 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine with Short-Term, Episodic, and Semantic Memory Systems
Dec 05, 2022Inspired by the cognitive science theory of the explicit human memory systems, we have modeled an agent with short-term, episodic, and semantic memory systems, each of which is modeled with a knowledge graph. To evaluate this system and analyze the behavior of this agent, we designed and released our own reinforcement learning agent environment, "the Room", where an agent has to learn how to encode, store, and retrieve memories to maximize its return by answering questions. We show that our deep Q-learning based agent successfully learns whether a short-term memory should be forgotten, or rather be stored in the episodic or semantic memory systems. Our experiments indicate that an agent with human-like memory systems can outperform an agent without this memory structure in the environment.
Prompting as Probing: Using Language Models for Knowledge Base Construction
Aug 25, 2022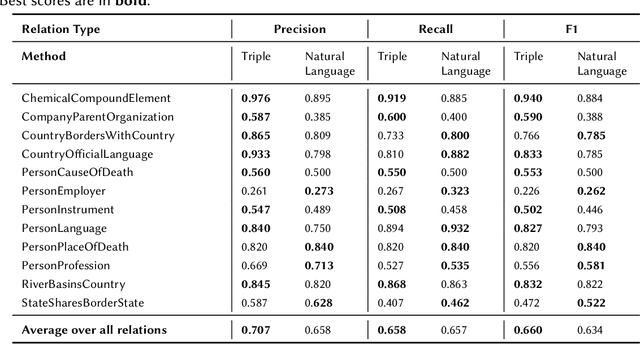
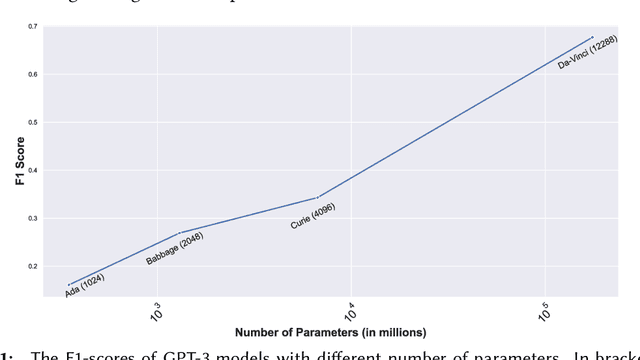
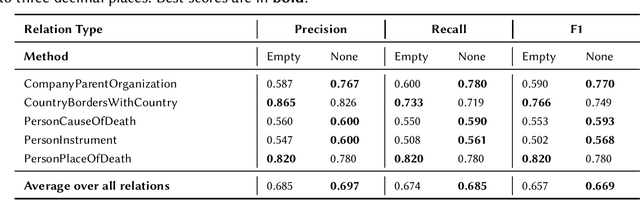
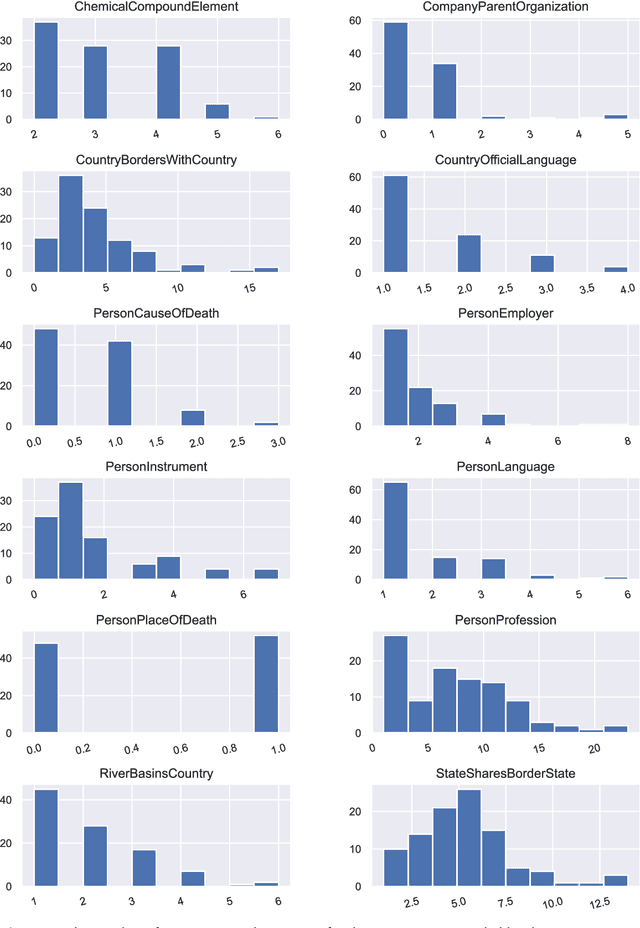
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.
QAGCN: A Graph Convolutional Network-based Multi-Relation Question Answering System
Jun 03, 2022
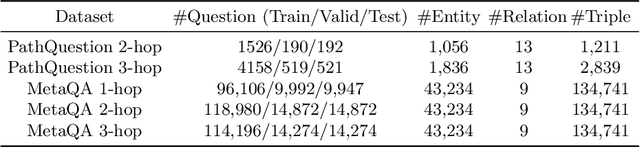
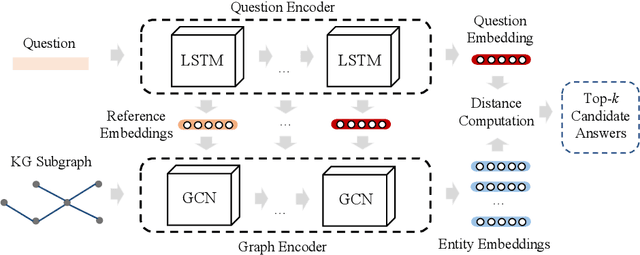
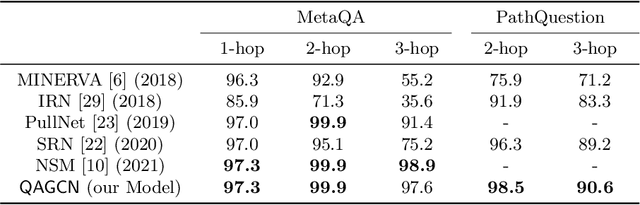
Answering multi-relation questions over knowledge graphs is a challenging task as it requires multi-step reasoning over a huge number of possible paths. Reasoning-based methods with complex reasoning mechanisms, such as reinforcement learning-based sequential decision making, have been regarded as the default pathway for this task. However, these mechanisms are difficult to implement and train, which hampers their reproducibility and transferability to new domains. In this paper, we propose QAGCN - a simple but effective and novel model that leverages attentional graph convolutional networks that can perform multi-step reasoning during the encoding of knowledge graphs. As a consequence, complex reasoning mechanisms are avoided. In addition, to improve efficiency, we retrieve answers using highly-efficient embedding computations and, for better interpretability, we extract interpretable paths for returned answers. On widely adopted benchmark datasets, the proposed model has been demonstrated competitive against state-of-the-art methods that rely on complex reasoning mechanisms. We also conducted extensive experiments to scrutinize the efficiency and contribution of each component of our model.
A Machine With Human-Like Memory Systems
Apr 04, 2022
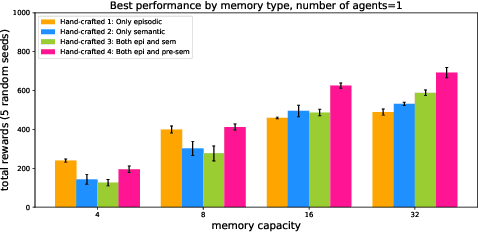
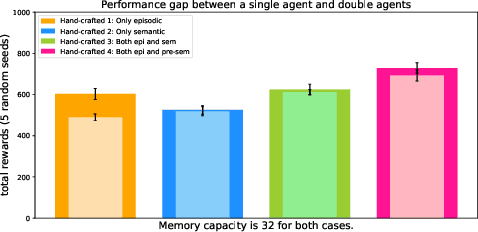
Inspired by the cognitive science theory, we explicitly model an agent with both semantic and episodic memory systems, and show that it is better than having just one of the two memory systems. In order to show this, we have designed and released our own challenging environment, "the Room", compatible with OpenAI Gym, where an agent has to properly learn how to encode, store, and retrieve memories to maximize its rewards. The Room environment allows for a hybrid intelligence setup where machines and humans can collaborate. We show that two agents collaborating with each other results in better performance than one agent acting alone. We have open-sourced our code and models at https://github.com/tae898/explicit-memory.
Scaling R-GCN Training with Graph Summarization
Mar 21, 2022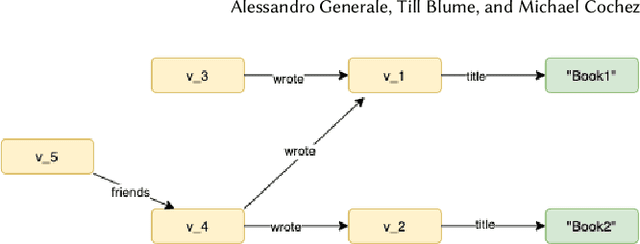


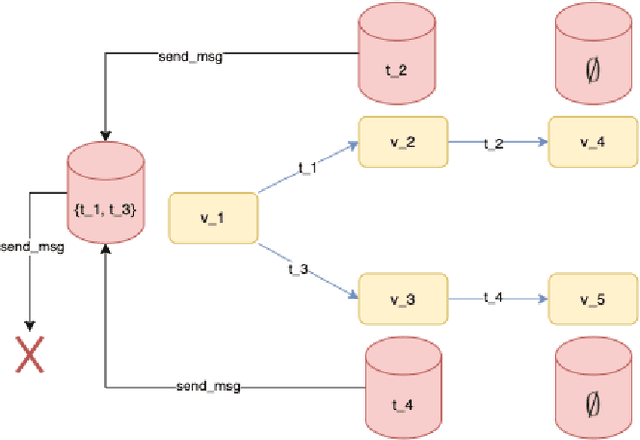
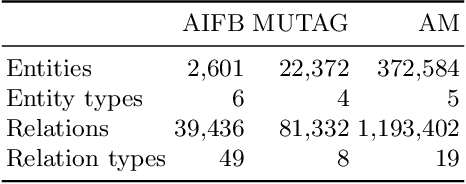
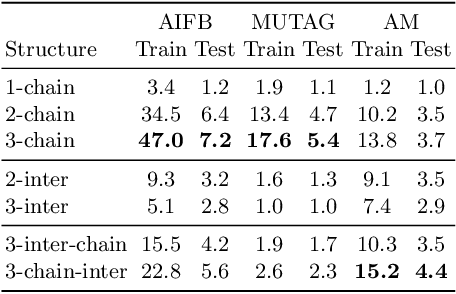
Training of Relational Graph Convolutional Networks (R-GCN) is a memory intense task. The amount of gradient information that needs to be stored during training for real-world graphs is often too large for the amount of memory available on most GPUs. In this work, we experiment with the use of graph summarization techniques to compress the graph and hence reduce the amount of memory needed. After training the R-GCN on the graph summary, we transfer the weights back to the original graph and attempt to perform inference on it. We obtain reasonable results on the AIFB, MUTAG and AM datasets. Our experiments show that training on the graph summary can yield a comparable or higher accuracy to training on the original graphs.Furthermore, if we take the time to compute the summary out of the equation, we observe that the smaller graph representations obtained with graph summarization methods reduces the computational overhead. However, further experiments are needed to evaluate additional graph summary models and whether our findings also holds true for very large graphs.
Updating Embeddings for Dynamic Knowledge Graphs
Sep 22, 2021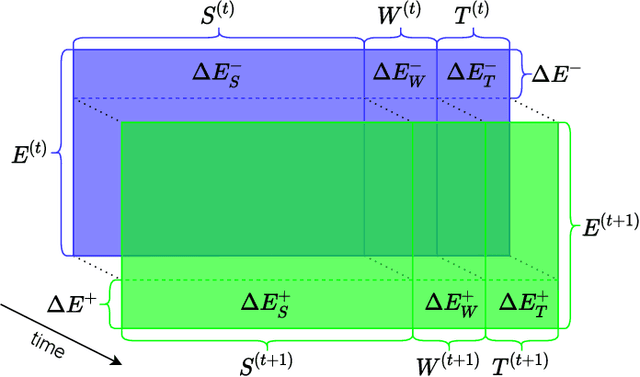
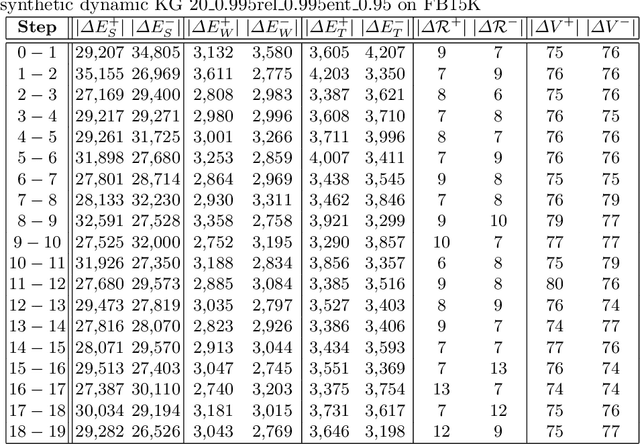
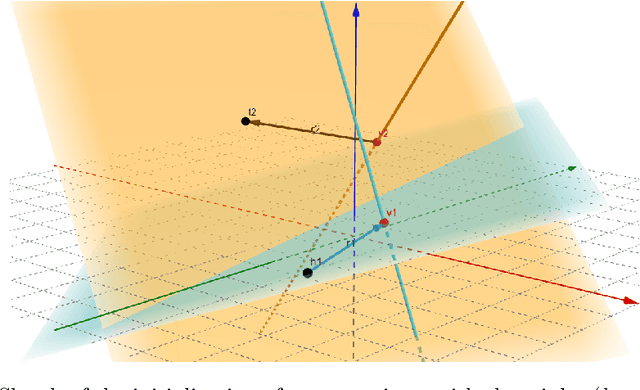
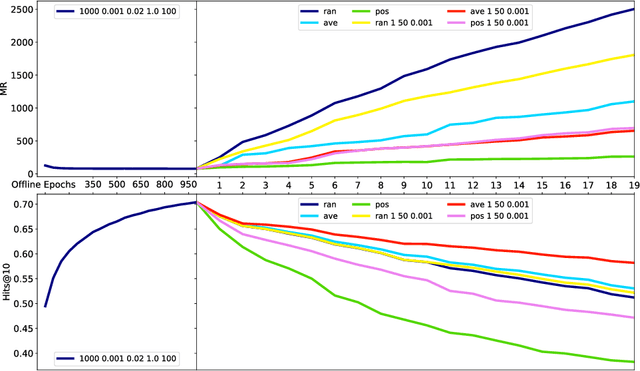
Data in Knowledge Graphs often represents part of the current state of the real world. Thus, to stay up-to-date the graph data needs to be updated frequently. To utilize information from Knowledge Graphs, many state-of-the-art machine learning approaches use embedding techniques. These techniques typically compute an embedding, i.e., vector representations of the nodes as input for the main machine learning algorithm. If a graph update occurs later on -- specifically when nodes are added or removed -- the training has to be done all over again. This is undesirable, because of the time it takes and also because downstream models which were trained with these embeddings have to be retrained if they change significantly. In this paper, we investigate embedding updates that do not require full retraining and evaluate them in combination with various embedding models on real dynamic Knowledge Graphs covering multiple use cases. We study approaches that place newly appearing nodes optimally according to local information, but notice that this does not work well. However, we find that if we continue the training of the old embedding, interleaved with epochs during which we only optimize for the added and removed parts, we obtain good results in terms of typical metrics used in link prediction. This performance is obtained much faster than with a complete retraining and hence makes it possible to maintain embeddings for dynamic Knowledge Graphs.
Query Embedding on Hyper-relational Knowledge Graphs
Jun 17, 2021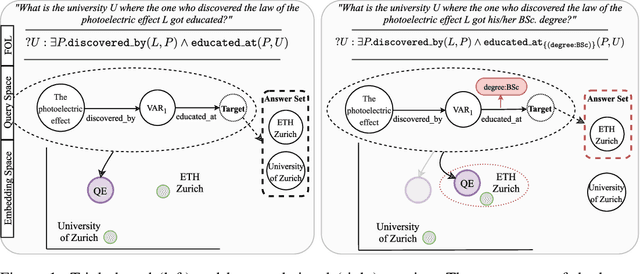
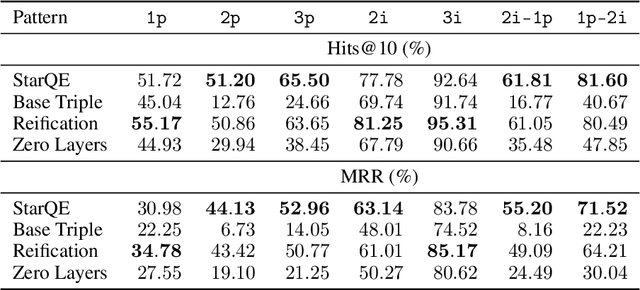

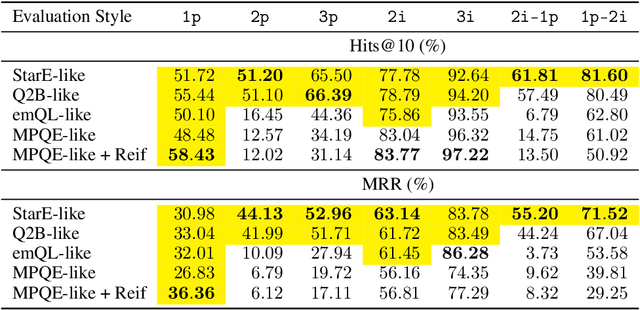
Multi-hop logical reasoning is an established problem in the field of representation learning on knowledge graphs (KGs). It subsumes both one-hop link prediction as well as other more complex types of logical queries. Existing algorithms operate only on classical, triple-based graphs, whereas modern KGs often employ a hyper-relational modeling paradigm. In this paradigm, typed edges may have several key-value pairs known as qualifiers that provide fine-grained context for facts. In queries, this context modifies the meaning of relations, and usually reduces the answer set. Hyper-relational queries are often observed in real-world KG applications, and existing approaches for approximate query answering cannot make use of qualifier pairs. In this work, we bridge this gap and extend the multi-hop reasoning problem to hyper-relational KGs allowing to tackle this new type of complex queries. Building upon recent advancements in Graph Neural Networks and query embedding techniques, we study how to embed and answer hyper-relational conjunctive queries. Besides that, we propose a method to answer such queries and demonstrate in our experiments that qualifiers improve query answering on a diverse set of query patterns.
Secure Evaluation of Knowledge Graph Merging Gain
Feb 26, 2021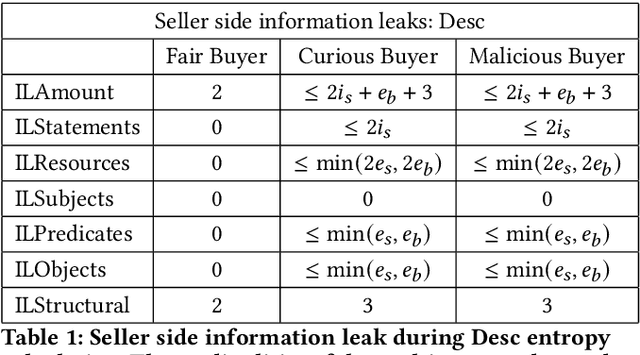
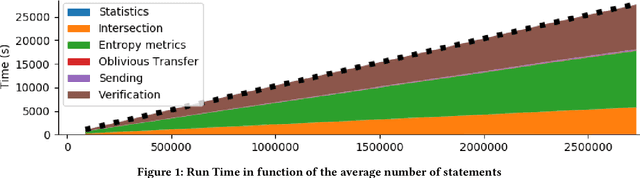
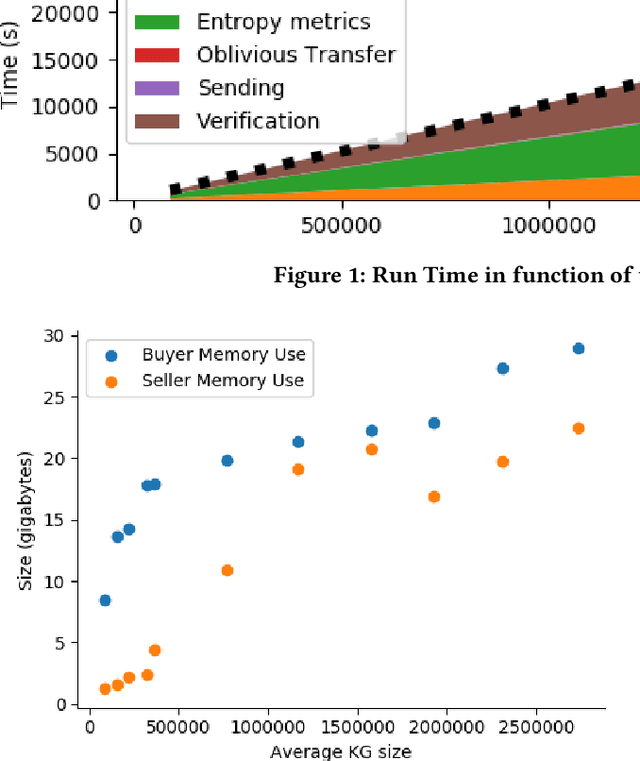
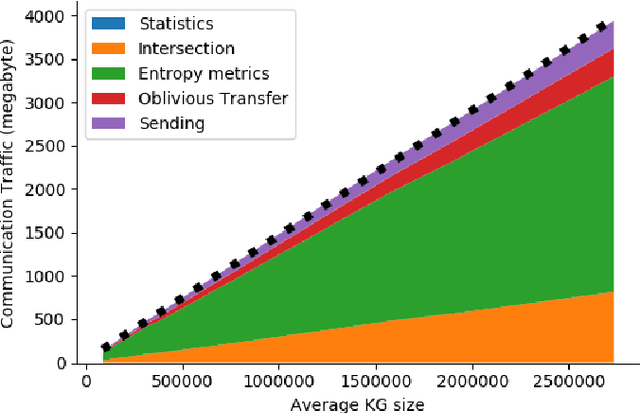
Finding out the differences and commonalities between the knowledge of two parties is an important task. Such a comparison becomes necessary, when one party wants to determine how much it is worth to acquire the knowledge of the second party, or similarly when two parties try to determine, whether a collaboration could be beneficial. When these two parties cannot trust each other (for example, due to them being competitors) performing such a comparison is challenging as neither of them would be willing to share any of their assets. This paper addresses this problem for knowledge graphs, without a need for non-disclosure agreements nor a third party during the protocol. During the protocol, the intersection between the two knowledge graphs is determined in a privacy preserving fashion. This is followed by the computation of various metrics, which give an indication of the potential gain from obtaining the other parties knowledge graph, while still keeping the actual knowledge graph contents secret. The protocol makes use of blind signatures and (counting) Bloom filters to reduce the amount of leaked information. Finally, the party who wants to obtain the other's knowledge graph can get a part of such in a way that neither party is able to know beforehand which parts of the graph are obtained (i.e., they cannot choose to only get or share the good parts). After inspection of the quality of this part, the Buyer can decide to proceed with the transaction. The analysis of the protocol indicates that the developed protocol is secure against malicious participants. Further experimental analysis shows that the resource consumption scales linear with the number of statements in the knowledge graph.
Approximate Knowledge Graph Query Answering: From Ranking to Binary Classification
Feb 22, 2021
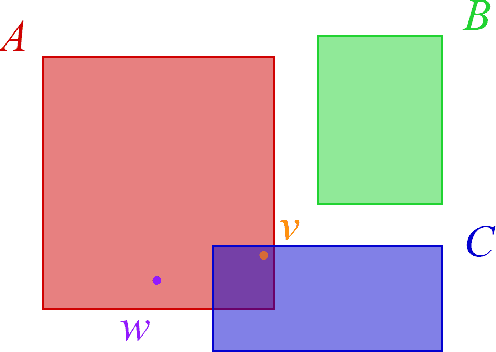
Large, heterogeneous datasets are characterized by missing or even erroneous information. This is more evident when they are the product of community effort or automatic fact extraction methods from external sources, such as text. A special case of the aforementioned phenomenon can be seen in knowledge graphs, where this mostly appears in the form of missing or incorrect edges and nodes. Structured querying on such incomplete graphs will result in incomplete sets of answers, even if the correct entities exist in the graph, since one or more edges needed to match the pattern are missing. To overcome this problem, several algorithms for approximate structured query answering have been proposed. Inspired by modern Information Retrieval metrics, these algorithms produce a ranking of all entities in the graph, and their performance is further evaluated based on how high in this ranking the correct answers appear. In this work we take a critical look at this way of evaluation. We argue that performing a ranking-based evaluation is not sufficient to assess methods for complex query answering. To solve this, we introduce Message Passing Query Boxes (MPQB), which takes binary classification metrics back into use and shows the effect this has on the recently proposed query embedding method MPQE.
Complex Query Answering with Neural Link Predictors
Nov 06, 2020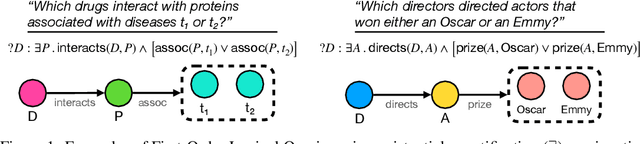
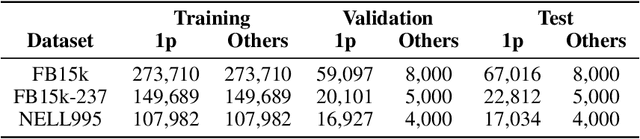

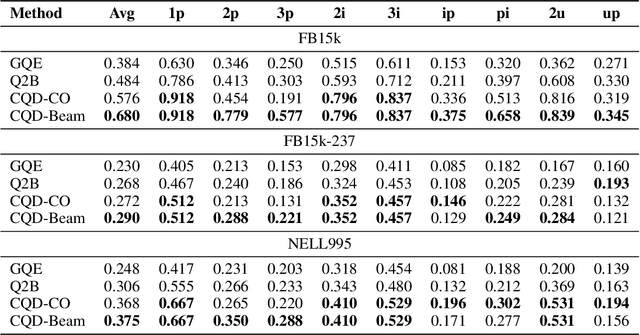
Neural link predictors are immensely useful for identifying missing edges in large scale Knowledge Graphs. However, it is still not clear how to use these models for answering more complex queries that arise in a number of domains, such as queries using logical conjunctions, disjunctions, and existential quantifiers, while accounting for missing edges. In this work, we propose a framework for efficiently answering complex queries on incomplete Knowledge Graphs. We translate each query into an end-to-end differentiable objective, where the truth value of each atom is computed by a pre-trained neural link predictor. We then analyse two solutions to the optimisation problem, including gradient-based and combinatorial search. In our experiments, the proposed approach produces more accurate results than state-of-the-art methods -- black-box neural models trained on millions of generated queries -- without the need of training on a large and diverse set of complex queries. Using orders of magnitude less training data, we obtain relative improvements ranging from 8% up to 40% in Hits@3 across different knowledge graphs containing factual information. Finally, we demonstrate that it is possible to explain the outcome of our model in terms of the intermediate solutions identified for each of the complex query atoms.