 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Knowledge Graph Query Answering: From Ranking to Binary Classification
Paper and Code
Feb 22, 2021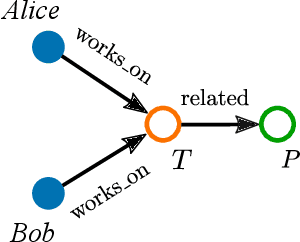
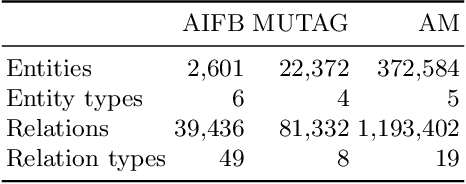
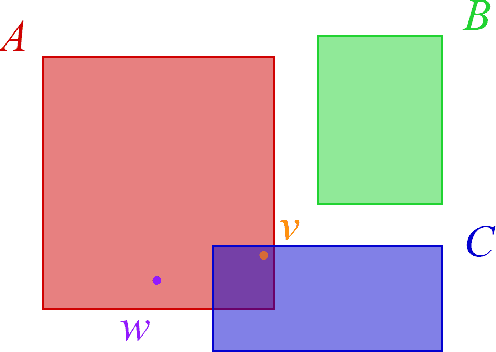
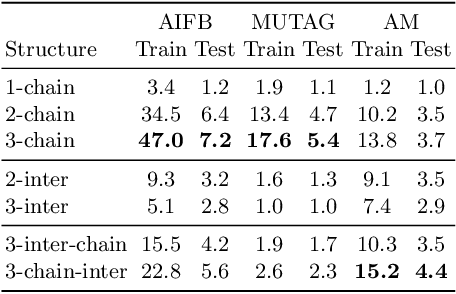
Large, heterogeneous datasets are characterized by missing or even erroneous information. This is more evident when they are the product of community effort or automatic fact extraction methods from external sources, such as text. A special case of the aforementioned phenomenon can be seen in knowledge graphs, where this mostly appears in the form of missing or incorrect edges and nodes. Structured querying on such incomplete graphs will result in incomplete sets of answers, even if the correct entities exist in the graph, since one or more edges needed to match the pattern are missing. To overcome this problem, several algorithms for approximate structured query answering have been proposed. Inspired by modern Information Retrieval metrics, these algorithms produce a ranking of all entities in the graph, and their performance is further evaluated based on how high in this ranking the correct answers appear. In this work we take a critical look at this way of evaluation. We argue that performing a ranking-based evaluation is not sufficient to assess methods for complex query answering. To solve this, we introduce Message Passing Query Boxes (MPQB), which takes binary classification metrics back into use and shows the effect this has on the recently proposed query embedding method MPQE.