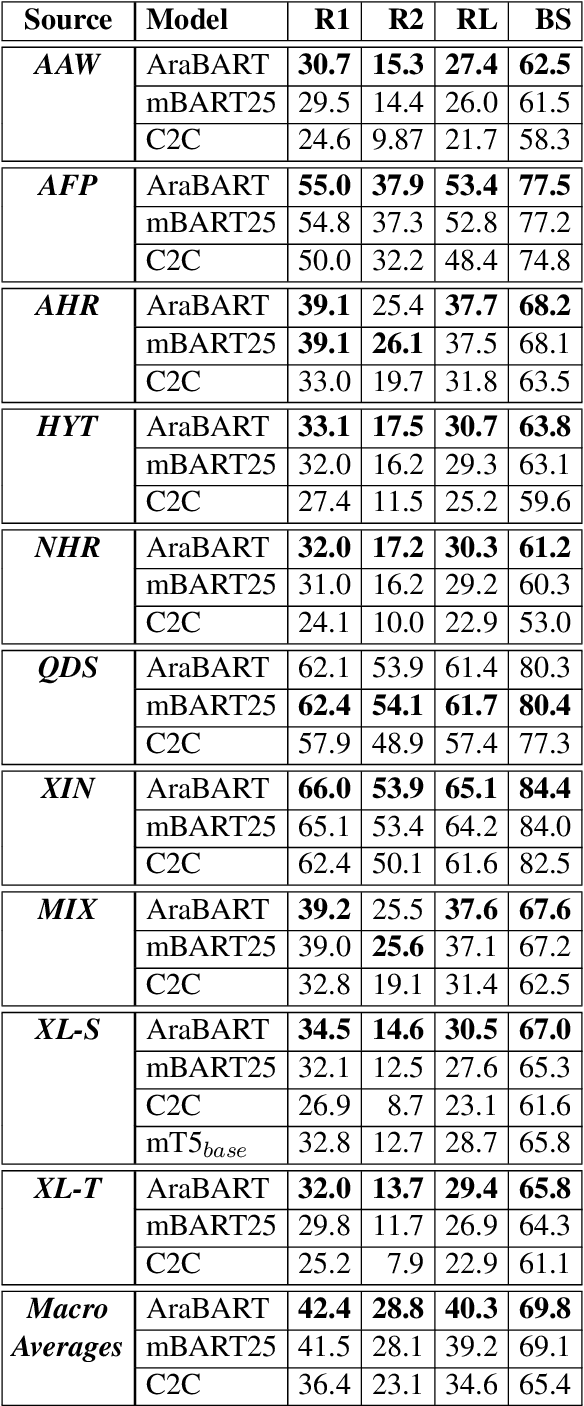
Like most natural language understanding and generation tasks, state-of-the-art models for summarization are transformer-based sequence-to-sequence architectures that are pretrained on large corpora. While most existing models focused on English, Arabic remained understudied. In this paper we propose AraBART, the first Arabic model in which the encoder and the decoder are pretrained end-to-end, based on BART. We show that AraBART achieves the best performance on multiple abstractive summarization datasets, outperforming strong baselines including a pretrained Arabic BERT-based model and multilingual mBART and mT5 models.
Modularity-Aware Graph Autoencoders for Joint Community Detection and Link Prediction
Feb 02, 2022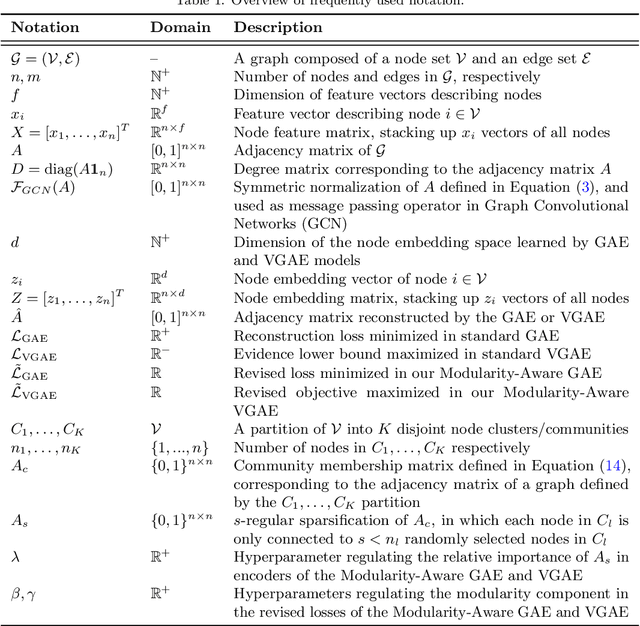
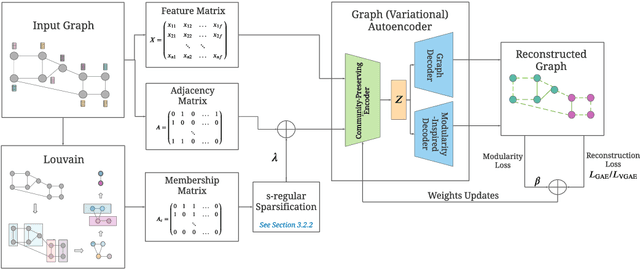

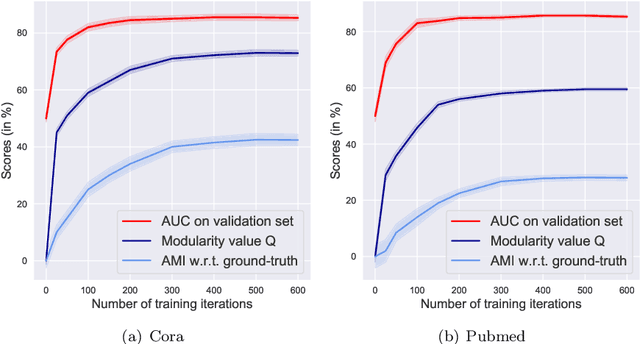
Graph autoencoders (GAE) and variational graph autoencoders (VGAE) emerged as powerful methods for link prediction. Their performances are less impressive on community detection problems where, according to recent and concurring experimental evaluations, they are often outperformed by simpler alternatives such as the Louvain method. It is currently still unclear to which extent one can improve community detection with GAE and VGAE, especially in the absence of node features. It is moreover uncertain whether one could do so while simultaneously preserving good performances on link prediction. In this paper, we show that jointly addressing these two tasks with high accuracy is possible. For this purpose, we introduce and theoretically study a community-preserving message passing scheme, doping our GAE and VGAE encoders by considering both the initial graph structure and modularity-based prior communities when computing embedding spaces. We also propose novel training and optimization strategies, including the introduction of a modularity-inspired regularizer complementing the existing reconstruction losses for joint link prediction and community detection. We demonstrate the empirical effectiveness of our approach, referred to as Modularity-Aware GAE and VGAE, through in-depth experimental validation on various real-world graphs.
NLP Research and Resources at DaSciM, Ecole Polytechnique
Dec 01, 2021DaSciM (Data Science and Mining) part of LIX at Ecole Polytechnique, established in 2013 and since then producing research results in the area of large scale data analysis via methods of machine and deep learning. The group has been specifically active in the area of NLP and text mining with interesting results at methodological and resources level. Here follow our different contributions of interest to the AFIA community.
FrugalScore: Learning Cheaper, Lighter and Faster Evaluation Metricsfor Automatic Text Generation
Oct 16, 2021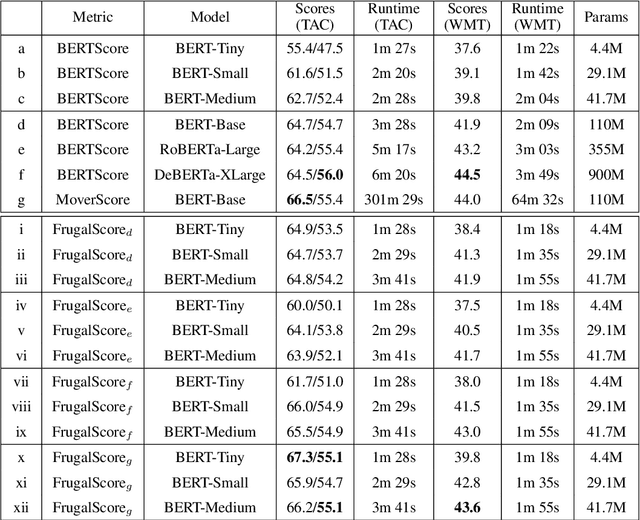
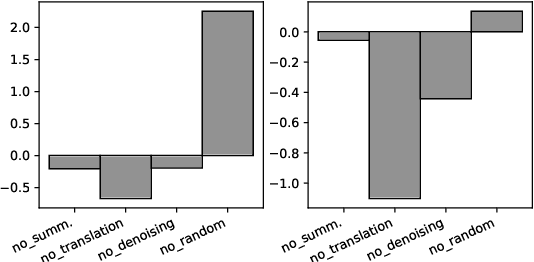
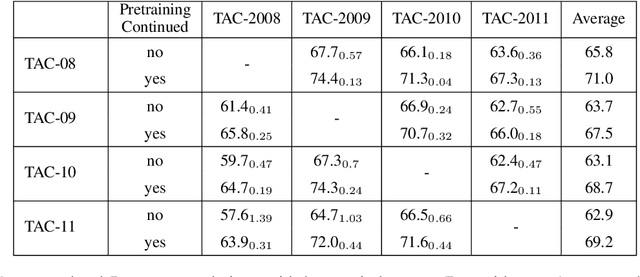
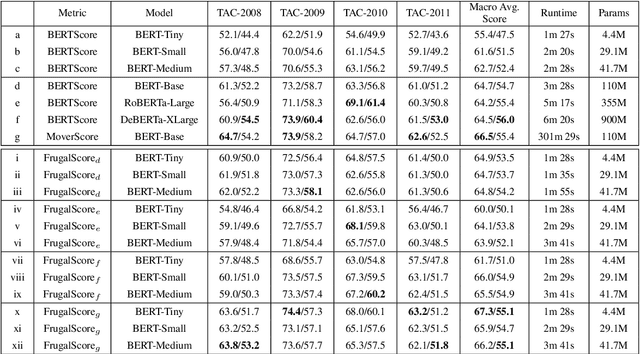
Fast and reliable evaluation metrics are key to R&D progress. While traditional natural language generation metrics are fast, they are not very reliable. Conversely, new metrics based on large pretrained language models are much more reliable, but require significant computational resources. In this paper, we propose FrugalScore, an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance. Experiments with BERTScore and MoverScore on summarization and translation show that FrugalScore is on par with the original metrics (and sometimes better), while having several orders of magnitude less parameters and running several times faster. On average over all learned metrics, tasks, and variants, FrugalScore retains 96.8% of the performance, runs 24 times faster, and has 35 times less parameters than the original metrics. We make our trained metrics publicly available, to benefit the entire NLP community and in particular researchers and practitioners with limited resources.