 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent variable modeling with random features
Jun 19, 2020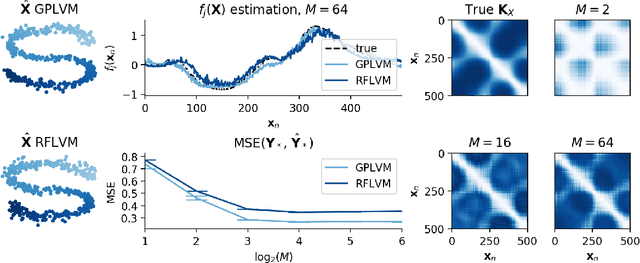
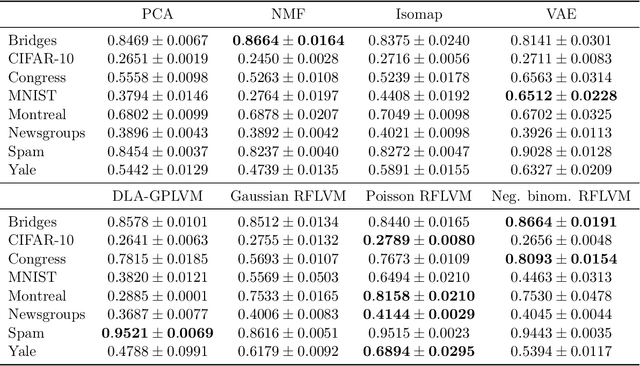
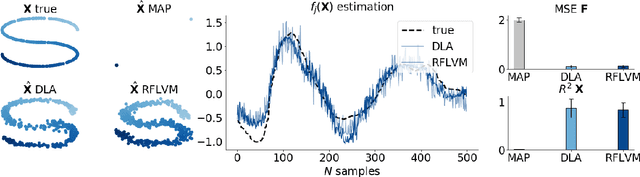
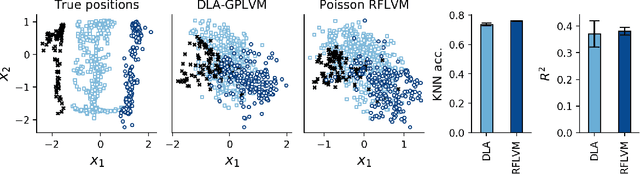
Gaussian process-based latent variable models are flexible and theoretically grounded tools for nonlinear dimension reduction, but generalizing to non-Gaussian data likelihoods within this nonlinear framework is statistically challenging. Here, we use random features to develop a family of nonlinear dimension reduction models that are easily extensible to non-Gaussian data likelihoods; we call these random feature latent variable models (RFLVMs). By approximating a nonlinear relationship between the latent space and the observations with a function that is linear with respect to random features, we induce closed-form gradients of the posterior distribution with respect to the latent variable. This allows the RFLVM framework to support computationally tractable nonlinear latent variable models for a variety of data likelihoods in the exponential family without specialized derivations. Our generalized RFLVMs produce results comparable with other state-of-the-art dimension reduction methods on diverse types of data, including neural spike train recordings, images, and text data.
Distributed, partially collapsed MCMC for Bayesian Nonparametrics
Jan 15, 2020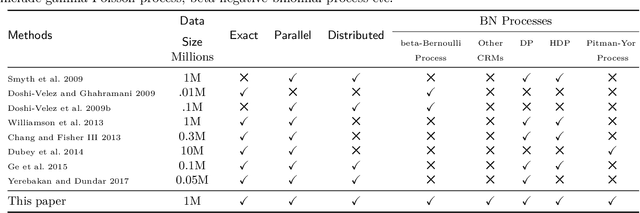
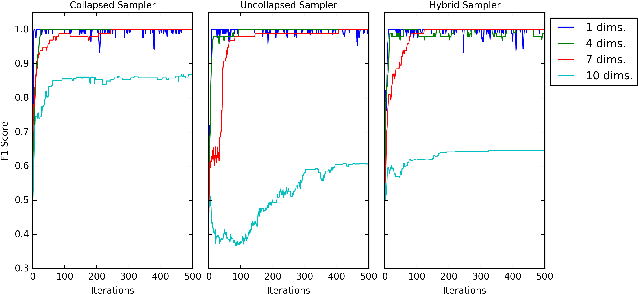

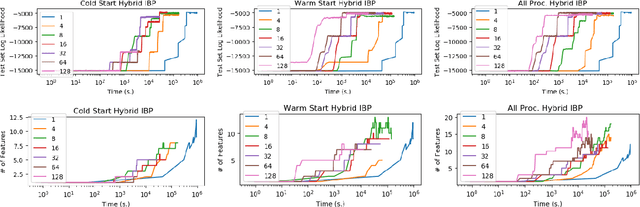
Bayesian nonparametric (BNP) models provide elegant methods for discovering underlying latent features within a data set, but inference in such models can be slow. We exploit the fact that completely random measures, which commonly used models like the Dirichlet process and the beta-Bernoulli process can be expressed as, are decomposable into independent sub-measures. We use this decomposition to partition the latent measure into a finite measure containing only instantiated components, and an infinite measure containing all other components. We then select different inference algorithms for the two components: uncollapsed samplers mix well on the finite measure, while collapsed samplers mix well on the infinite, sparsely occupied tail. The resulting hybrid algorithm can be applied to a wide class of models, and can be easily distributed to allow scalable inference without sacrificing asymptotic convergence guarantees.
Probabilistic Time of Arrival Localization
Oct 15, 2019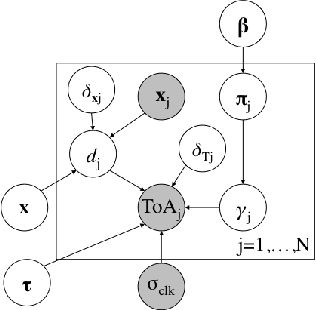

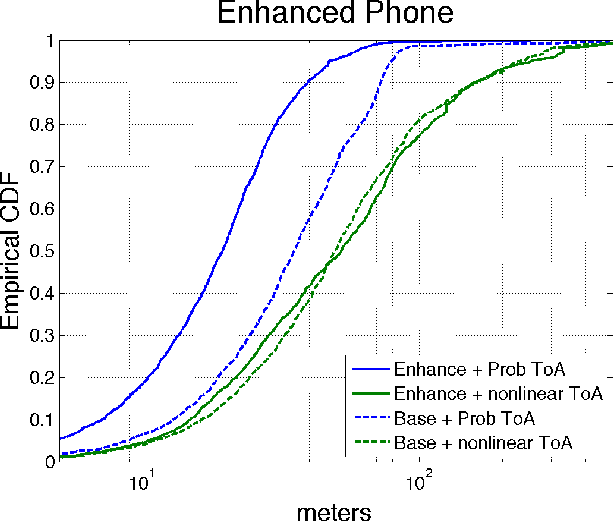
In this paper, we take a new approach for time of arrival geo-localization. We show that the main sources of error in metropolitan areas are due to environmental imperfections that bias our solutions, and that we can rely on a probabilistic model to learn and compensate for them. The resulting localization error is validated using measurements from a live LTE cellular network to be less than 10 meters, representing an order-of-magnitude improvement.
Sequential Gaussian Processes for Online Learning of Nonstationary Functions
May 24, 2019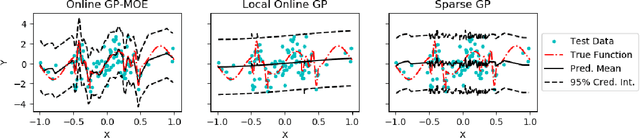
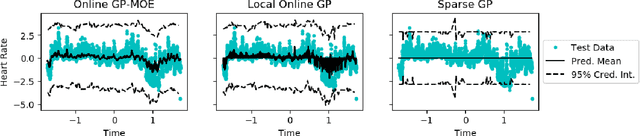
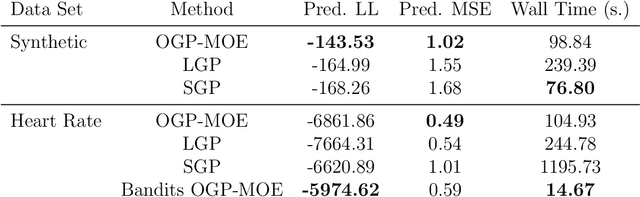
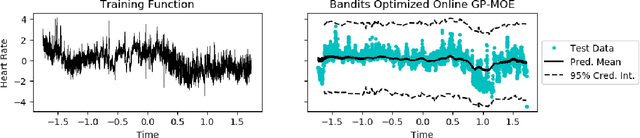
Many machine learning problems can be framed in the context of estimating functions, and often these are time-dependent functions that are estimated in real-time as observations arrive. Gaussian processes (GPs) are an attractive choice for modeling real-valued nonlinear functions due to their flexibility and uncertainty quantification. However, the typical GP regression model suffers from several drawbacks: i) Conventional GP inference scales $O(N^{3})$ with respect to the number of observations; ii) updating a GP model sequentially is not trivial; and iii) covariance kernels often enforce stationarity constraints on the function, while GPs with non-stationary covariance kernels are often intractable to use in practice. To overcome these issues, we propose an online sequential Monte Carlo algorithm to fit mixtures of GPs that capture non-stationary behavior while allowing for fast, distributed inference. By formulating hyperparameter optimization as a multi-armed bandit problem, we accelerate mixing for real time inference. Our approach empirically improves performance over state-of-the-art methods for online GP estimation in the context of prediction for simulated non-stationary data and hospital time series data.
A New Class of Time Dependent Latent Factor Models with Applications
Apr 18, 2019
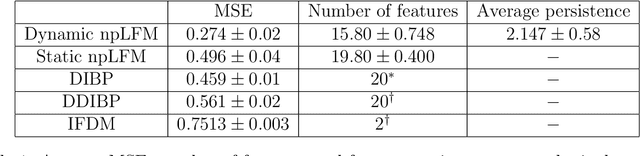
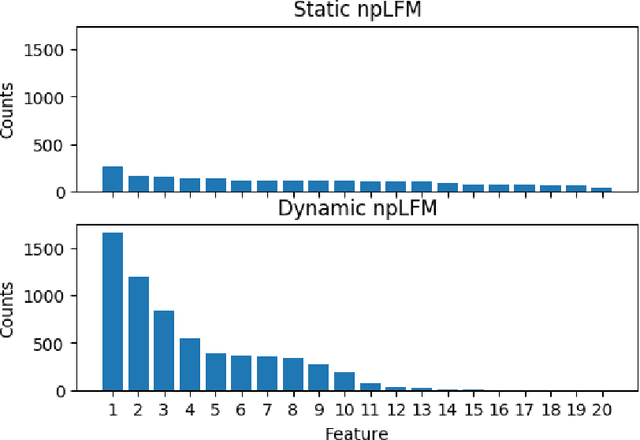

In many applications, observed data are influenced by some combination of latent causes. For example, suppose sensors are placed inside a building to record responses such as temperature, humidity, power consumption and noise levels. These random, observed responses are typically affected by many unobserved, latent factors (or features) within the building such as the number of individuals, the turning on and off of electrical devices, power surges, etc. These latent factors are usually present for a contiguous period of time before disappearing; further, multiple factors could be present at a time. This paper develops new probabilistic methodology and inference methods for random object generation influenced by latent features exhibiting temporal persistence. Every datum is associated with subsets of a potentially infinite number of hidden, persistent features that account for temporal dynamics in an observation. The ensuing class of dynamic models constructed by adapting the Indian Buffet Process --- a probability measure on the space of random, unbounded binary matrices --- finds use in a variety of applications arising in operations, signal processing, biomedicine, marketing, image analysis, etc. Illustrations using synthetic and real data are provided.
Communication Efficient Parallel Algorithms for Optimization on Manifolds
Nov 01, 2018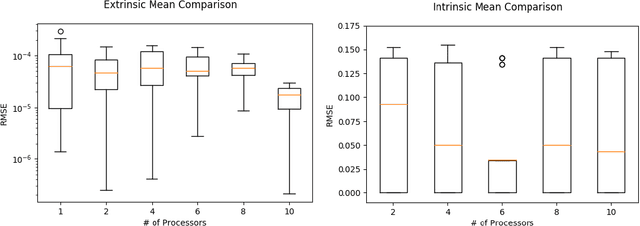
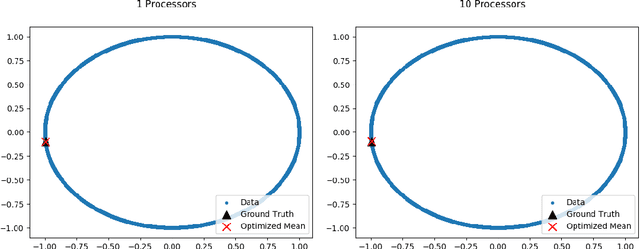
The last decade has witnessed an explosion in the development of models, theory and computational algorithms for "big data" analysis. In particular, distributed computing has served as a natural and dominating paradigm for statistical inference. However, the existing literature on parallel inference almost exclusively focuses on Euclidean data and parameters. While this assumption is valid for many applications, it is increasingly more common to encounter problems where the data or the parameters lie on a non-Euclidean space, like a manifold for example. Our work aims to fill a critical gap in the literature by generalizing parallel inference algorithms to optimization on manifolds. We show that our proposed algorithm is both communication efficient and carries theoretical convergence guarantees. In addition, we demonstrate the performance of our algorithm to the estimation of Fr\'echet means on simulated spherical data and the low-rank matrix completion problem over Grassmann manifolds applied to the Netflix prize data set.
Embarrassingly Parallel Inference for Gaussian Processes
Jun 13, 2018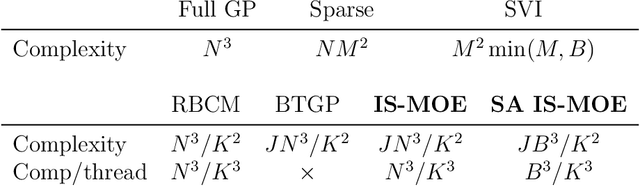
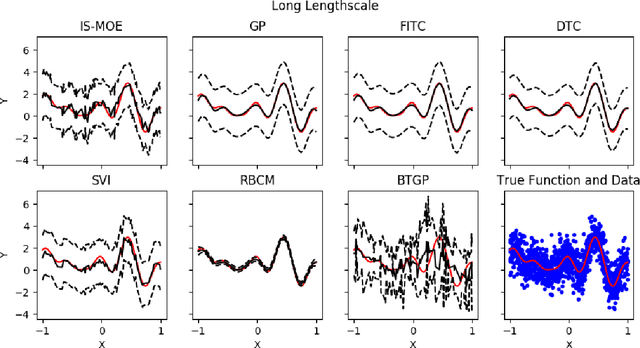
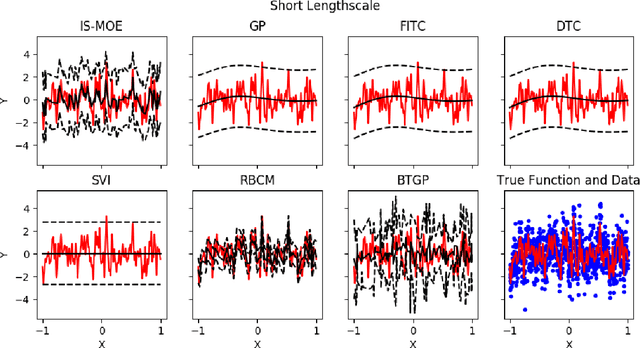
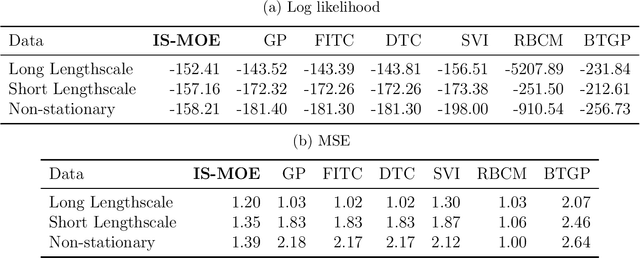
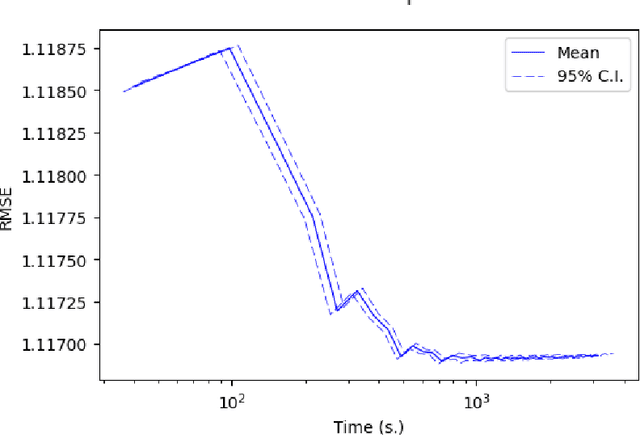
Training Gaussian process-based models typically involves an $ O(N^3)$ computational bottleneck due to inverting the covariance matrix. Popular methods for overcoming this matrix inversion problem cannot adequately model all types of latent functions, and are often not parallelizable. However, judicious choice of model structure can ameliorate this problem. A mixture-of-experts model that uses a mixture of $K$ Gaussian processes offers modeling flexibility and opportunities for scalable inference. Our embarassingly parallel algorithm combines low-dimensional matrix inversions with importance sampling to yield a flexible, scalable mixture-of-experts model that offers comparable performance to Gaussian process regression at a much lower computational cost.
Robust and Parallel Bayesian Model Selection
Mar 22, 2018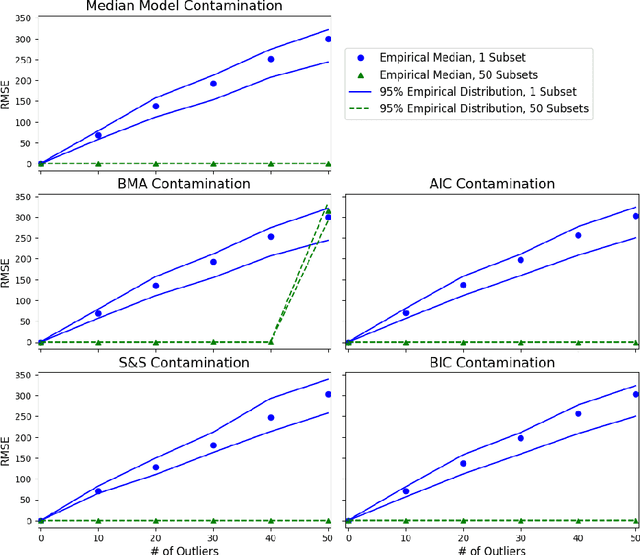
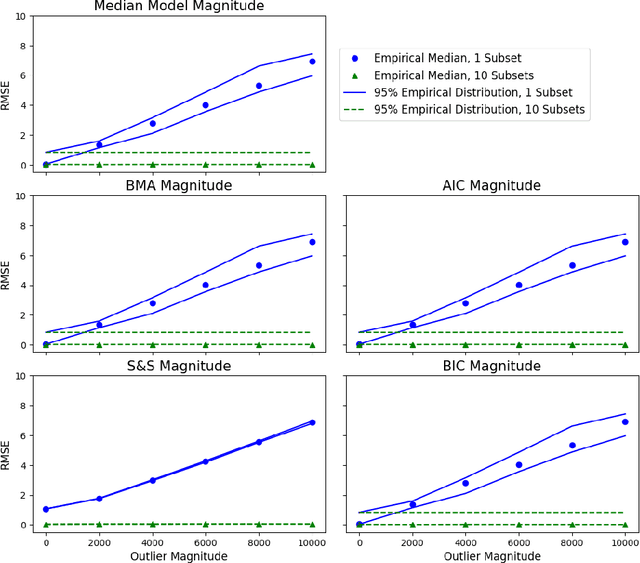
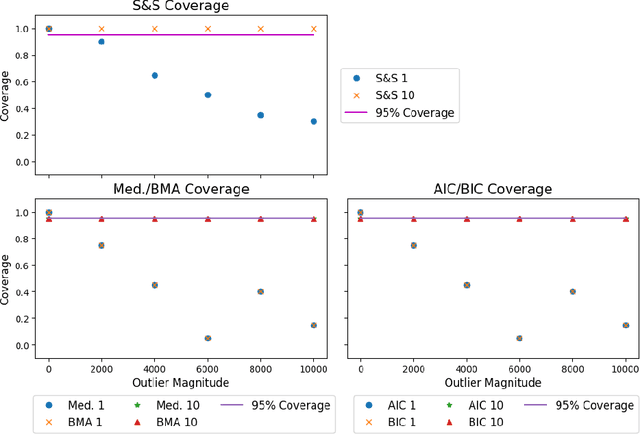
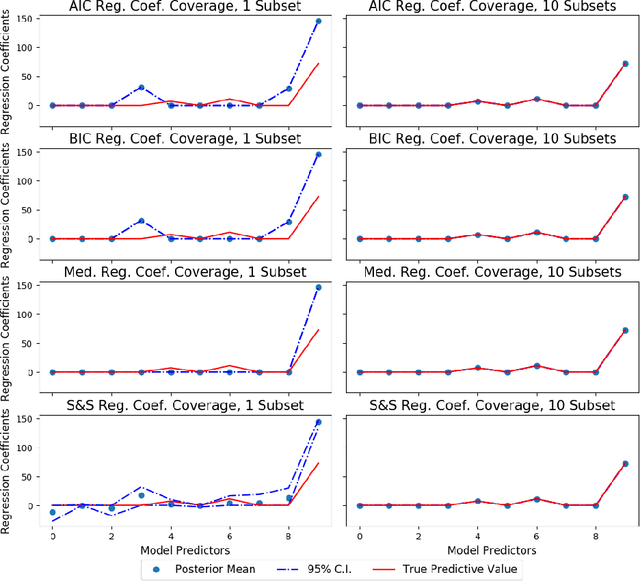
Effective and accurate model selection is an important problem in modern data analysis. One of the major challenges is the computational burden required to handle large data sets that cannot be stored or processed on one machine. Another challenge one may encounter is the presence of outliers and contaminations that damage the inference quality. The parallel "divide and conquer" model selection strategy divides the observations of the full data set into roughly equal subsets and perform inference and model selection independently on each subset. After local subset inference, this method aggregates the posterior model probabilities or other model/variable selection criteria to obtain a final model by using the notion of geometric median. This approach leads to improved concentration in finding the "correct" model and model parameters and also is provably robust to outliers and data contamination.
Accelerated Inference for Latent Variable Models
Nov 06, 2017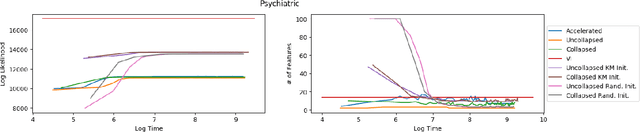
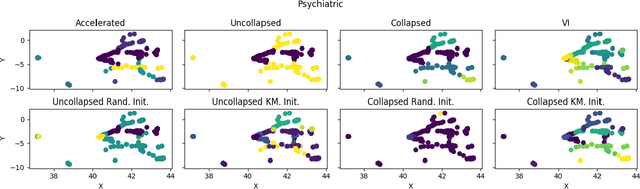
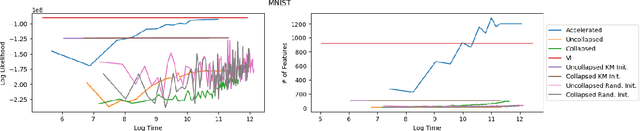
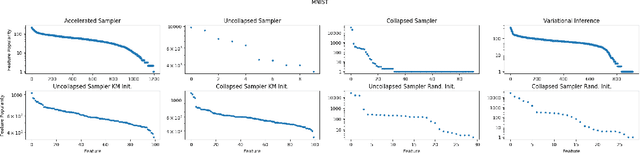
Inference of latent feature models in the Bayesian nonparametric setting is generally difficult, especially in high dimensional settings, because it usually requires proposing features from some prior distribution. In special cases, where the integration is tractable, we could sample feature assignments according to a predictive likelihood. However, this still may not be efficient in high dimensions. We present a novel method to accelerate the mixing of latent variable model inference by proposing feature locations from the data, as opposed to the prior. This sampling method is efficient for proper mixing of the Markov chain Monte Carlo sampler, computationally attractive because this method can be performed in parallel, and is theoretically guaranteed to converge to the posterior distribution as its limiting distribution.