 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference of Quantized Neural Networks on Heterogeneous All-Programmable Devices
Jun 21, 2018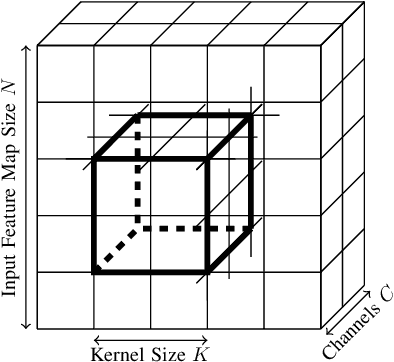
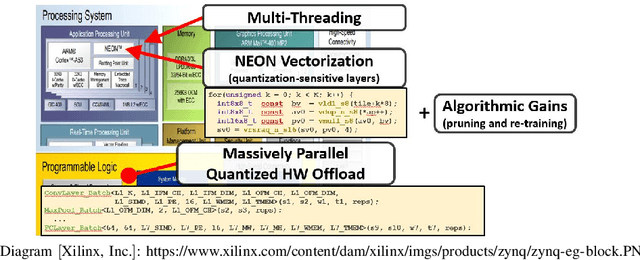
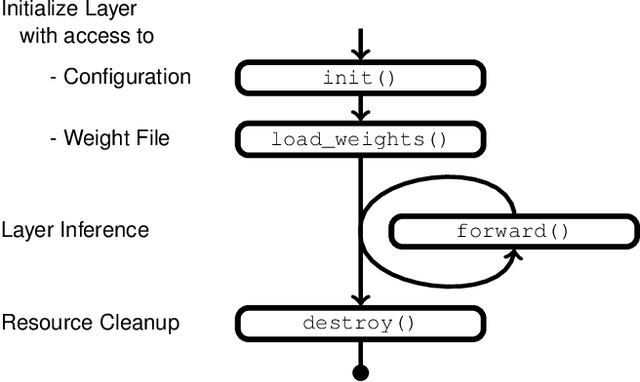

Neural networks have established as a generic and powerful means to approach challenging problems such as image classification, object detection or decision making. Their successful employment foots on an enormous demand of compute. The quantization of network parameters and the processed data has proven a valuable measure to reduce the challenges of network inference so effectively that the feasible scope of applications is expanded even into the embedded domain. This paper describes the making of a real-time object detection in a live video stream processed on an embedded all-programmable device. The presented case illustrates how the required processing is tamed and parallelized across both the CPU cores and the programmable logic and how the most suitable resources and powerful extensions, such as NEON vectorization, are leveraged for the individual processing steps. The crafted result is an extended Darknet framework implementing a fully integrated, end-to-end solution from video capture over object annotation to video output applying neural network inference at different quantization levels running at 16~frames per second on an embedded Zynq UltraScale+ (XCZU3EG) platform.
Compressing Low Precision Deep Neural Networks Using Sparsity-Induced Regularization in Ternary Networks
Oct 10, 2017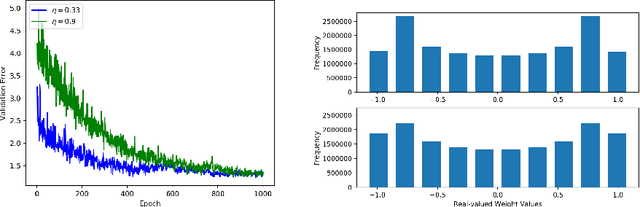
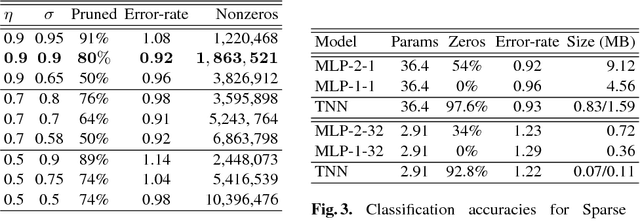
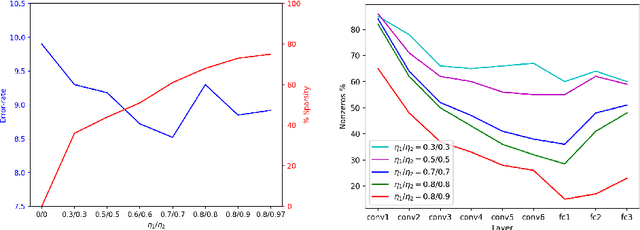
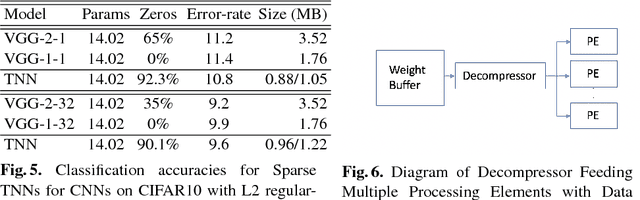
A low precision deep neural network training technique for producing sparse, ternary neural networks is presented. The technique incorporates hard- ware implementation costs during training to achieve significant model compression for inference. Training involves three stages: network training using L2 regularization and a quantization threshold regularizer, quantization pruning, and finally retraining. Resulting networks achieve improved accuracy, reduced memory footprint and reduced computational complexity compared with conventional methods, on MNIST and CIFAR10 datasets. Our networks are up to 98% sparse and 5 & 11 times smaller than equivalent binary and ternary models, translating to significant resource and speed benefits for hardware implementations.
Scaling Binarized Neural Networks on Reconfigurable Logic
Jan 27, 2017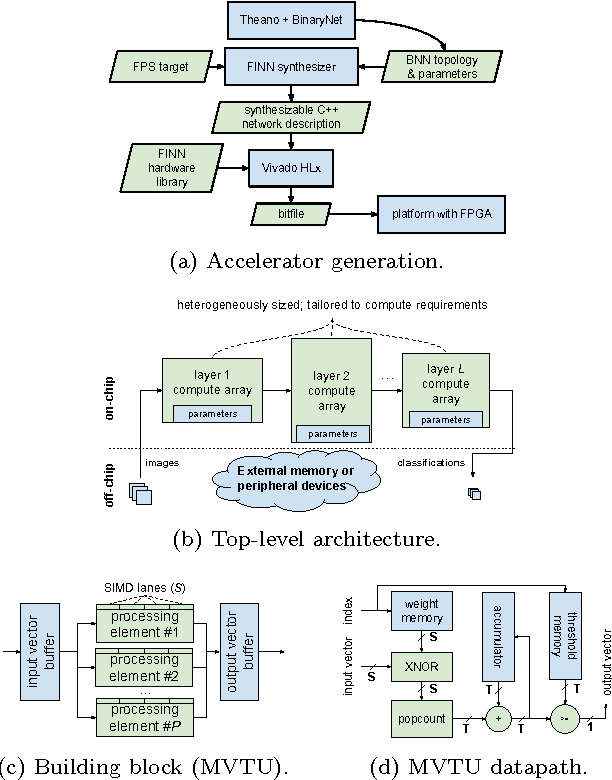

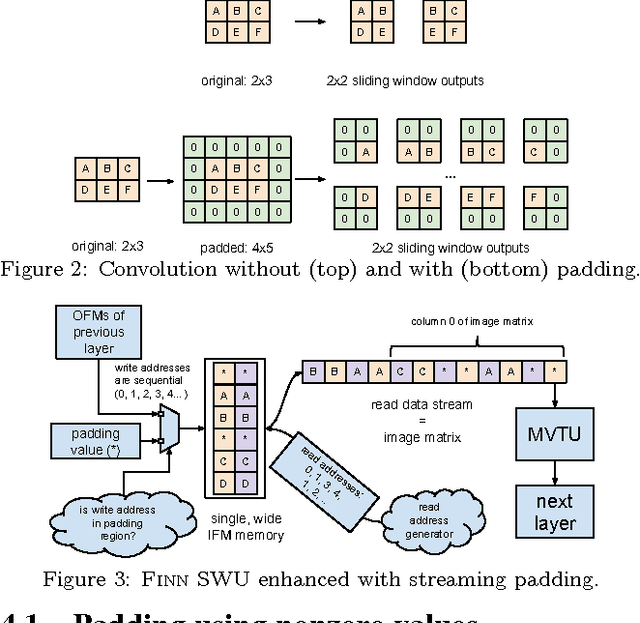
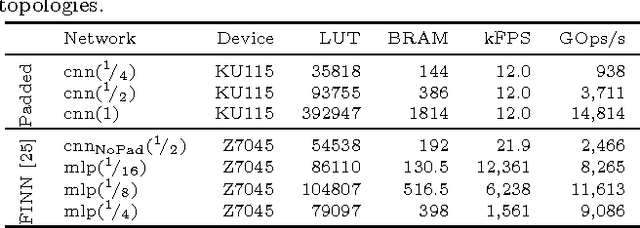
Binarized neural networks (BNNs) are gaining interest in the deep learning community due to their significantly lower computational and memory cost. They are particularly well suited to reconfigurable logic devices, which contain an abundance of fine-grained compute resources and can result in smaller, lower power implementations, or conversely in higher classification rates. Towards this end, the Finn framework was recently proposed for building fast and flexible field programmable gate array (FPGA) accelerators for BNNs. Finn utilized a novel set of optimizations that enable efficient mapping of BNNs to hardware and implemented fully connected, non-padded convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. However, FINN was not evaluated on larger topologies due to the size of the chosen FPGA, and exhibited decreased accuracy due to lack of padding. In this paper, we improve upon Finn to show how padding can be employed on BNNs while still maintaining a 1-bit datapath and high accuracy. Based on this technique, we demonstrate numerous experiments to illustrate flexibility and scalability of the approach. In particular, we show that a large BNN requiring 1.2 billion operations per frame running on an ADM-PCIE-8K5 platform can classify images at 12 kFPS with 671 us latency while drawing less than 41 W board power and classifying CIFAR-10 images at 88.7% accuracy. Our implementation of this network achieves 14.8 trillion operations per second. We believe this is the fastest classification rate reported to date on this benchmark at this level of accuracy.
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
Dec 01, 2016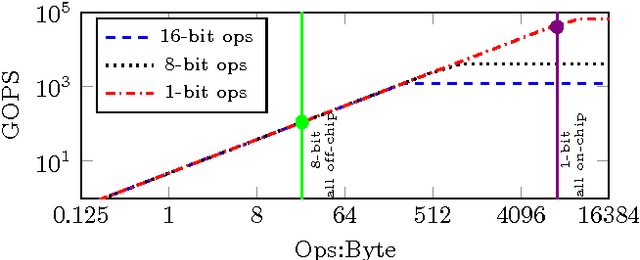

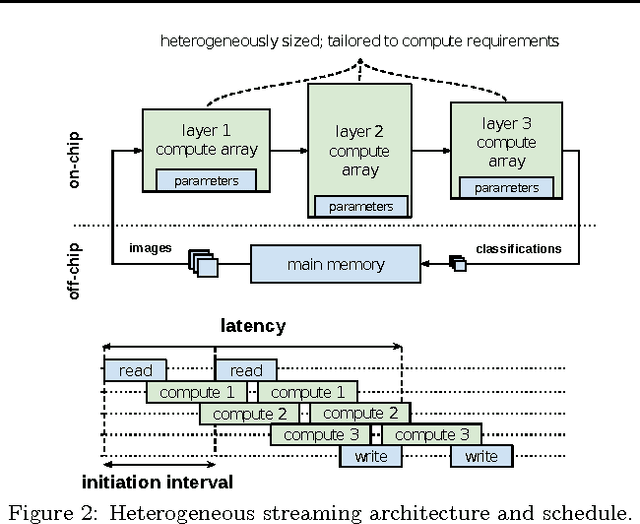
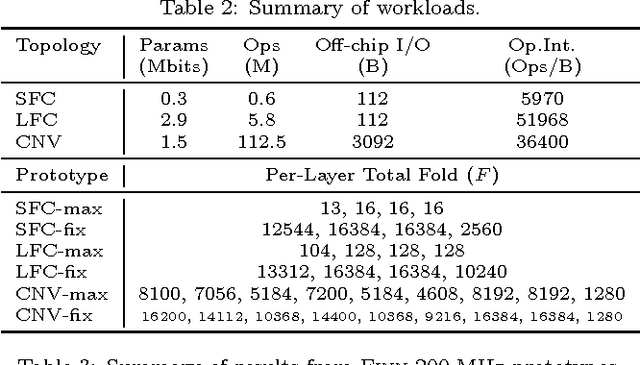
Research has shown that convolutional neural networks contain significant redundancy, and high classification accuracy can be obtained even when weights and activations are reduced from floating point to binary values. In this paper, we present FINN, a framework for building fast and flexible FPGA accelerators using a flexible heterogeneous streaming architecture. By utilizing a novel set of optimizations that enable efficient mapping of binarized neural networks to hardware, we implement fully connected, convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. On a ZC706 embedded FPGA platform drawing less than 25 W total system power, we demonstrate up to 12.3 million image classifications per second with 0.31 {\mu}s latency on the MNIST dataset with 95.8% accuracy, and 21906 image classifications per second with 283 {\mu}s latency on the CIFAR-10 and SVHN datasets with respectively 80.1% and 94.9% accuracy. To the best of our knowledge, ours are the fastest classification rates reported to date on these benchmarks.